 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning
Feb 02, 2024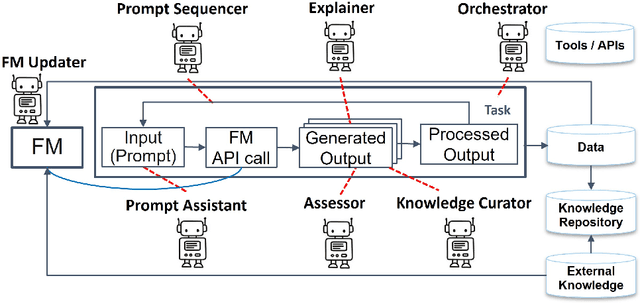


Foundation models (FMs) such as large language models have revolutionized the field of AI by showing remarkable performance in various tasks. However, they exhibit numerous limitations that prevent their broader adoption in many real-world systems, which often require a higher bar for trustworthiness and usability. Since FMs are trained using loss functions aimed at reconstructing the training corpus in a self-supervised manner, there is no guarantee that the model's output aligns with users' preferences for a specific task at hand. In this survey paper, we propose a conceptual framework that encapsulates different modes by which agents could interact with FMs and guide them suitably for a set of tasks, particularly through knowledge augmentation and reasoning. Our framework elucidates agent role categories such as updating the underlying FM, assisting with prompting the FM, and evaluating the FM output. We also categorize several state-of-the-art approaches into agent interaction protocols, highlighting the nature and extent of involvement of the various agent roles. The proposed framework provides guidance for future directions to further realize the power of FMs in practical AI systems.
Utterance Classification with Logical Neural Network: Explainable AI for Mental Disorder Diagnosis
Jun 06, 2023In response to the global challenge of mental health problems, we proposes a Logical Neural Network (LNN) based Neuro-Symbolic AI method for the diagnosis of mental disorders. Due to the lack of effective therapy coverage for mental disorders, there is a need for an AI solution that can assist therapists with the diagnosis. However, current Neural Network models lack explainability and may not be trusted by therapists. The LNN is a Recurrent Neural Network architecture that combines the learning capabilities of neural networks with the reasoning capabilities of classical logic-based AI. The proposed system uses input predicates from clinical interviews to output a mental disorder class, and different predicate pruning techniques are used to achieve scalability and higher scores. In addition, we provide an insight extraction method to aid therapists with their diagnosis. The proposed system addresses the lack of explainability of current Neural Network models and provides a more trustworthy solution for mental disorder diagnosis.
AI Planning Annotation for Sample Efficient Reinforcement Learning
Mar 01, 2022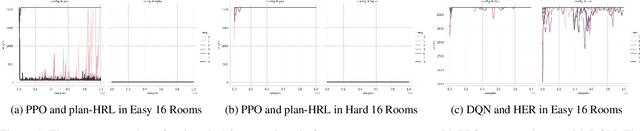

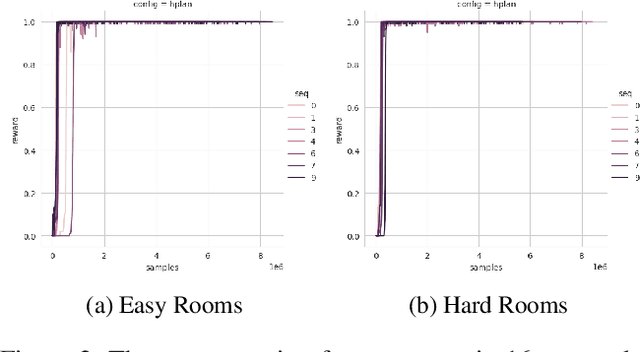
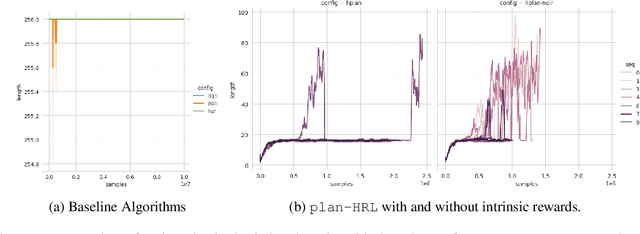
AI planning and Reinforcement Learning (RL) both solve sequential decision-making problems under the different formulations. AI Planning requires operator models, but then allows efficient plan generation. RL requires no operator model, instead learns a policy to guide an agent to high reward states. Planning can be brittle in the face of noise whereas RL is more tolerant. However, RL requires a large number of training examples to learn the policy. In this work, we aim to bring AI planning and RL closer by showing that a suitably defined planning model can be used to improve the efficiency of RL. Specifically, we show that the options in the hierarchical RL can be derived from a planning task and integrate planning and RL algorithms for training option policy functions. Our experiments demonstrate an improved sample efficiency on a variety of RL environments over the previous state-of-the-art.
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021
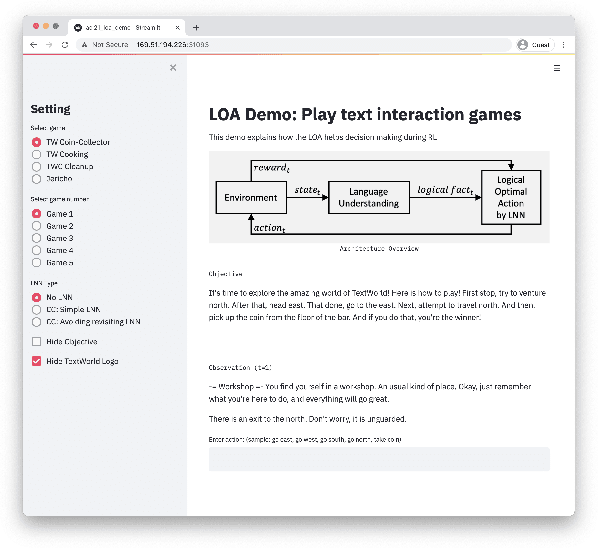
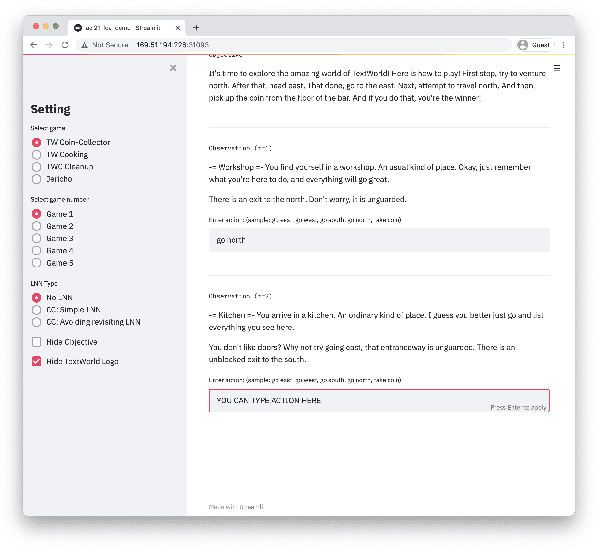
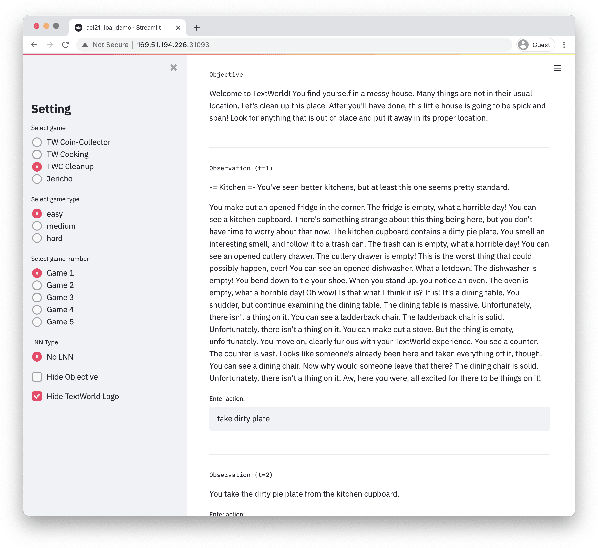
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa
Neuro-Symbolic Reinforcement Learning with First-Order Logic
Oct 21, 2021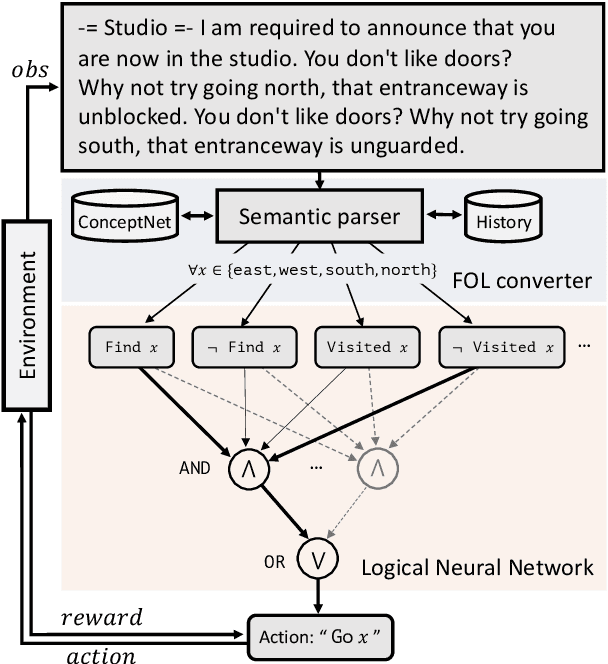
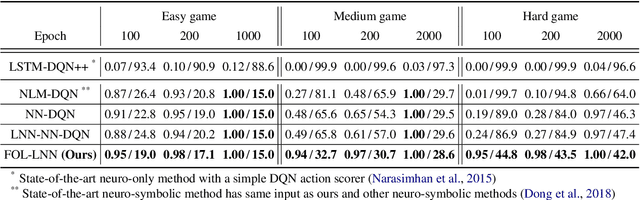
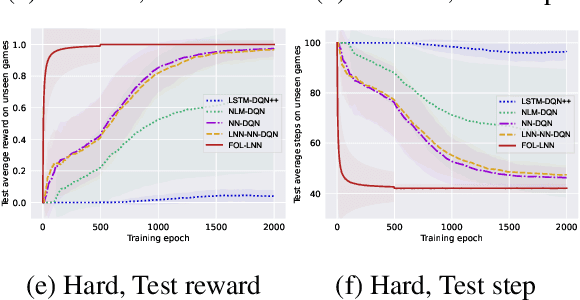
Deep reinforcement learning (RL) methods often require many trials before convergence, and no direct interpretability of trained policies is provided. In order to achieve fast convergence and interpretability for the policy in RL, we propose a novel RL method for text-based games with a recent neuro-symbolic framework called Logical Neural Network, which can learn symbolic and interpretable rules in their differentiable network. The method is first to extract first-order logical facts from text observation and external word meaning network (ConceptNet), then train a policy in the network with directly interpretable logical operators. Our experimental results show RL training with the proposed method converges significantly faster than other state-of-the-art neuro-symbolic methods in a TextWorld benchmark.
Data-Efficient Framework for Real-world Multiple Sound Source 2D Localization
Dec 10, 2020
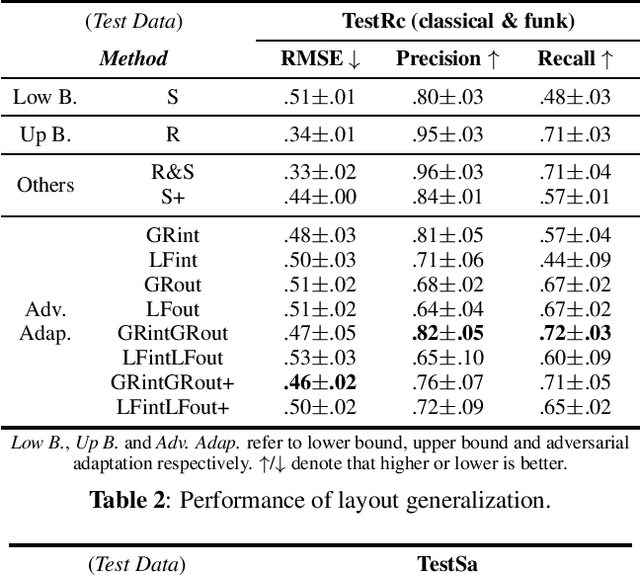
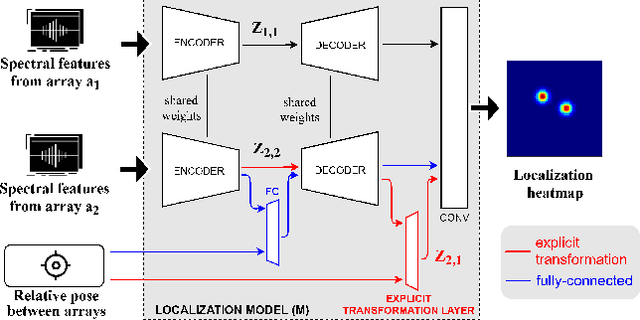
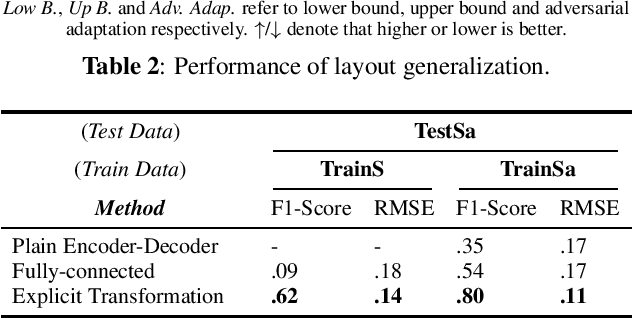
Deep neural networks have recently led to promising results for the task of multiple sound source localization. Yet, they require a lot of training data to cover a variety of acoustic conditions and microphone array layouts. One can leverage acoustic simulators to inexpensively generate labeled training data. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. Moreover, learning for different microphone array layouts makes the task more complicated due to the infinite number of possible layouts. We propose to use adversarial learning methods to close the gap between synthetic and real domains. Our novel ensemble-discrimination method significantly improves the localization performance without requiring any label from the real data. Furthermore, we propose a novel explicit transformation layer to be embedded in the localization architecture. It enables the model to be trained with data from specific microphone array layouts while generalizing well to unseen layouts during inference.
Ensemble of Discriminators for Domain Adaptation in Multiple Sound Source 2D Localization
Dec 10, 2020
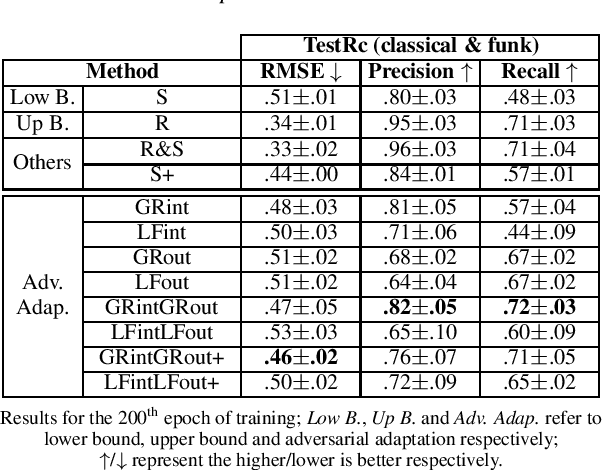
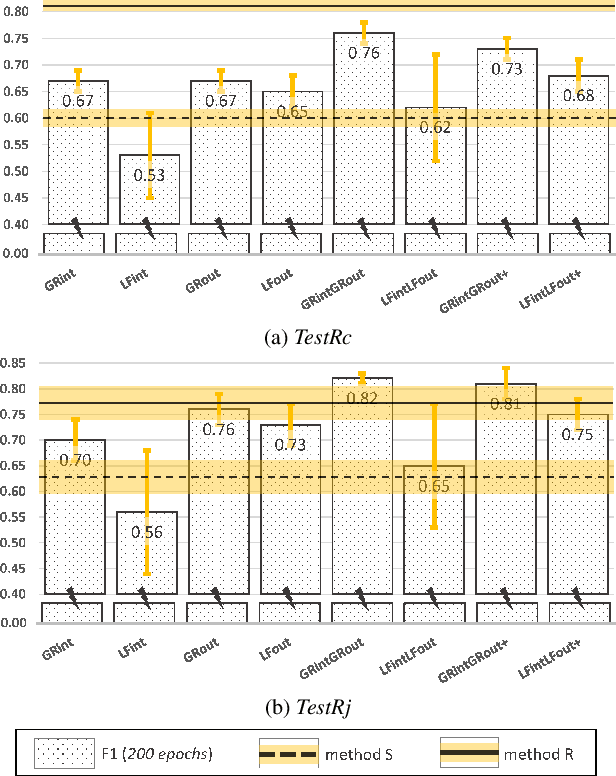
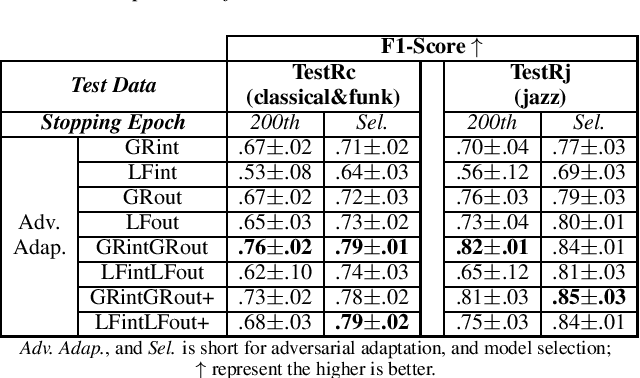
This paper introduces an ensemble of discriminators that improves the accuracy of a domain adaptation technique for the localization of multiple sound sources. Recently, deep neural networks have led to promising results for this task, yet they require a large amount of labeled data for training. Recording and labeling such datasets is very costly, especially because data needs to be diverse enough to cover different acoustic conditions. In this paper, we leverage acoustic simulators to inexpensively generate labeled training samples. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. For this, we explore two domain adaptation methods using adversarial learning for sound source localization which use labeled synthetic data and unlabeled real data. We propose a novel ensemble approach that combines discriminators applied at different feature levels of the localization model. Experiments show that our ensemble discrimination method significantly improves the localization performance without requiring any label from the real data.
Learning Multiple Sound Source 2D Localization
Dec 10, 2020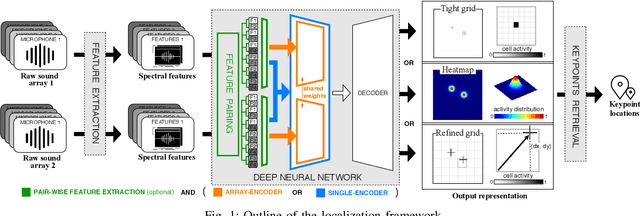
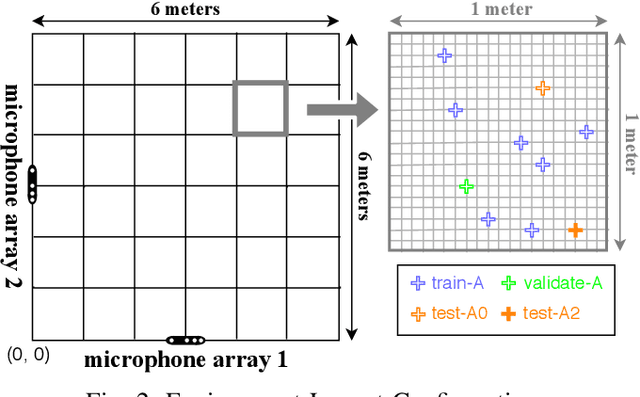
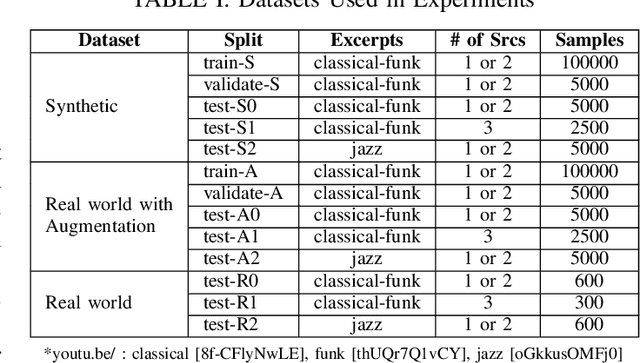
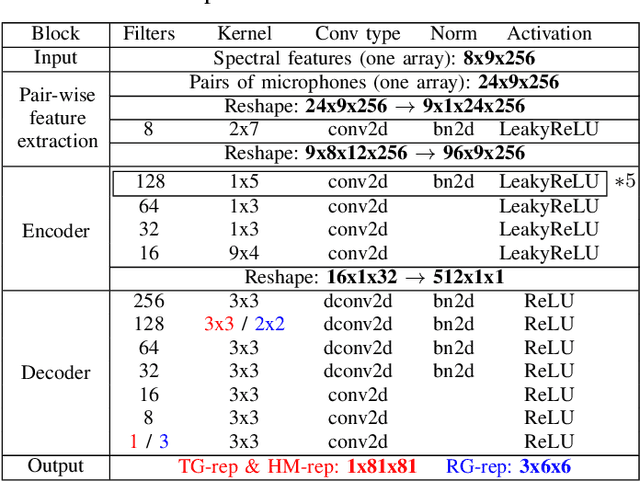
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy. Lastly, new metrics are developed relying on resolution-based multiple source association which enables us to evaluate and compare different localization approaches. We tested our method on both synthetic and real world data. The results show that our method improves upon the previous baseline approach for this problem.
Constrained Exploration and Recovery from Experience Shaping
Sep 21, 2018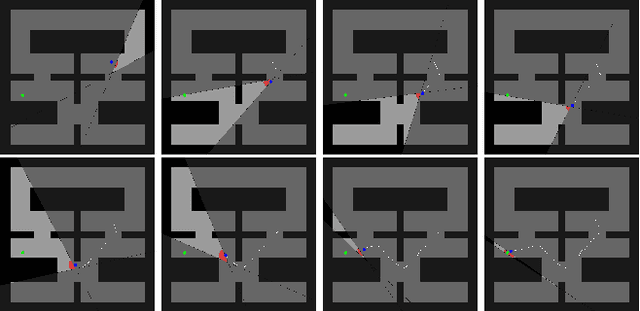
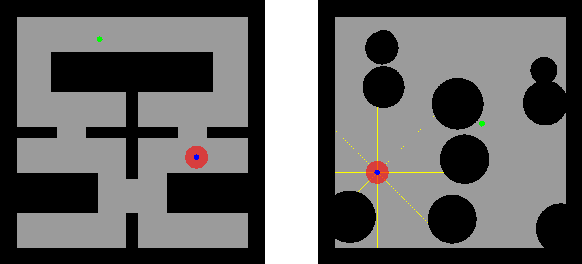

We consider the problem of reinforcement learning under safety requirements, in which an agent is trained to complete a given task, typically formalized as the maximization of a reward signal over time, while concurrently avoiding undesirable actions or states, associated to lower rewards, or penalties. The construction and balancing of different reward components can be difficult in the presence of multiple objectives, yet is crucial for producing a satisfying policy. For example, in reaching a target while avoiding obstacles, low collision penalties can lead to reckless movements while high penalties can discourage exploration. To circumvent this limitation, we examine the effect of past actions in terms of safety to estimate which are acceptable or should be avoided in the future. We then actively reshape the action space of the agent during reinforcement learning, so that reward-driven exploration is constrained within safety limits. We propose an algorithm enabling the learning of such safety constraints in parallel with reinforcement learning and demonstrate its effectiveness in terms of both task completion and training time.
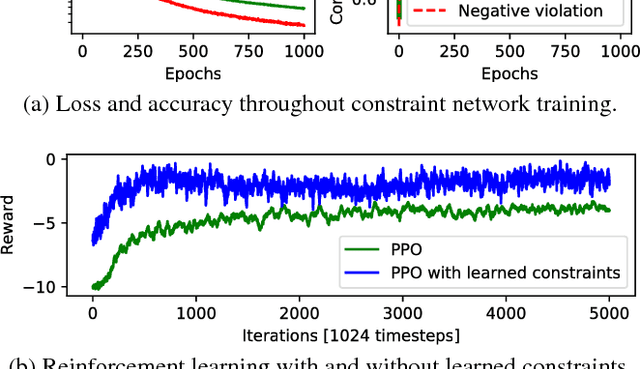
Deep Learning with Predictive Control for Human Motion Tracking
Aug 07, 2018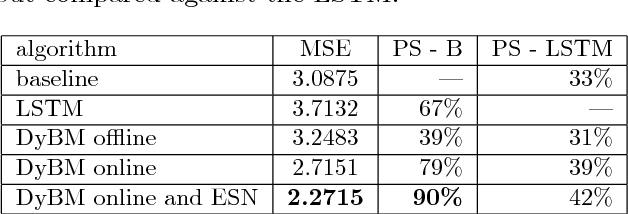
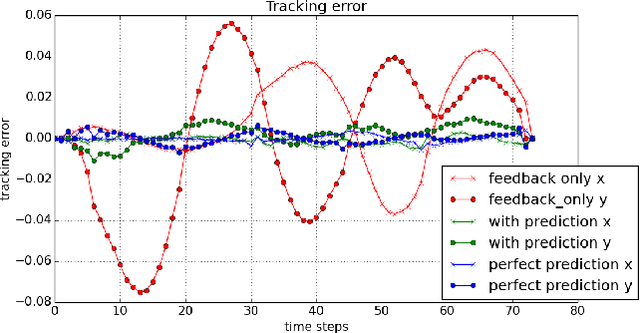
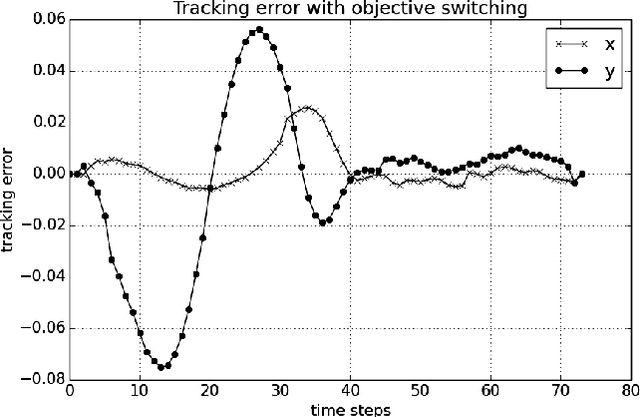
We propose to combine model predictive control with deep learning for the task of accurate human motion tracking with a robot. We design the MPC to allow switching between the learned and a conservative prediction. We also explored online learning with a DyBM model. We applied this method to human handwriting motion tracking with a UR-5 robot. The results show that the framework significantly improves tracking performance.