 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpt-ICL at LeWiDi-2025: Maximizing In-Context Signal from Rater Examples via Meta-Learning
Oct 08, 2025Many natural language processing (NLP) tasks involve subjectivity, ambiguity, or legitimate disagreement between annotators. In this paper, we outline our system for modeling human variation. Our system leverages language models' (LLMs) in-context learning abilities, along with a two-step meta-learning training procedure for 1) post-training on many datasets requiring in-context learning and 2) specializing the model via in-context meta-learning to the particular data distribution of interest. We also evaluate the performance of our system submission to the Learning With Disagreements (LeWiDi) competition, where it was the overall winner on both tasks. Additionally, we perform an ablation study to measure the importance of each system component. We find that including rater examples in-context is crucial for our system's performance, dataset-specific fine-tuning is helpful on the larger datasets, post-training on other in-context datasets is helpful on one of the competition datasets, and that performance improves with model scale.
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025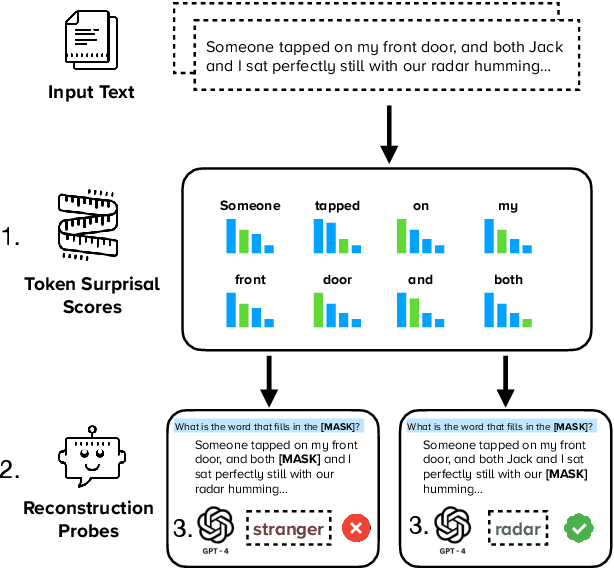

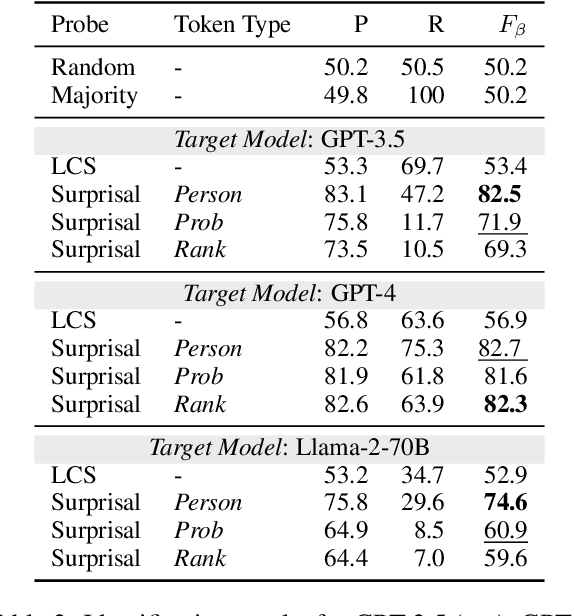
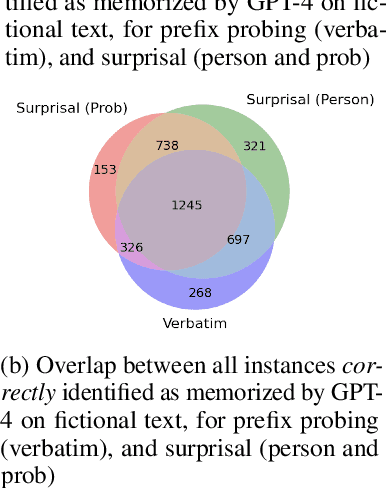
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
Can Language Models Reason about Individualistic Human Values and Preferences?
Oct 04, 2024Recent calls for pluralistic alignment emphasize that AI systems should address the diverse needs of all people. Yet, efforts in this space often require sorting people into fixed buckets of pre-specified diversity-defining dimensions (e.g., demographics, personalities, communication styles), risking smoothing out or even stereotyping the rich spectrum of individualistic variations. To achieve an authentic representation of diversity that respects individuality, we propose individualistic alignment. While individualistic alignment can take various forms, in this paper, we introduce IndieValueCatalog, a dataset transformed from the influential World Values Survey (WVS), to study language models (LMs) on the specific challenge of individualistic value reasoning. Specifically, given a sample of an individual's value-expressing statements, models are tasked with predicting their value judgments in novel cases. With IndieValueCatalog, we reveal critical limitations in frontier LMs' abilities to reason about individualistic human values with accuracies, only ranging between 55% to 65%. Moreover, our results highlight that a precise description of individualistic values cannot be approximated only via demographic information. We also identify a partiality of LMs in reasoning about global individualistic values, as measured by our proposed Value Inequity Index ({\sigma}INEQUITY). Finally, we train a series of Individualistic Value Reasoners (IndieValueReasoner) using IndieValueCatalog to enhance models' individualistic value reasoning capability, revealing new patterns and dynamics into global human values. We outline future research challenges and opportunities for advancing individualistic alignment.
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
Jun 22, 2024While existing alignment paradigms have been integral in developing large language models (LLMs), LLMs often learn an averaged human preference and struggle to model diverse preferences across cultures, demographics, and communities. We propose Modular Pluralism, a modular framework based on multi-LLM collaboration for pluralistic alignment: it "plugs into" a base LLM a pool of smaller but specialized community LMs, where models collaborate in distinct modes to flexibility support three modes of pluralism: Overton, steerable, and distributional. Modular Pluralism is uniquely compatible with black-box LLMs and offers the modular control of adding new community LMs for previously underrepresented communities. We evaluate Modular Pluralism with six tasks and four datasets featuring questions/instructions with value-laden and perspective-informed responses. Extensive experiments demonstrate that Modular Pluralism advances the three pluralism objectives across six black-box and open-source LLMs. Further analysis reveals that LLMs are generally faithful to the inputs from smaller community LLMs, allowing seamless patching by adding a new community LM to better cover previously underrepresented communities.
A Roadmap to Pluralistic Alignment
Feb 07, 2024With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also propose and formalize three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
NovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023


We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Sep 02, 2023Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.
Towards Coding Social Science Datasets with Language Models
Jun 03, 2023Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing
May 26, 2023



It is commonly perceived that the strongest language models (LMs) rely on a combination of massive scale, instruction data, and human feedback to perform specialized tasks -- e.g. summarization and paraphrasing, without supervision. In this paper, we propose that language models can learn to summarize and paraphrase sentences, with none of these 3 factors. We present Impossible Distillation, a framework that distills a task-specific dataset directly from an off-the-shelf LM, even when it is impossible for the LM itself to reliably solve the task. By training a student model on the generated dataset and amplifying its capability through self-distillation, our method yields a high-quality model and dataset from a low-quality teacher model, without the need for scale or supervision. Using Impossible Distillation, we are able to distill an order of magnitude smaller model (with only 770M parameters) that outperforms 175B parameter GPT-3, in both quality and controllability, as confirmed by automatic and human evaluations. Furthermore, as a useful byproduct of our approach, we obtain DIMSUM+, a high-quality dataset with 3.4M sentence summaries and paraphrases. Our analyses show that this dataset, as a purely LM-generated corpus, is more diverse and more effective for generalization to unseen domains than all human-authored datasets -- including Gigaword with 4M samples.