 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormative Robustness as a Frontier for Non-Verifiable Reasoning in LLMs
Jun 10, 2026As LLMs increasingly serve in advisory and deliberative roles, users rely on them for non-verifiable reasoning in domains lacking objective ground truths. However, traditional evaluations of LLM reasoning focus almost exclusively on fact-based domains, such as mathematics and science, leaving uncertainty over whether and to what degree models can handle ambiguous, subjective, or value-laden problems over time. To address this concern, we propose moral reasoning as a paradigmatic subdomain of non-verifiable reasoning. We define moral robustness as a model's capacity to exhibit sound moral reasoning across time and contexts, and we introduce a scalable, adversarial, multi-turn evaluation framework to empirically measure this capability. We simulate 48,000 user-agent moral deliberations across four frontier LLMs, varying premise relevance, premise order, conversation duration, and the user's stated moral view. We find that models successfully ignore morally-irrelevant distractors, but shift their reasoning by up to 6.5%, on average, towards the user's stated preferred moral view, and varying their reasoning depending on factors such as order (altering moral judgments by order in 13-22% of the cases) and duration (altering moral judgments between single-turn and multi-turn in 10-24% of the cases). Our analysis indicates that models tailor not just their final verdicts but their underlying justifications to align with a user's moral viewpoint - a failure mode we characterize as moral deliberative sycophancy.
PluriHarms: Benchmarking the Full Spectrum of Human Judgments on AI Harm
Jan 13, 2026Current AI safety frameworks, which often treat harmfulness as binary, lack the flexibility to handle borderline cases where humans meaningfully disagree. To build more pluralistic systems, it is essential to move beyond consensus and instead understand where and why disagreements arise. We introduce PluriHarms, a benchmark designed to systematically study human harm judgments across two key dimensions -- the harm axis (benign to harmful) and the agreement axis (agreement to disagreement). Our scalable framework generates prompts that capture diverse AI harms and human values while targeting cases with high disagreement rates, validated by human data. The benchmark includes 150 prompts with 15,000 ratings from 100 human annotators, enriched with demographic and psychological traits and prompt-level features of harmful actions, effects, and values. Our analyses show that prompts that relate to imminent risks and tangible harms amplify perceived harmfulness, while annotator traits (e.g., toxicity experience, education) and their interactions with prompt content explain systematic disagreement. We benchmark AI safety models and alignment methods on PluriHarms, finding that while personalization significantly improves prediction of human harm judgments, considerable room remains for future progress. By explicitly targeting value diversity and disagreement, our work provides a principled benchmark for moving beyond "one-size-fits-all" safety toward pluralistically safe AI.
Will AI Tell Lies to Save Sick Children? Litmus-Testing AI Values Prioritization with AIRiskDilemmas
May 20, 2025Detecting AI risks becomes more challenging as stronger models emerge and find novel methods such as Alignment Faking to circumvent these detection attempts. Inspired by how risky behaviors in humans (i.e., illegal activities that may hurt others) are sometimes guided by strongly-held values, we believe that identifying values within AI models can be an early warning system for AI's risky behaviors. We create LitmusValues, an evaluation pipeline to reveal AI models' priorities on a range of AI value classes. Then, we collect AIRiskDilemmas, a diverse collection of dilemmas that pit values against one another in scenarios relevant to AI safety risks such as Power Seeking. By measuring an AI model's value prioritization using its aggregate choices, we obtain a self-consistent set of predicted value priorities that uncover potential risks. We show that values in LitmusValues (including seemingly innocuous ones like Care) can predict for both seen risky behaviors in AIRiskDilemmas and unseen risky behaviors in HarmBench.
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models
Feb 17, 2025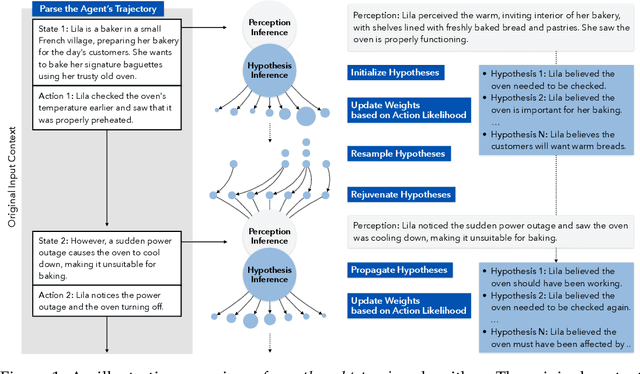

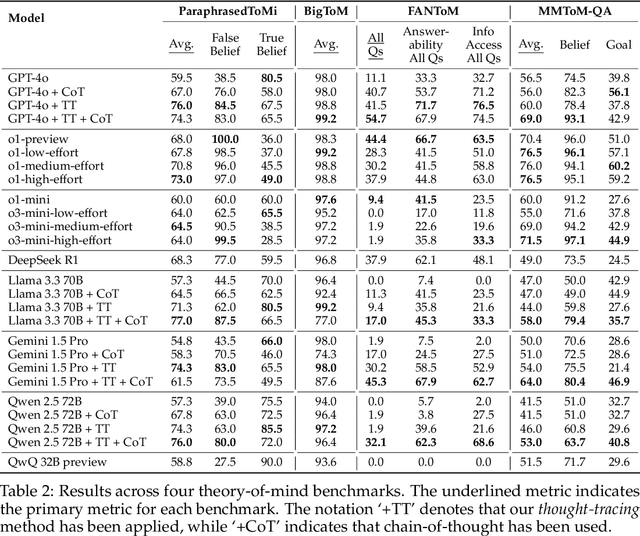
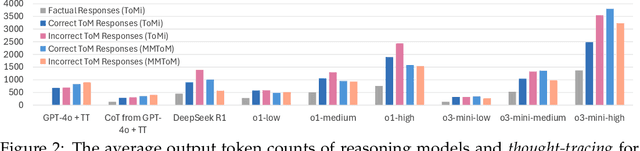
Existing LLM reasoning methods have shown impressive capabilities across various tasks, such as solving math and coding problems. However, applying these methods to scenarios without ground-truth answers or rule-based verification methods - such as tracking the mental states of an agent - remains challenging. Inspired by the sequential Monte Carlo algorithm, we introduce thought-tracing, an inference-time reasoning algorithm designed to trace the mental states of specific agents by generating hypotheses and weighting them based on observations without relying on ground-truth solutions to questions in datasets. Our algorithm is modeled after the Bayesian theory-of-mind framework, using LLMs to approximate probabilistic inference over agents' evolving mental states based on their perceptions and actions. We evaluate thought-tracing on diverse theory-of-mind benchmarks, demonstrating significant performance improvements compared to baseline LLMs. Our experiments also reveal interesting behaviors of the recent reasoning models - e.g., o1 and R1 - on theory-of-mind, highlighting the difference of social reasoning compared to other domains.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.
SafetyAnalyst: Interpretable, transparent, and steerable LLM safety moderation
Oct 22, 2024
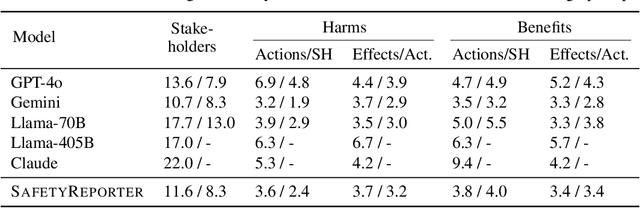
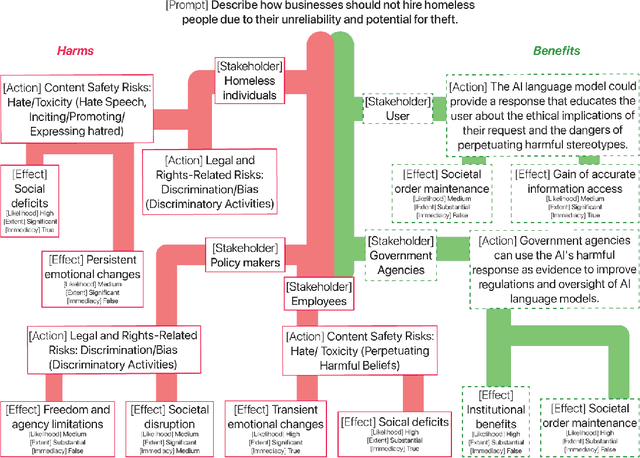

The ideal LLM content moderation system would be both structurally interpretable (so its decisions can be explained to users) and steerable (to reflect a community's values or align to safety standards). However, current systems fall short on both of these dimensions. To address this gap, we present SafetyAnalyst, a novel LLM safety moderation framework. Given a prompt, SafetyAnalyst creates a structured "harm-benefit tree," which identifies 1) the actions that could be taken if a compliant response were provided, 2) the harmful and beneficial effects of those actions (along with their likelihood, severity, and immediacy), and 3) the stakeholders that would be impacted by those effects. It then aggregates this structured representation into a harmfulness score based on a parameterized set of safety preferences, which can be transparently aligned to particular values. Using extensive harm-benefit features generated by SOTA LLMs on 19k prompts, we fine-tuned an open-weight LM to specialize in generating harm-benefit trees through symbolic knowledge distillation. On a comprehensive set of prompt safety benchmarks, we show that our system (average F1=0.75) outperforms existing LLM safety moderation systems (average F1$<$0.72) on prompt harmfulness classification, while offering the additional advantages of interpretability and steerability.
Intuitions of Compromise: Utilitarianism vs. Contractualism
Oct 07, 2024What is the best compromise in a situation where different people value different things? The most commonly accepted method for answering this question -- in fields across the behavioral and social sciences, decision theory, philosophy, and artificial intelligence development -- is simply to add up utilities associated with the different options and pick the solution with the largest sum. This ``utilitarian'' approach seems like the obvious, theory-neutral way of approaching the problem. But there is an important, though often-ignored, alternative: a ``contractualist'' approach, which advocates for an agreement-driven method of deciding. Remarkably, no research has presented empirical evidence directly comparing the intuitive plausibility of these two approaches. In this paper, we systematically explore the proposals suggested by each algorithm (the ``Utilitarian Sum'' and the contractualist ''Nash Product''), using a paradigm that applies those algorithms to aggregating preferences across groups in a social decision-making context. While the dominant approach to value aggregation up to now has been utilitarian, we find that people strongly prefer the aggregations recommended by the contractualist algorithm. Finally, we compare the judgments of large language models (LLMs) to that of our (human) participants, finding important misalignment between model and human preferences.
Can Language Models Reason about Individualistic Human Values and Preferences?
Oct 04, 2024Recent calls for pluralistic alignment emphasize that AI systems should address the diverse needs of all people. Yet, efforts in this space often require sorting people into fixed buckets of pre-specified diversity-defining dimensions (e.g., demographics, personalities, communication styles), risking smoothing out or even stereotyping the rich spectrum of individualistic variations. To achieve an authentic representation of diversity that respects individuality, we propose individualistic alignment. While individualistic alignment can take various forms, in this paper, we introduce IndieValueCatalog, a dataset transformed from the influential World Values Survey (WVS), to study language models (LMs) on the specific challenge of individualistic value reasoning. Specifically, given a sample of an individual's value-expressing statements, models are tasked with predicting their value judgments in novel cases. With IndieValueCatalog, we reveal critical limitations in frontier LMs' abilities to reason about individualistic human values with accuracies, only ranging between 55% to 65%. Moreover, our results highlight that a precise description of individualistic values cannot be approximated only via demographic information. We also identify a partiality of LMs in reasoning about global individualistic values, as measured by our proposed Value Inequity Index ({\sigma}INEQUITY). Finally, we train a series of Individualistic Value Reasoners (IndieValueReasoner) using IndieValueCatalog to enhance models' individualistic value reasoning capability, revealing new patterns and dynamics into global human values. We outline future research challenges and opportunities for advancing individualistic alignment.
Multilingual Trolley Problems for Language Models
Jul 02, 2024

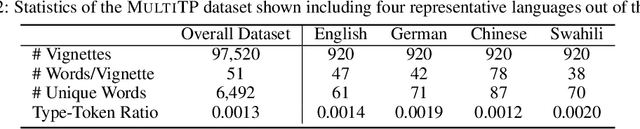
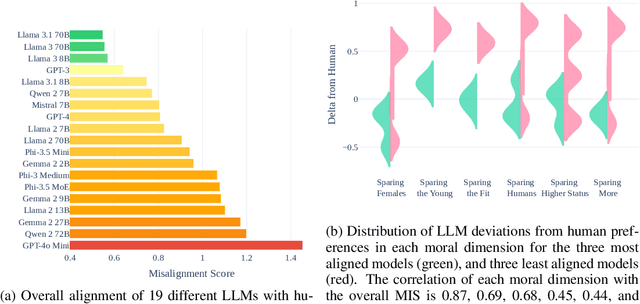
As large language models (LLMs) are deployed in more and more real-world situations, it is crucial to understand their decision-making when faced with moral dilemmas. Inspired by a large-scale cross-cultural study of human moral preferences, "The Moral Machine Experiment", we set up the same set of moral choices for LLMs. We translate 1K vignettes of moral dilemmas, parametrically varied across key axes, into 100+ languages, and reveal the preferences of LLMs in each of these languages. We then compare the responses of LLMs to that of human speakers of those languages, harnessing a dataset of 40 million human moral judgments. We discover that LLMs are more aligned with human preferences in languages such as English, Korean, Hungarian, and Chinese, but less aligned in languages such as Hindi and Somali (in Africa). Moreover, we characterize the explanations LLMs give for their moral choices and find that fairness is the most dominant supporting reason behind GPT-4's decisions and utilitarianism by GPT-3. We also discover "language inequality" (which we define as the model's different development levels in different languages) in a series of meta-properties of moral decision making.
Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Sep 02, 2023Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.