 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Sliding Windows: Learning to Manage Memory in Non-Markovian Environments
Dec 22, 2025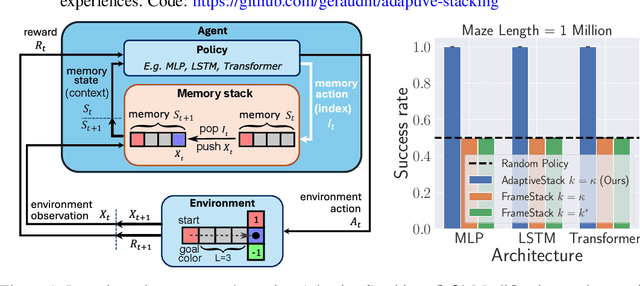

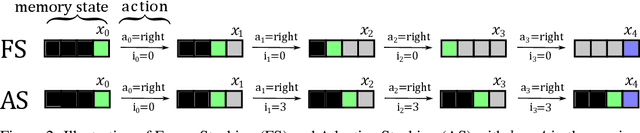

Recent success in developing increasingly general purpose agents based on sequence models has led to increased focus on the problem of deploying computationally limited agents within the vastly more complex real-world. A key challenge experienced in these more realistic domains is highly non-Markovian dependencies with respect to the agent's observations, which are less common in small controlled domains. The predominant approach for dealing with this in the literature is to stack together a window of the most recent observations (Frame Stacking), but this window size must grow with the degree of non-Markovian dependencies, which results in prohibitive computational and memory requirements for both action inference and learning. In this paper, we are motivated by the insight that in many environments that are highly non-Markovian with respect to time, the environment only causally depends on a relatively small number of observations over that time-scale. A natural direction would then be to consider meta-algorithms that maintain relatively small adaptive stacks of memories such that it is possible to express highly non-Markovian dependencies with respect to time while considering fewer observations at each step and thus experience substantial savings in both compute and memory requirements. Hence, we propose a meta-algorithm (Adaptive Stacking) for achieving exactly that with convergence guarantees and quantify the reduced computation and memory constraints for MLP, LSTM, and Transformer-based agents. Our experiments utilize popular memory tasks, which give us control over the degree of non-Markovian dependencies. This allows us to demonstrate that an appropriate meta-algorithm can learn the removal of memories not predictive of future rewards without excessive removal of important experiences. Code: https://github.com/geraudnt/adaptive-stacking
Transformers Learn Faster with Semantic Focus
Jun 18, 2025Various forms of sparse attention have been explored to mitigate the quadratic computational and memory cost of the attention mechanism in transformers. We study sparse transformers not through a lens of efficiency but rather in terms of learnability and generalization. Empirically studying a range of attention mechanisms, we find that input-dependent sparse attention models appear to converge faster and generalize better than standard attention models, while input-agnostic sparse attention models show no such benefits -- a phenomenon that is robust across architectural and optimization hyperparameter choices. This can be interpreted as demonstrating that concentrating a model's "semantic focus" with respect to the tokens currently being considered (in the form of input-dependent sparse attention) accelerates learning. We develop a theoretical characterization of the conditions that explain this behavior. We establish a connection between the stability of the standard softmax and the loss function's Lipschitz properties, then show how sparsity affects the stability of the softmax and the subsequent convergence and generalization guarantees resulting from the attention mechanism. This allows us to theoretically establish that input-agnostic sparse attention does not provide any benefits. We also characterize conditions when semantic focus (input-dependent sparse attention) can provide improved guarantees, and we validate that these conditions are in fact met in our empirical evaluations.
Quantifying artificial intelligence through algebraic generalization
Nov 08, 2024The rapid development of modern artificial intelligence (AI) systems has created an urgent need for their scientific quantification. While their fluency across a variety of domains is impressive, modern AI systems fall short on tests requiring symbolic processing and abstraction - a glaring limitation given the necessity for interpretable and reliable technology. Despite a surge of reasoning benchmarks emerging from the academic community, no comprehensive and theoretically-motivated framework exists to quantify reasoning (and more generally, symbolic ability) in AI systems. Here, we adopt a framework from computational complexity theory to explicitly quantify symbolic generalization: algebraic circuit complexity. Many symbolic reasoning problems can be recast as algebraic expressions. Thus, algebraic circuit complexity theory - the study of algebraic expressions as circuit models (i.e., directed acyclic graphs) - is a natural framework to study the complexity of symbolic computation. The tools of algebraic circuit complexity enable the study of generalization by defining benchmarks in terms of their complexity-theoretic properties (i.e., the difficulty of a problem). Moreover, algebraic circuits are generic mathematical objects; for a given algebraic circuit, an arbitrarily large number of samples can be generated for a specific circuit, making it an optimal testbed for the data-hungry machine learning algorithms that are used today. Here, we adopt tools from algebraic circuit complexity theory, apply it to formalize a science of symbolic generalization, and address key theoretical and empirical challenges for its successful application to AI science and its impact on the broader community.
Neural Reasoning Networks: Efficient Interpretable Neural Networks With Automatic Textual Explanations
Oct 10, 2024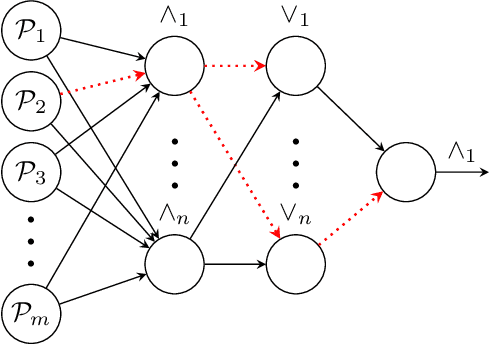

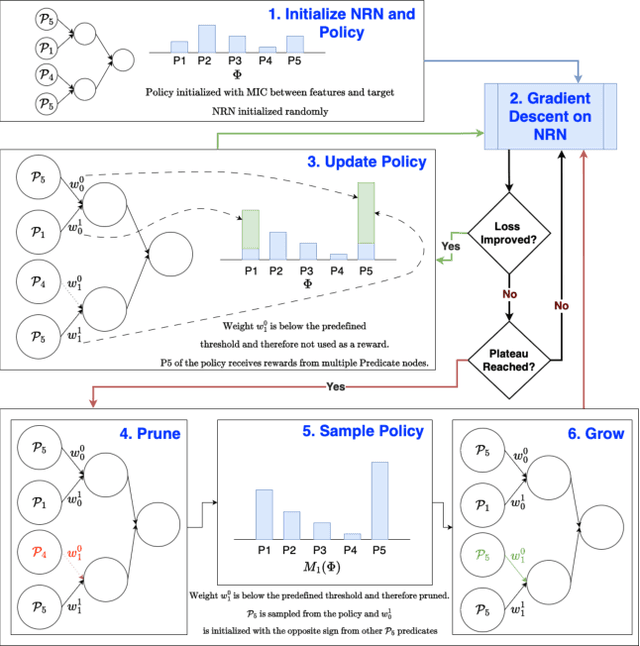

Recent advances in machine learning have led to a surge in adoption of neural networks for various tasks, but lack of interpretability remains an issue for many others in which an understanding of the features influencing the prediction is necessary to ensure fairness, safety, and legal compliance. In this paper we consider one class of such tasks, tabular dataset classification, and propose a novel neuro-symbolic architecture, Neural Reasoning Networks (NRN), that is scalable and generates logically sound textual explanations for its predictions. NRNs are connected layers of logical neurons which implement a form of real valued logic. A training algorithm (R-NRN) learns the weights of the network as usual using gradient descent optimization with backprop, but also learns the network structure itself using a bandit-based optimization. Both are implemented in an extension to PyTorch (https://github.com/IBM/torchlogic) that takes full advantage of GPU scaling and batched training. Evaluation on a diverse set of 22 open-source datasets for tabular classification demonstrates performance (measured by ROC AUC) which improves over multi-layer perceptron (MLP) and is statistically similar to other state-of-the-art approaches such as Random Forest, XGBoost and Gradient Boosted Trees, while offering 43% faster training and a more than 2 orders of magnitude reduction in the number of parameters required, on average. Furthermore, R-NRN explanations are shorter than the compared approaches while producing more accurate feature importance scores.
The Importance of Positional Encoding Initialization in Transformers for Relational Reasoning
Jun 12, 2024Relational reasoning refers to the ability to infer and understand the relations between multiple entities. In humans, this ability underpins many higher cognitive functions, such as problem solving and decision-making, and has been reliably linked to fluid intelligence. Despite machine learning models making impressive advances across various domains, such as natural language processing and vision, the extent to which such models can perform relational reasoning tasks remains unclear. Here we study the importance of positional encoding (PE) for relational reasoning in the Transformer, and find that a learnable PE outperforms all other commonly-used PEs (e.g., absolute, relative, rotary, etc.). Moreover, we find that when using a PE with a learnable parameter, the choice of initialization greatly influences the learned representations and its downstream generalization performance. Specifically, we find that a learned PE initialized from a small-norm distribution can 1) uncover ground-truth position information, 2) generalize in the presence of noisy inputs, and 3) produce behavioral patterns that are consistent with human performance. Our results shed light on the importance of learning high-performing and robust PEs during relational reasoning tasks, which will prove useful for tasks in which ground truth positions are not provided or not known.
What makes Models Compositional? A Theoretical View: With Supplement
May 02, 2024
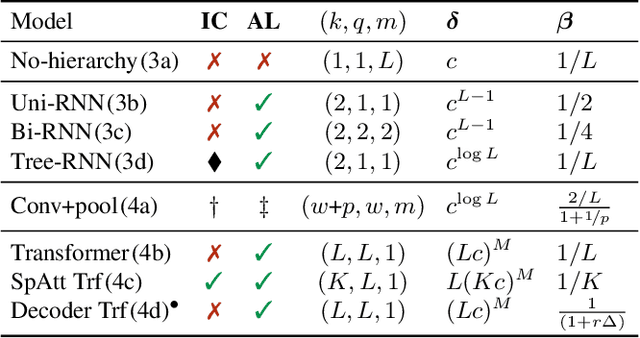


Compositionality is thought to be a key component of language, and various compositional benchmarks have been developed to empirically probe the compositional generalization of existing sequence processing models. These benchmarks often highlight failures of existing models, but it is not clear why these models fail in this way. In this paper, we seek to theoretically understand the role the compositional structure of the models plays in these failures and how this structure relates to their expressivity and sample complexity. We propose a general neuro-symbolic definition of compositional functions and their compositional complexity. We then show how various existing general and special purpose sequence processing models (such as recurrent, convolution and attention-based ones) fit this definition and use it to analyze their compositional complexity. Finally, we provide theoretical guarantees for the expressivity and systematic generalization of compositional models that explicitly depend on our proposed definition and highlighting factors which drive poor empirical performance.
EXPLORER: Exploration-guided Reasoning for Textual Reinforcement Learning
Mar 15, 2024Text-based games (TBGs) have emerged as an important collection of NLP tasks, requiring reinforcement learning (RL) agents to combine natural language understanding with reasoning. A key challenge for agents attempting to solve such tasks is to generalize across multiple games and demonstrate good performance on both seen and unseen objects. Purely deep-RL-based approaches may perform well on seen objects; however, they fail to showcase the same performance on unseen objects. Commonsense-infused deep-RL agents may work better on unseen data; unfortunately, their policies are often not interpretable or easily transferable. To tackle these issues, in this paper, we present EXPLORER which is an exploration-guided reasoning agent for textual reinforcement learning. EXPLORER is neurosymbolic in nature, as it relies on a neural module for exploration and a symbolic module for exploitation. It can also learn generalized symbolic policies and perform well over unseen data. Our experiments show that EXPLORER outperforms the baseline agents on Text-World cooking (TW-Cooking) and Text-World Commonsense (TWC) games.
Compositional Program Generation for Systematic Generalization
Sep 28, 2023
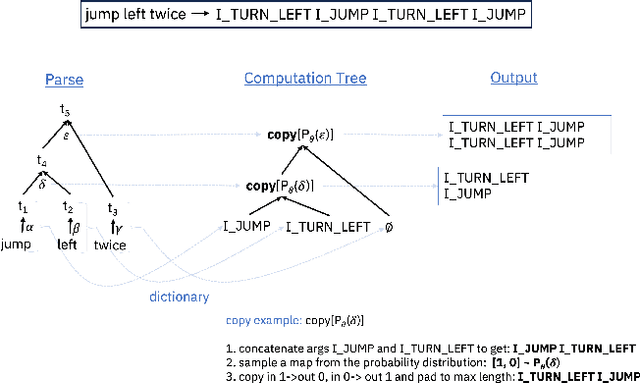
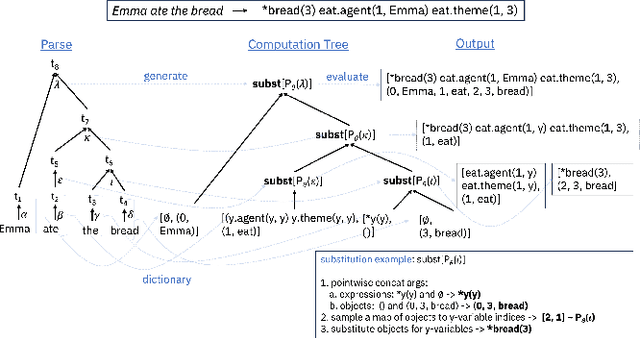

Compositional generalization is a key ability of humans that enables us to learn new concepts from only a handful examples. Machine learning models, including the now ubiquitous transformers, struggle to generalize in this way, and typically require thousands of examples of a concept during training in order to generalize meaningfully. This difference in ability between humans and artificial neural architectures, motivates this study on a neuro-symbolic architecture called the Compositional Program Generator (CPG). CPG has three key features: modularity, type abstraction, and recursive composition, that enable it to generalize both systematically to new concepts in a few-shot manner, as well as productively by length on various sequence-to-sequence language tasks. For each input, CPG uses a grammar of the input domain and a parser to generate a type hierarchy in which each grammar rule is assigned its own unique semantic module, a probabilistic copy or substitution program. Instances with the same hierarchy are processed with the same composed program, while those with different hierarchies may be processed with different programs. CPG learns parameters for the semantic modules and is able to learn the semantics for new types incrementally. Given a context-free grammar of the input language and a dictionary mapping each word in the source language to its interpretation in the output language, CPG can achieve perfect generalization on the SCAN and COGS benchmarks, in both standard and extreme few-shot settings.
Laziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023
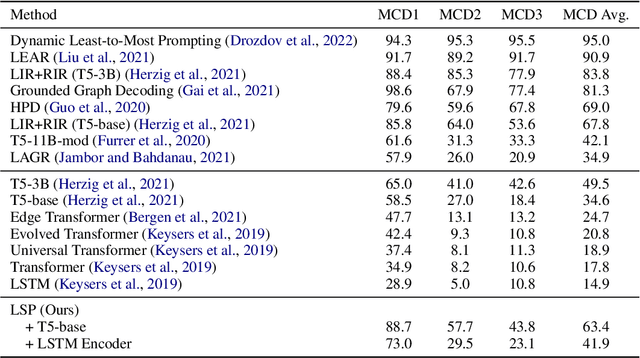


Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.
Learning in Factored Domains with Information-Constrained Visual Representations
Mar 30, 2023Humans learn quickly even in tasks that contain complex visual information. This is due in part to the efficient formation of compressed representations of visual information, allowing for better generalization and robustness. However, compressed representations alone are insufficient for explaining the high speed of human learning. Reinforcement learning (RL) models that seek to replicate this impressive efficiency may do so through the use of factored representations of tasks. These informationally simplistic representations of tasks are similarly motivated as the use of compressed representations of visual information. Recent studies have connected biological visual perception to disentangled and compressed representations. This raises the question of how humans learn to efficiently represent visual information in a manner useful for learning tasks. In this paper we present a model of human factored representation learning based on an altered form of a $\beta$-Variational Auto-encoder used in a visual learning task. Modelling results demonstrate a trade-off in the informational complexity of model latent dimension spaces, between the speed of learning and the accuracy of reconstructions.