 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMWIRSTD: A MWIR Small Target Detection Dataset
Jun 12, 2024

This paper presents a novel mid-wave infrared (MWIR) small target detection dataset (MWIRSTD) comprising 14 video sequences containing approximately 1053 images with annotated targets of three distinct classes of small objects. Captured using cooled MWIR imagers, the dataset offers a unique opportunity for researchers to develop and evaluate state-of-the-art methods for small object detection in realistic MWIR scenes. Unlike existing datasets, which primarily consist of uncooled thermal images or synthetic data with targets superimposed onto the background or vice versa, MWIRSTD provides authentic MWIR data with diverse targets and environments. Extensive experiments on various traditional methods and deep learning-based techniques for small target detection are performed on the proposed dataset, providing valuable insights into their efficacy. The dataset and code are available at https://github.com/avinres/MWIRSTD.
WROOM: An Autonomous Driving Approach for Off-Road Navigation
Apr 12, 2024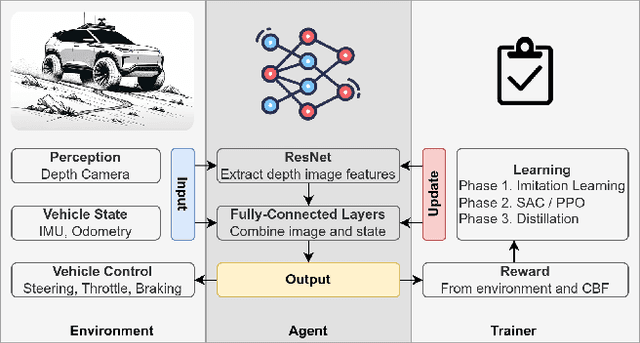



Off-road navigation is a challenging problem both at the planning level to get a smooth trajectory and at the control level to avoid flipping over, hitting obstacles, or getting stuck at a rough patch. There have been several recent works using classical approaches involving depth map prediction followed by smooth trajectory planning and using a controller to track it. We design an end-to-end reinforcement learning (RL) system for an autonomous vehicle in off-road environments using a custom-designed simulator in the Unity game engine. We warm-start the agent by imitating a rule-based controller and utilize Proximal Policy Optimization (PPO) to improve the policy based on a reward that incorporates Control Barrier Functions (CBF), facilitating the agent's ability to generalize effectively to real-world scenarios. The training involves agents concurrently undergoing domain-randomized trials in various environments. We also propose a novel simulation environment to replicate off-road driving scenarios and deploy our proposed approach on a real buggy RC car. Videos and additional results: https://sites.google.com/view/wroom-utd/home
CBGT-Net: A Neuromimetic Architecture for Robust Classification of Streaming Data
Mar 24, 2024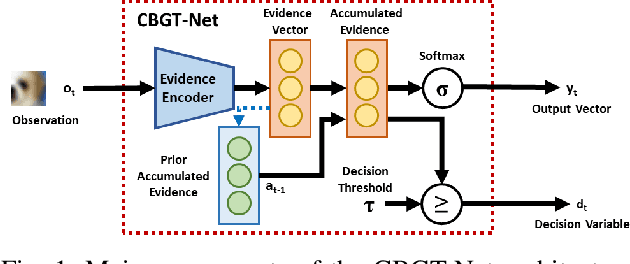
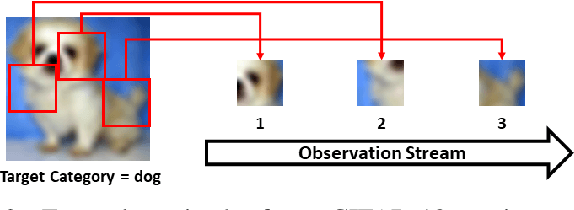
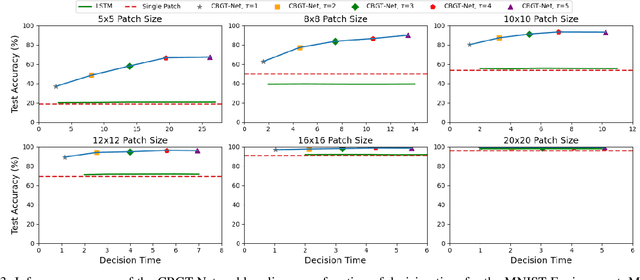
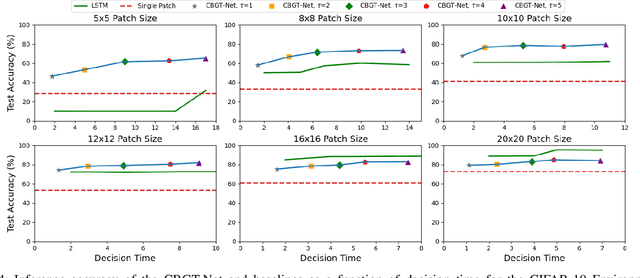
This paper describes CBGT-Net, a neural network model inspired by the cortico-basal ganglia-thalamic (CBGT) circuits found in mammalian brains. Unlike traditional neural network models, which either generate an output for each provided input, or an output after a fixed sequence of inputs, the CBGT-Net learns to produce an output after a sufficient criteria for evidence is achieved from a stream of observed data. For each observation, the CBGT-Net generates a vector that explicitly represents the amount of evidence the observation provides for each potential decision, accumulates the evidence over time, and generates a decision when the accumulated evidence exceeds a pre-defined threshold. We evaluate the proposed model on two image classification tasks, where models need to predict image categories based on a stream of small patches extracted from the image. We show that the CBGT-Net provides improved accuracy and robustness compared to models trained to classify from a single patch, and models leveraging an LSTM layer to classify from a fixed sequence length of patches.
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
AnaloBench: Benchmarking the Identification of Abstract and Long-context Analogies
Feb 19, 2024Humans regularly engage in analogical thinking, relating personal experiences to current situations ($X$ is analogous to $Y$ because of $Z$). Analogical thinking allows humans to solve problems in creative ways, grasp difficult concepts, and articulate ideas more effectively. Can language models (LMs) do the same? To answer this question, we propose ANALOBENCH, a benchmark to determine analogical reasoning ability in LMs. Our benchmarking approach focuses on aspects of this ability that are common among humans: (i) recalling related experiences from a large amount of information, and (ii) applying analogical reasoning to complex and lengthy scenarios. We test a broad collection of proprietary models (e.g., GPT family, Claude V2) and open source models such as LLaMA2. As in prior results, scaling up LMs results in some performance boosts. Surprisingly, scale offers minimal gains when, (i) analogies involve lengthy scenarios, or (ii) recalling relevant scenarios from a large pool of information, a process analogous to finding a needle in a haystack. We hope these observations encourage further research in this field.
GoalNet: Inferring Conjunctive Goal Predicates from Human Plan Demonstrations for Robot Instruction Following
May 14, 2022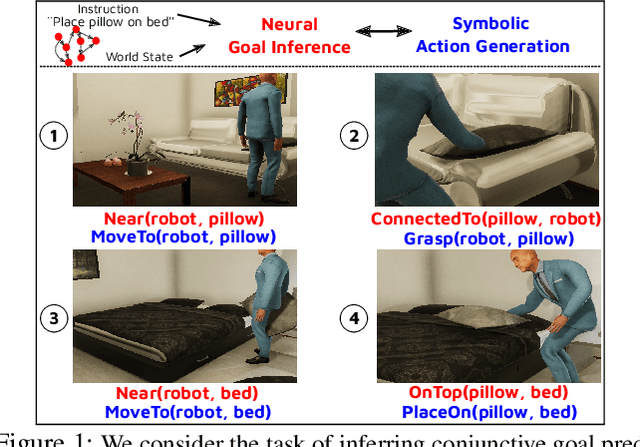

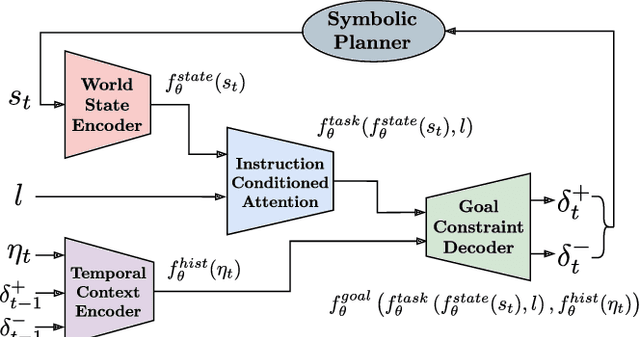
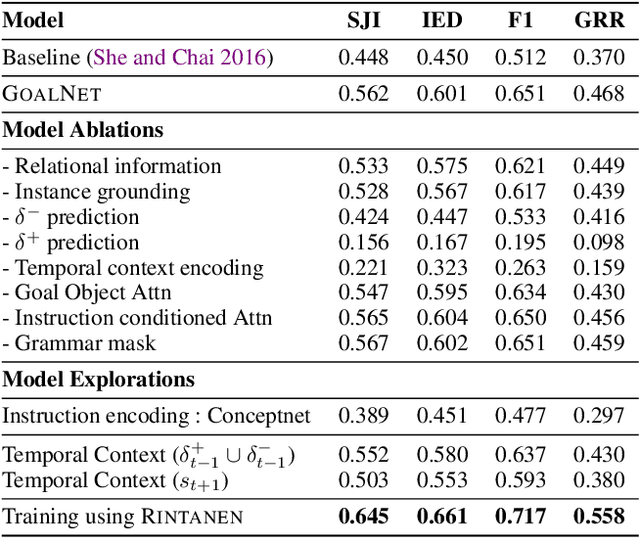
Our goal is to enable a robot to learn how to sequence its actions to perform tasks specified as natural language instructions, given successful demonstrations from a human partner. The ability to plan high-level tasks can be factored as (i) inferring specific goal predicates that characterize the task implied by a language instruction for a given world state and (ii) synthesizing a feasible goal-reaching action-sequence with such predicates. For the former, we leverage a neural network prediction model, while utilizing a symbolic planner for the latter. We introduce a novel neuro-symbolic model, GoalNet, for contextual and task dependent inference of goal predicates from human demonstrations and linguistic task descriptions. GoalNet combines (i) learning, where dense representations are acquired for language instruction and the world state that enables generalization to novel settings and (ii) planning, where the cause-effect modeling by the symbolic planner eschews irrelevant predicates facilitating multi-stage decision making in large domains. GoalNet demonstrates a significant improvement (51%) in the task completion rate in comparison to a state-of-the-art rule-based approach on a benchmark data set displaying linguistic variations, particularly for multi-stage instructions.