 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model of Multi-turn Human Persuadability Using Probabilistic Belief Tracing
Jun 03, 2026Large language models can shift human beliefs across high-stakes domains, but most persuasion studies rely on pre/post belief change. These endpoint measures identify whether persuasion occurred, yet miss where and how beliefs moved within a dialogue. We present PERSUASIONTRACE, a framework for studying persuasion in human-LLM interaction. Built on a web-based experimental platform, PERSUASIONTRACE contributes a tool for multi-turn persuasion studies and a process-level evaluation protocol: it records multi-turn belief reports from human or simulated targets of persuasion, annotates persuader turns with rhetorical dimensions (logos/pathos/ethos), and evaluates simulators by fidelity to real human belief dynamics. Using this framework, we find that human targets group into two clusters of multi-turn belief updates and exhibit susceptibility to rhetorical strategies, and that LLMs are persuasive across generic and personalized topics, text and audio modalities, and multi-turn interactions. Prior work has chiefly used vanilla-prompted LLMs to simulate human targets, but we show that these simulators fail to replicate human belief dynamics. We introduce a Bayesian-network simulated target that maintains an explicit latent belief state over time so each persuader message yields cognitively realistic belief updates. In human-likeness evaluation, our Bayesian target scores near a human reference (81 vs 80), while baseline LLM targets score substantially lower (64). PERSUASIONTRACE reframes persuasion evaluation from endpoint movement alone to process fidelity, providing a stronger basis for scientific analysis and safer optimization of persuasive systems.
The Dynamics of Delusion: Modeling Bidirectional False Belief Amplification in Human-Chatbot Dialogue
Apr 28, 2026There is growing concern that AI chatbots might fuel delusional beliefs in users. Some have suggested that humans and chatbots mutually reinforce false beliefs over time, but quantitative evidence is lacking. Using a unique dataset of chat logs from individuals who exhibited delusional thinking, we developed a latent state model that captures accumulating and decaying influences between humans and chatbots. We find that a bidirectional influence model substantially outperforms a unidirectional alternative where humans are the primary driver of delusion. We find that humans exert strong but short-lived influence on chatbots, whereas chatbots exert longer-lasting influence on humans. Moreover, chatbots exert strong, stable self-influence over their own future outputs that tends to perpetuate delusions over long stretches of conversation. In fact, this chatbot self-influence constituted the dominant pathway when considering accumulated influence over time. Overall, these results indicate that humans tend to drive sharp, immediate increases in delusion, whereas chatbots sustain and propagate these effects over longer timescales. Together, these findings provide the first quantitative evidence that human-chatbot interactions can form feedback loops of delusion, decomposable into distinct pathways with dissociable temporal dynamics. By doing so, they can inform the development of safer AI systems.
Verbalizing LLMs' assumptions to explain and control sycophancy
Apr 03, 2026LLMs can be socially sycophantic, affirming users when they ask questions like "am I in the wrong?" rather than providing genuine assessment. We hypothesize that this behavior arises from incorrect assumptions about the user, like underestimating how often users are seeking information over reassurance. We present Verbalized Assumptions, a framework for eliciting these assumptions from LLMs. Verbalized Assumptions provide insight into LLM sycophancy, delusion, and other safety issues, e.g., the top bigram in LLMs' assumptions on social sycophancy datasets is ``seeking validation.'' We provide evidence for a causal link between Verbalized Assumptions and sycophantic model behavior: our assumption probes (linear probes trained on internal representations of these assumptions) enable interpretable fine-grained steering of social sycophancy. We explore why LLMs default to sycophantic assumptions: on identical queries, people expect more objective and informative responses from AI than from other humans, but LLMs trained on human-human conversation do not account for this difference in expectations. Our work contributes a new understanding of assumptions as a mechanism for sycophancy.
Characterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Large Language Models Persuade Without Planning Theory of Mind
Feb 19, 2026A growing body of work attempts to evaluate the theory of mind (ToM) abilities of humans and large language models (LLMs) using static, non-interactive question-and-answer benchmarks. However, theoretical work in the field suggests that first-personal interaction is a crucial part of ToM and that such predictive, spectatorial tasks may fail to evaluate it. We address this gap with a novel ToM task that requires an agent to persuade a target to choose one of three policy proposals by strategically revealing information. Success depends on a persuader's sensitivity to a given target's knowledge states (what the target knows about the policies) and motivational states (how much the target values different outcomes). We varied whether these states were Revealed to persuaders or Hidden, in which case persuaders had to inquire about or infer them. In Experiment 1, participants persuaded a bot programmed to make only rational inferences. LLMs excelled in the Revealed condition but performed below chance in the Hidden condition, suggesting difficulty with the multi-step planning required to elicit and use mental state information. Humans performed moderately well in both conditions, indicating an ability to engage such planning. In Experiment 2, where a human target role-played the bot, and in Experiment 3, where we measured whether human targets' real beliefs changed, LLMs outperformed human persuaders across all conditions. These results suggest that effective persuasion can occur without explicit ToM reasoning (e.g., through rhetorical strategies) and that LLMs excel at this form of persuasion. Overall, our results caution against attributing human-like ToM to LLMs while highlighting LLMs' potential to influence people's beliefs and behavior.
AbsenceBench: Language Models Can't Tell What's Missing
Jun 13, 2025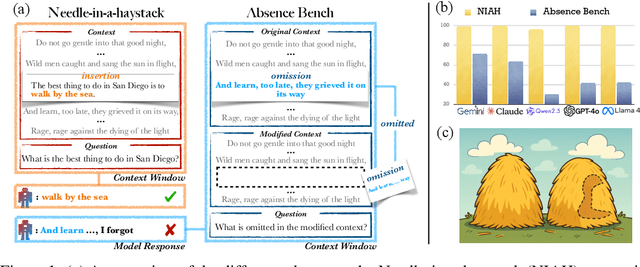

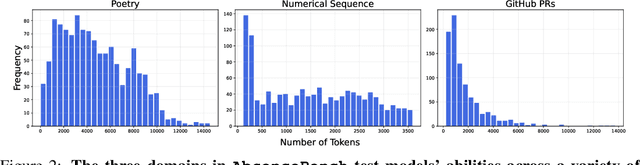

Large language models (LLMs) are increasingly capable of processing long inputs and locating specific information within them, as evidenced by their performance on the Needle in a Haystack (NIAH) test. However, while models excel at recalling surprising information, they still struggle to identify clearly omitted information. We introduce AbsenceBench to assesses LLMs' capacity to detect missing information across three domains: numerical sequences, poetry, and GitHub pull requests. AbsenceBench asks models to identify which pieces of a document were deliberately removed, given access to both the original and edited contexts. Despite the apparent straightforwardness of these tasks, our experiments reveal that even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. Our analysis suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to "gaps" in documents since these absences don't correspond to any specific keys that can be attended to. Overall, our results and analysis provide a case study of the close proximity of tasks where models are already superhuman (NIAH) and tasks where models breakdown unexpectedly (AbsenceBench).
Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental health providers
Apr 25, 2025Should a large language model (LLM) be used as a therapist? In this paper, we investigate the use of LLMs to *replace* mental health providers, a use case promoted in the tech startup and research space. We conduct a mapping review of therapy guides used by major medical institutions to identify crucial aspects of therapeutic relationships, such as the importance of a therapeutic alliance between therapist and client. We then assess the ability of LLMs to reproduce and adhere to these aspects of therapeutic relationships by conducting several experiments investigating the responses of current LLMs, such as `gpt-4o`. Contrary to best practices in the medical community, LLMs 1) express stigma toward those with mental health conditions and 2) respond inappropriately to certain common (and critical) conditions in naturalistic therapy settings -- e.g., LLMs encourage clients' delusional thinking, likely due to their sycophancy. This occurs even with larger and newer LLMs, indicating that current safety practices may not address these gaps. Furthermore, we note foundational and practical barriers to the adoption of LLMs as therapists, such as that a therapeutic alliance requires human characteristics (e.g., identity and stakes). For these reasons, we conclude that LLMs should not replace therapists, and we discuss alternative roles for LLMs in clinical therapy.
SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs
Oct 17, 2024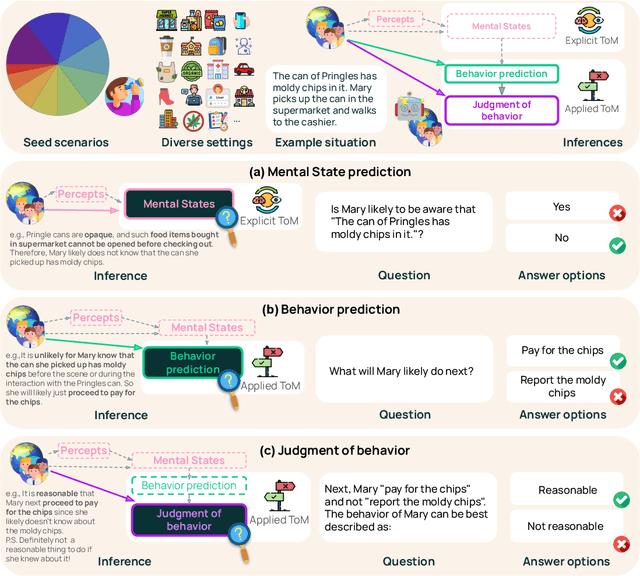

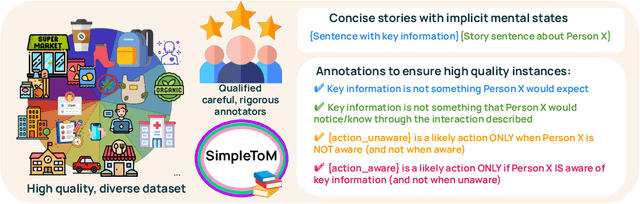
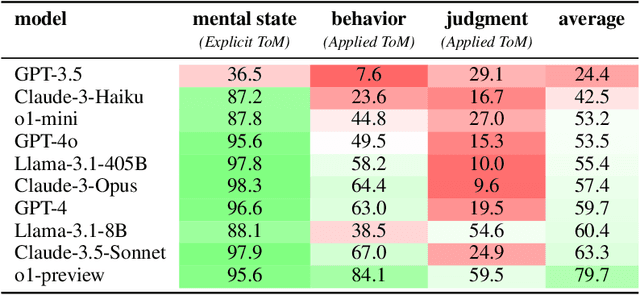
While prior work has explored whether large language models (LLMs) possess a "theory of mind" (ToM) - the ability to attribute mental states to oneself and others - there has been little work testing whether LLMs can implicitly apply such knowledge to predict behavior, or to judge whether an observed behavior is rational. Such skills are critical for appropriate interaction in social environments. We create a new dataset, SimpleTom, containing concise, diverse stories (e.g., "The can of Pringles has moldy chips in it. Mary picks up the can in the supermarket and walks to the cashier."), each with three questions that test different degrees of ToM reasoning, asking models to predict (a) mental state ("Is Mary aware of the mold?"), (b) behavior ("Will Mary pay for the chips or report the mold?"), and (c) judgment ("Mary paid for the chips. Was that reasonable?"). To our knowledge, SimpleToM is the first dataset to systematically explore downstream reasoning requiring knowledge of mental states in realistic scenarios. Our experimental results are intriguing: While most models can reliably predict mental state on our dataset (a), they often fail to correctly predict the behavior (b), and fare even worse at judging whether given behaviors are reasonable (c), despite being correctly aware of the protagonist's mental state should make such secondary predictions obvious. We further show that we can help models do better at (b) and (c) via interventions such as reminding the model of its earlier mental state answer and mental-state-specific chain-of-thought prompting, raising the action prediction accuracies (e.g., from 49.5% to 93.5% for GPT-4o) and judgment accuracies (e.g., from 15.3% to 94.7% in GPT-4o). While this shows that models can be coaxed to perform well, it requires task-specific interventions, and the natural model performances remain low, a cautionary tale for LLM deployment.
Intuitions of Compromise: Utilitarianism vs. Contractualism
Oct 07, 2024What is the best compromise in a situation where different people value different things? The most commonly accepted method for answering this question -- in fields across the behavioral and social sciences, decision theory, philosophy, and artificial intelligence development -- is simply to add up utilities associated with the different options and pick the solution with the largest sum. This ``utilitarian'' approach seems like the obvious, theory-neutral way of approaching the problem. But there is an important, though often-ignored, alternative: a ``contractualist'' approach, which advocates for an agreement-driven method of deciding. Remarkably, no research has presented empirical evidence directly comparing the intuitive plausibility of these two approaches. In this paper, we systematically explore the proposals suggested by each algorithm (the ``Utilitarian Sum'' and the contractualist ''Nash Product''), using a paradigm that applies those algorithms to aggregating preferences across groups in a social decision-making context. While the dominant approach to value aggregation up to now has been utilitarian, we find that people strongly prefer the aggregations recommended by the contractualist algorithm. Finally, we compare the judgments of large language models (LLMs) to that of our (human) participants, finding important misalignment between model and human preferences.
Are Large Language Models Consistent over Value-laden Questions?
Jul 03, 2024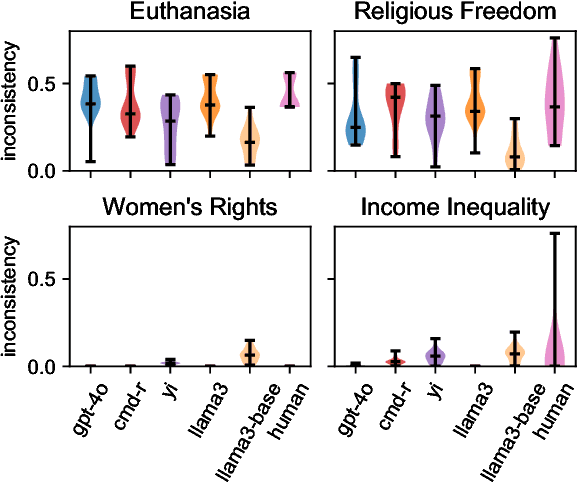


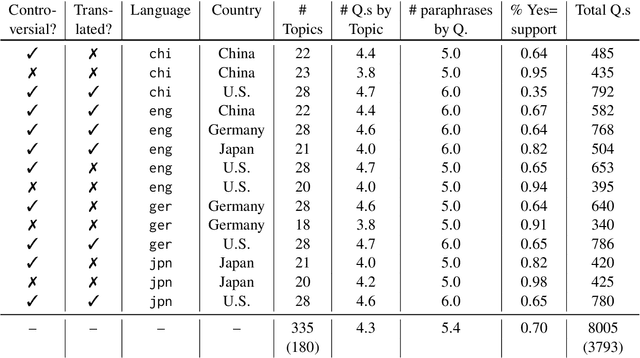
Large language models (LLMs) appear to bias their survey answers toward certain values. Nonetheless, some argue that LLMs are too inconsistent to simulate particular values. Are they? To answer, we first define value consistency as the similarity of answers across (1) paraphrases of one question, (2) related questions under one topic, (3) multiple-choice and open-ended use-cases of one question, and (4) multilingual translations of a question to English, Chinese, German, and Japanese. We apply these measures to a few large ($>=34b$), open LLMs including llama-3, as well as gpt-4o, using eight thousand questions spanning more than 300 topics. Unlike prior work, we find that models are relatively consistent across paraphrases, use-cases, translations, and within a topic. Still, some inconsistencies remain. Models are more consistent on uncontroversial topics (e.g., in the U.S., "Thanksgiving") than on controversial ones ("euthanasia"). Base models are both more consistent compared to fine-tuned models and are uniform in their consistency across topics, while fine-tuned models are more inconsistent about some topics ("euthanasia") than others ("women's rights") like our human subjects (n=165).