 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreScience: A Benchmark for Forecasting Scientific Contributions
Feb 24, 2026Can AI systems trained on the scientific record up to a fixed point in time forecast the scientific advances that follow? Such a capability could help researchers identify collaborators and impactful research directions, and anticipate which problems and methods will become central next. We introduce PreScience -- a scientific forecasting benchmark that decomposes the research process into four interdependent generative tasks: collaborator prediction, prior work selection, contribution generation, and impact prediction. PreScience is a carefully curated dataset of 98K recent AI-related research papers, featuring disambiguated author identities, temporally aligned scholarly metadata, and a structured graph of companion author publication histories and citations spanning 502K total papers. We develop baselines and evaluations for each task, including LACERScore, a novel LLM-based measure of contribution similarity that outperforms previous metrics and approximates inter-annotator agreement. We find substantial headroom remains in each task -- e.g. in contribution generation, frontier LLMs achieve only moderate similarity to the ground-truth (GPT-5, averages 5.6 on a 1-10 scale). When composed into a 12-month end-to-end simulation of scientific production, the resulting synthetic corpus is systematically less diverse and less novel than human-authored research from the same period.
Because we have LLMs, we Can and Should Pursue Agentic Interpretability
Jun 13, 2025The era of Large Language Models (LLMs) presents a new opportunity for interpretability--agentic interpretability: a multi-turn conversation with an LLM wherein the LLM proactively assists human understanding by developing and leveraging a mental model of the user, which in turn enables humans to develop better mental models of the LLM. Such conversation is a new capability that traditional `inspective' interpretability methods (opening the black-box) do not use. Having a language model that aims to teach and explain--beyond just knowing how to talk--is similar to a teacher whose goal is to teach well, understanding that their success will be measured by the student's comprehension. While agentic interpretability may trade off completeness for interactivity, making it less suitable for high-stakes safety situations with potentially deceptive models, it leverages a cooperative model to discover potentially superhuman concepts that can improve humans' mental model of machines. Agentic interpretability introduces challenges, particularly in evaluation, due to what we call `human-entangled-in-the-loop' nature (humans responses are integral part of the algorithm), making the design and evaluation difficult. We discuss possible solutions and proxy goals. As LLMs approach human parity in many tasks, agentic interpretability's promise is to help humans learn the potentially superhuman concepts of the LLMs, rather than see us fall increasingly far from understanding them.
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Apr 15, 2025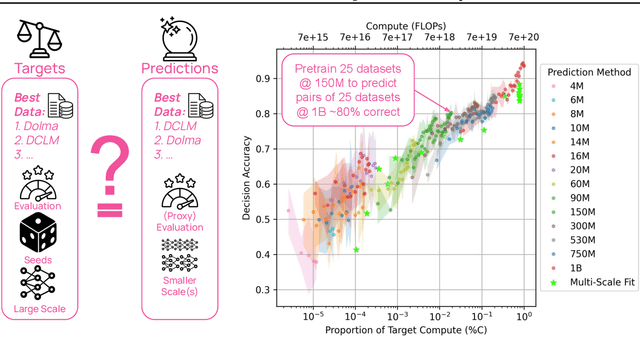
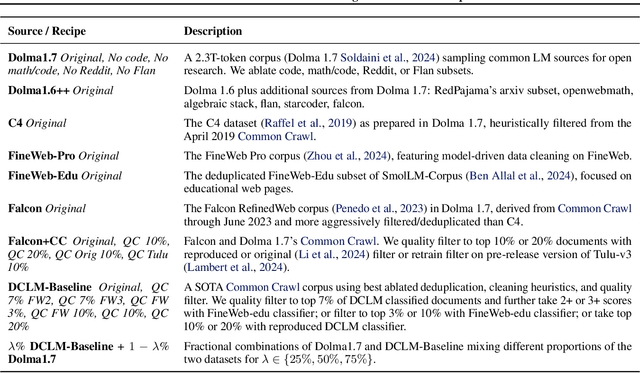
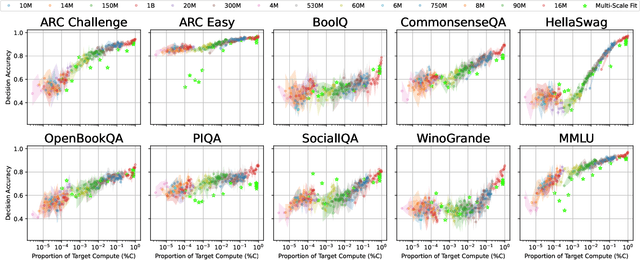
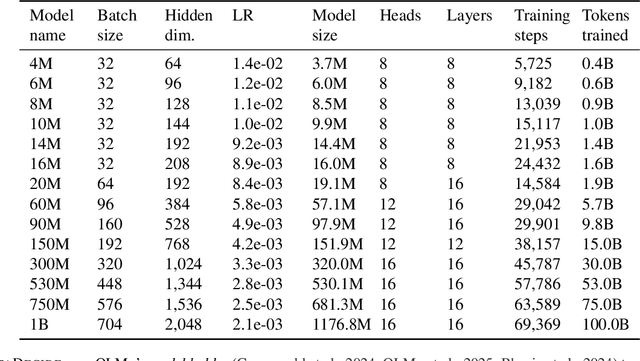
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide -- the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
From Models to Microtheories: Distilling a Model's Topical Knowledge for Grounded Question Answering
Dec 24, 2024



Recent reasoning methods (e.g., chain-of-thought, entailment reasoning) help users understand how language models (LMs) answer a single question, but they do little to reveal the LM's overall understanding, or "theory," about the question's topic, making it still hard to trust the model. Our goal is to materialize such theories - here called microtheories (a linguistic analog of logical microtheories) - as a set of sentences encapsulating an LM's core knowledge about a topic. These statements systematically work together to entail answers to a set of questions to both engender trust and improve performance. Our approach is to first populate a knowledge store with (model-generated) sentences that entail answers to training questions and then distill those down to a core microtheory that is concise, general, and non-redundant. We show that, when added to a general corpus (e.g., Wikipedia), microtheories can supply critical, topical information not necessarily present in the corpus, improving both a model's ability to ground its answers to verifiable knowledge (i.e., show how answers are systematically entailed by documents in the corpus, fully grounding up to +8% more answers), and the accuracy of those grounded answers (up to +8% absolute). We also show that, in a human evaluation in the medical domain, our distilled microtheories contain a significantly higher concentration of topically critical facts than the non-distilled knowledge store. Finally, we show we can quantify the coverage of a microtheory for a topic (characterized by a dataset) using a notion of $p$-relevance. Together, these suggest that microtheories are an efficient distillation of an LM's topic-relevant knowledge, that they can usefully augment existing corpora, and can provide both performance gains and an interpretable, verifiable window into the model's knowledge of a topic.
Establishing Task Scaling Laws via Compute-Efficient Model Ladders
Dec 05, 2024We develop task scaling laws and model ladders to predict the individual task performance of pretrained language models (LMs) in the overtrained setting. Standard power laws for language modeling loss cannot accurately model task performance. Therefore, we leverage a two-step prediction approach: first use model and data size to predict a task-specific loss, and then use this task loss to predict task performance. We train a set of small-scale "ladder" models, collect data points to fit the parameterized functions of the two prediction steps, and make predictions for two target models: a 7B model trained to 4T tokens and a 13B model trained to 5T tokens. Training the ladder models only costs 1% of the compute used for the target models. On four multiple-choice tasks written in ranked classification format, we can predict the accuracy of both target models within 2 points of absolute error. We have higher prediction error on four other tasks (average absolute error 6.9) and find that these are often tasks with higher variance in task metrics. We also find that using less compute to train fewer ladder models tends to deteriorate predictions. Finally, we empirically show that our design choices and the two-step approach lead to superior performance in establishing scaling laws.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024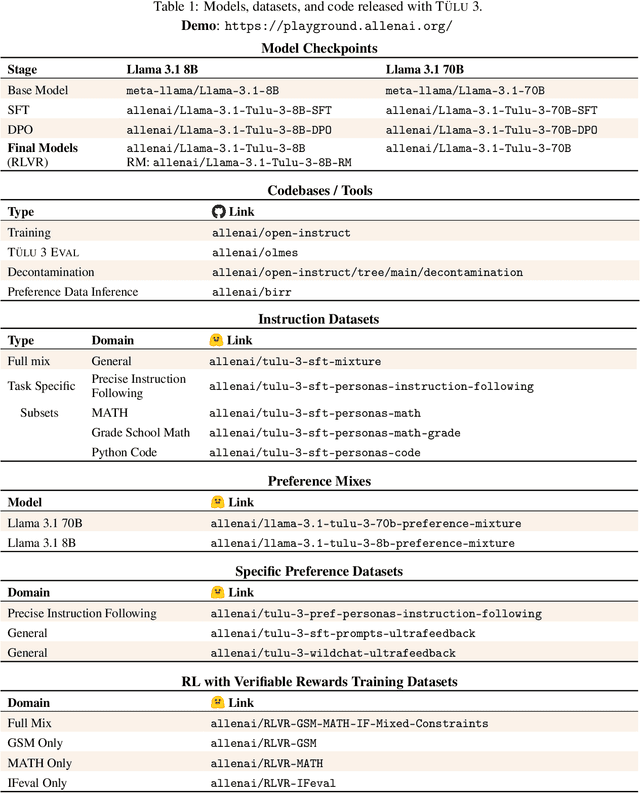



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs
Oct 17, 2024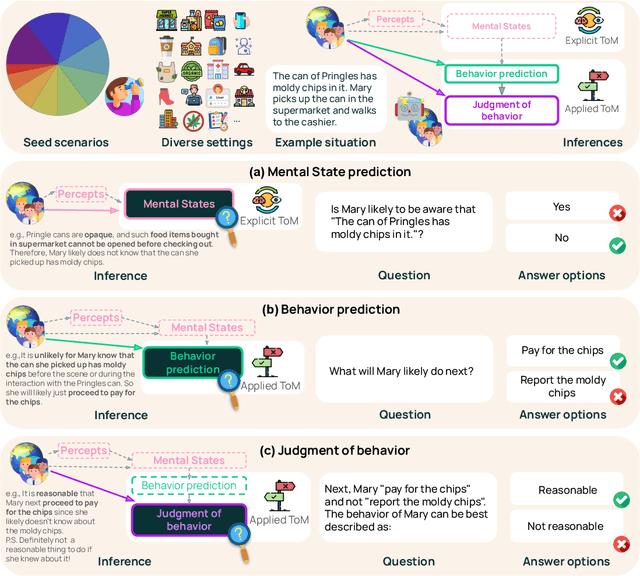

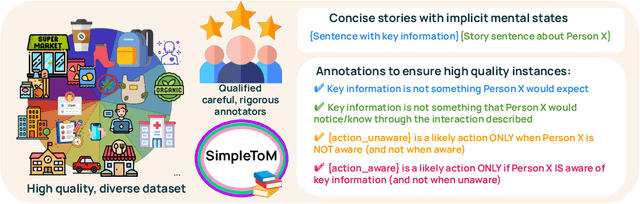
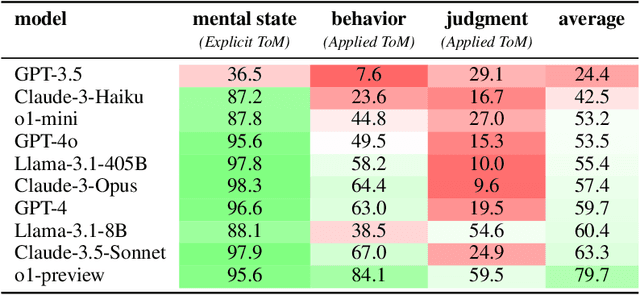
While prior work has explored whether large language models (LLMs) possess a "theory of mind" (ToM) - the ability to attribute mental states to oneself and others - there has been little work testing whether LLMs can implicitly apply such knowledge to predict behavior, or to judge whether an observed behavior is rational. Such skills are critical for appropriate interaction in social environments. We create a new dataset, SimpleTom, containing concise, diverse stories (e.g., "The can of Pringles has moldy chips in it. Mary picks up the can in the supermarket and walks to the cashier."), each with three questions that test different degrees of ToM reasoning, asking models to predict (a) mental state ("Is Mary aware of the mold?"), (b) behavior ("Will Mary pay for the chips or report the mold?"), and (c) judgment ("Mary paid for the chips. Was that reasonable?"). To our knowledge, SimpleToM is the first dataset to systematically explore downstream reasoning requiring knowledge of mental states in realistic scenarios. Our experimental results are intriguing: While most models can reliably predict mental state on our dataset (a), they often fail to correctly predict the behavior (b), and fare even worse at judging whether given behaviors are reasonable (c), despite being correctly aware of the protagonist's mental state should make such secondary predictions obvious. We further show that we can help models do better at (b) and (c) via interventions such as reminding the model of its earlier mental state answer and mental-state-specific chain-of-thought prompting, raising the action prediction accuracies (e.g., from 49.5% to 93.5% for GPT-4o) and judgment accuracies (e.g., from 15.3% to 94.7% in GPT-4o). While this shows that models can be coaxed to perform well, it requires task-specific interventions, and the natural model performances remain low, a cautionary tale for LLM deployment.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
Answer, Assemble, Ace: Understanding How Transformers Answer Multiple Choice Questions
Jul 21, 2024Multiple-choice question answering (MCQA) is a key competence of performant transformer language models that is tested by mainstream benchmarks. However, recent evidence shows that models can have quite a range of performance, particularly when the task format is diversified slightly (such as by shuffling answer choice order). In this work we ask: how do successful models perform formatted MCQA? We employ vocabulary projection and activation patching methods to localize key hidden states that encode relevant information for predicting the correct answer. We find that prediction of a specific answer symbol is causally attributed to a single middle layer, and specifically its multi-head self-attention mechanism. We show that subsequent layers increase the probability of the predicted answer symbol in vocabulary space, and that this probability increase is associated with a sparse set of attention heads with unique roles. We additionally uncover differences in how different models adjust to alternative symbols. Finally, we demonstrate that a synthetic task can disentangle sources of model error to pinpoint when a model has learned formatted MCQA, and show that an inability to separate answer symbol tokens in vocabulary space is a property of models unable to perform formatted MCQA tasks.