 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise Reasoning via Reinforcement Learning
Apr 07, 2025Despite significant advancements in large language models (LLMs), a major drawback of reasoning models is their enormous token usage, which increases computational cost, resource requirements, and response time. In this work, we revisit the core principles of reinforcement learning (RL) and, through mathematical analysis, demonstrate that the tendency to generate lengthy responses arises inherently from RL-based optimization during training. This finding questions the prevailing assumption that longer responses inherently improve reasoning accuracy. Instead, we uncover a natural correlation between conciseness and accuracy that has been largely overlooked. Moreover, we show that introducing a secondary phase of RL post-training, using a small set of problems and limited resources, can significantly reduce a model's chain of thought while maintaining or even enhancing accuracy. Finally, we validate our conclusions through extensive experimental results.
"Yeah Right!" -- Do LLMs Exhibit Multimodal Feature Transfer?
Jan 07, 2025



Human communication is a multifaceted and multimodal skill. Communication requires an understanding of both the surface-level textual content and the connotative intent of a piece of communication. In humans, learning to go beyond the surface level starts by learning communicative intent in speech. Once humans acquire these skills in spoken communication, they transfer those skills to written communication. In this paper, we assess the ability of speech+text models and text models trained with special emphasis on human-to-human conversations to make this multimodal transfer of skill. We specifically test these models on their ability to detect covert deceptive communication. We find that with no special prompting speech+text LLMs have an advantage over unimodal LLMs in performing this task. Likewise, we find that human-to-human conversation-trained LLMs are also advantaged in this skill.
Reading with Intent
Aug 20, 2024



Retrieval augmented generation (RAG) systems augment how knowledge language models are by integrating external information sources such as Wikipedia, internal documents, scientific papers, or the open internet. RAG systems that rely on the open internet as their knowledge source have to contend with the complexities of human-generated content. Human communication extends much deeper than just the words rendered as text. Intent, tonality, and connotation can all change the meaning of what is being conveyed. Recent real-world deployments of RAG systems have shown some difficulty in understanding these nuances of human communication. One significant challenge for these systems lies in processing sarcasm. Though the Large Language Models (LLMs) that make up the backbone of these RAG systems are able to detect sarcasm, they currently do not always use these detections for the subsequent processing of text. To address these issues, in this paper, we synthetically generate sarcastic passages from Natural Question's Wikipedia retrieval corpus. We then test the impact of these passages on the performance of both the retriever and reader portion of the RAG pipeline. We introduce a prompting system designed to enhance the model's ability to interpret and generate responses in the presence of sarcasm, thus improving overall system performance. Finally, we conduct ablation studies to validate the effectiveness of our approach, demonstrating improvements in handling sarcastic content within RAG systems.
EXPLORER: Exploration-guided Reasoning for Textual Reinforcement Learning
Mar 15, 2024Text-based games (TBGs) have emerged as an important collection of NLP tasks, requiring reinforcement learning (RL) agents to combine natural language understanding with reasoning. A key challenge for agents attempting to solve such tasks is to generalize across multiple games and demonstrate good performance on both seen and unseen objects. Purely deep-RL-based approaches may perform well on seen objects; however, they fail to showcase the same performance on unseen objects. Commonsense-infused deep-RL agents may work better on unseen data; unfortunately, their policies are often not interpretable or easily transferable. To tackle these issues, in this paper, we present EXPLORER which is an exploration-guided reasoning agent for textual reinforcement learning. EXPLORER is neurosymbolic in nature, as it relies on a neural module for exploration and a symbolic module for exploitation. It can also learn generalized symbolic policies and perform well over unseen data. Our experiments show that EXPLORER outperforms the baseline agents on Text-World cooking (TW-Cooking) and Text-World Commonsense (TWC) games.
Are Human Conversations Special? A Large Language Model Perspective
Mar 08, 2024



This study analyzes changes in the attention mechanisms of large language models (LLMs) when used to understand natural conversations between humans (human-human). We analyze three use cases of LLMs: interactions over web content, code, and mathematical texts. By analyzing attention distance, dispersion, and interdependency across these domains, we highlight the unique challenges posed by conversational data. Notably, conversations require nuanced handling of long-term contextual relationships and exhibit higher complexity through their attention patterns. Our findings reveal that while language models exhibit domain-specific attention behaviors, there is a significant gap in their ability to specialize in human conversations. Through detailed attention entropy analysis and t-SNE visualizations, we demonstrate the need for models trained with a diverse array of high-quality conversational data to enhance understanding and generation of human-like dialogue. This research highlights the importance of domain specialization in language models and suggests pathways for future advancement in modeling human conversational nuances.
Knowledge-augmented Deep Learning and Its Applications: A Survey
Nov 30, 2022Deep learning models, though having achieved great success in many different fields over the past years, are usually data hungry, fail to perform well on unseen samples, and lack of interpretability. Various prior knowledge often exists in the target domain and their use can alleviate the deficiencies with deep learning. To better mimic the behavior of human brains, different advanced methods have been proposed to identify domain knowledge and integrate it into deep models for data-efficient, generalizable, and interpretable deep learning, which we refer to as knowledge-augmented deep learning (KADL). In this survey, we define the concept of KADL, and introduce its three major tasks, i.e., knowledge identification, knowledge representation, and knowledge integration. Different from existing surveys that are focused on a specific type of knowledge, we provide a broad and complete taxonomy of domain knowledge and its representations. Based on our taxonomy, we provide a systematic review of existing techniques, different from existing works that survey integration approaches agnostic to taxonomy of knowledge. This survey subsumes existing works and offers a bird's-eye view of research in the general area of knowledge-augmented deep learning. The thorough and critical reviews of numerous papers help not only understand current progresses but also identify future directions for the research on knowledge-augmented deep learning.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022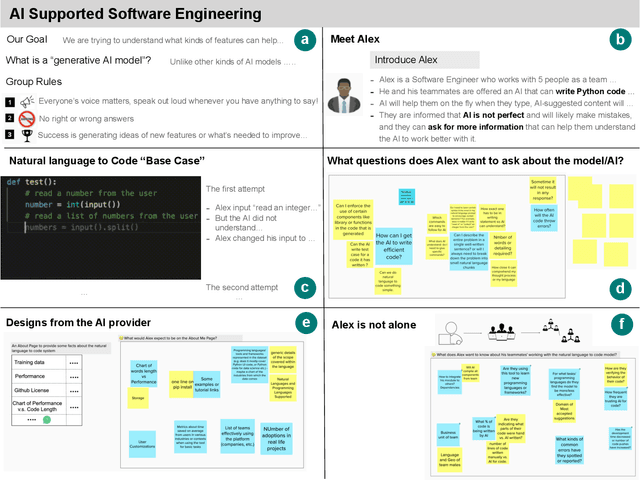
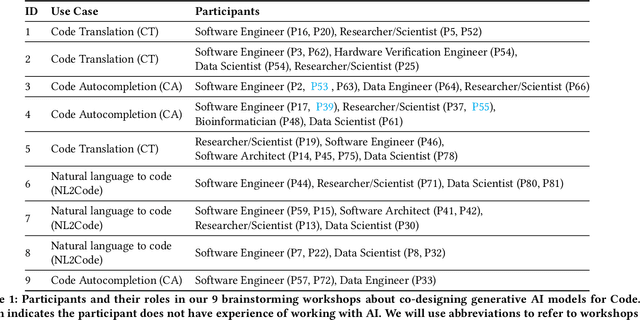

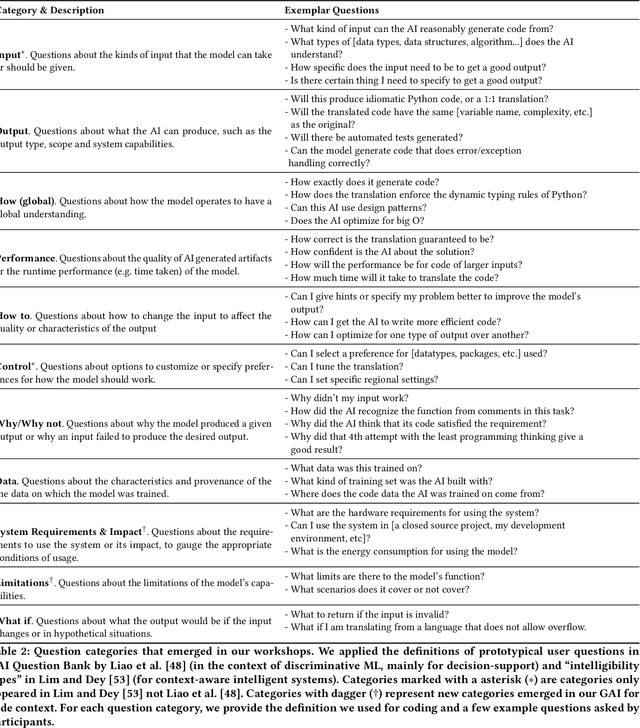
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.
When Is It Acceptable to Break the Rules? Knowledge Representation of Moral Judgement Based on Empirical Data
Jan 19, 2022One of the most remarkable things about the human moral mind is its flexibility. We can make moral judgments about cases we have never seen before. We can decide that pre-established rules should be broken. We can invent novel rules on the fly. Capturing this flexibility is one of the central challenges in developing AI systems that can interpret and produce human-like moral judgment. This paper details the results of a study of real-world decision makers who judge whether it is acceptable to break a well-established norm: ``no cutting in line.'' We gather data on how human participants judge the acceptability of line-cutting in a range of scenarios. Then, in order to effectively embed these reasoning capabilities into a machine, we propose a method for modeling them using a preference-based structure, which captures a novel modification to standard ``dual process'' theories of moral judgment.
Using Document Similarity Methods to create Parallel Datasets for Code Translation
Oct 11, 2021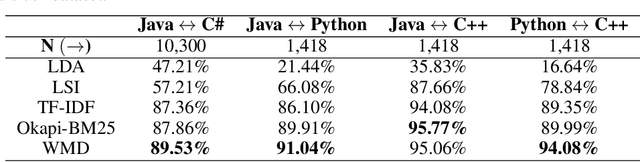
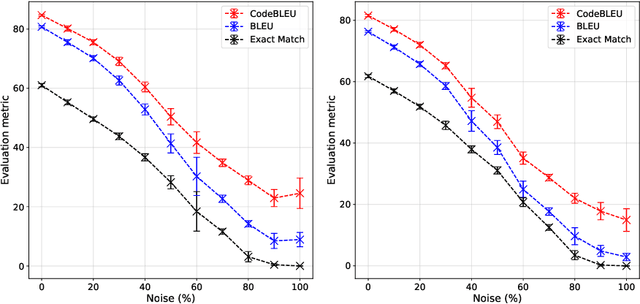
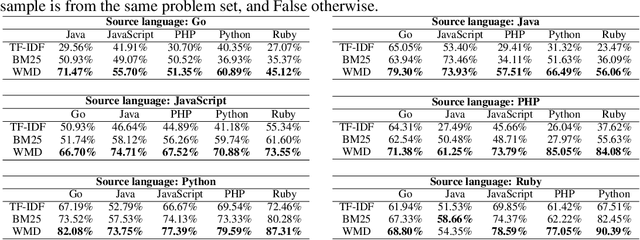
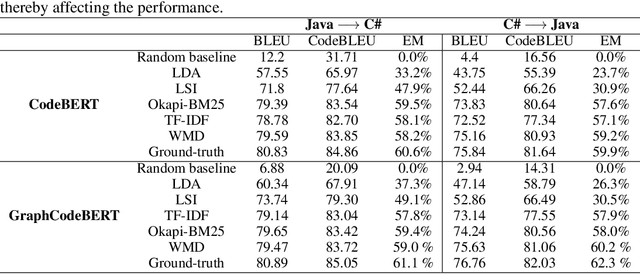
Translating source code from one programming language to another is a critical, time-consuming task in modernizing legacy applications and codebases. Recent work in this space has drawn inspiration from the software naturalness hypothesis by applying natural language processing techniques towards automating the code translation task. However, due to the paucity of parallel data in this domain, supervised techniques have only been applied to a limited set of popular programming languages. To bypass this limitation, unsupervised neural machine translation techniques have been proposed to learn code translation using only monolingual corpora. In this work, we propose to use document similarity methods to create noisy parallel datasets of code, thus enabling supervised techniques to be applied for automated code translation without having to rely on the availability or expensive curation of parallel code datasets. We explore the noise tolerance of models trained on such automatically-created datasets and show that these models perform comparably to models trained on ground truth for reasonable levels of noise. Finally, we exhibit the practical utility of the proposed method by creating parallel datasets for languages beyond the ones explored in prior work, thus expanding the set of programming languages for automated code translation.
Eye of the Beholder: Improved Relation Generalization for Text-based Reinforcement Learning Agents
Jun 15, 2021
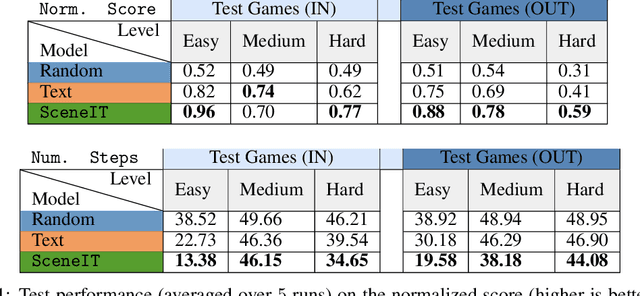
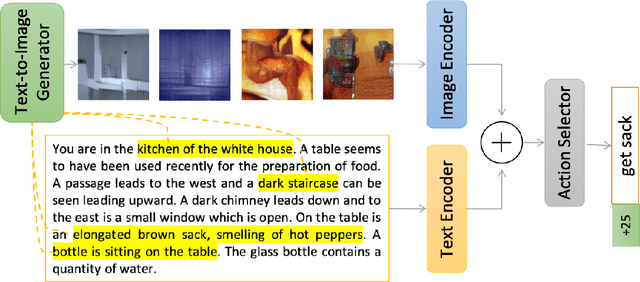
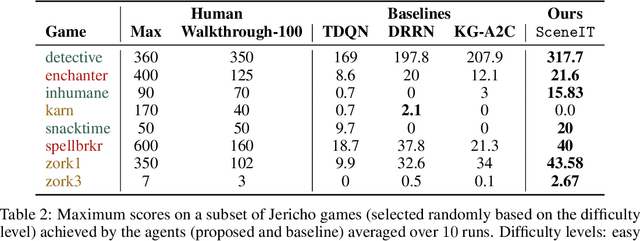
Text-based games (TBGs) have become a popular proving ground for the demonstration of learning-based agents that make decisions in quasi real-world settings. The crux of the problem for a reinforcement learning agent in such TBGs is identifying the objects in the world, and those objects' relations with that world. While the recent use of text-based resources for increasing an agent's knowledge and improving its generalization have shown promise, we posit in this paper that there is much yet to be learned from visual representations of these same worlds. Specifically, we propose to retrieve images that represent specific instances of text observations from the world and train our agents on such images. This improves the agent's overall understanding of the game 'scene' and objects' relationships to the world around them, and the variety of visual representations on offer allow the agent to generate a better generalization of a relationship. We show that incorporating such images improves the performance of agents in various TBG settings.