 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Would an LLM Do? Evaluating Policymaking Capabilities of Large Language Models
Sep 04, 2025Large language models (LLMs) are increasingly being adopted in high-stakes domains. Their capacity to process vast amounts of unstructured data, explore flexible scenarios, and handle a diversity of contextual factors can make them uniquely suited to provide new insights for the complexity of social policymaking. This article evaluates whether LLMs' are aligned with domain experts (and among themselves) to inform social policymaking on the subject of homelessness alleviation - a challenge affecting over 150 million people worldwide. We develop a novel benchmark comprised of decision scenarios with policy choices across four geographies (South Bend, USA; Barcelona, Spain; Johannesburg, South Africa; Macau SAR, China). The policies in scope are grounded in the conceptual framework of the Capability Approach for human development. We also present an automated pipeline that connects the benchmarked policies to an agent-based model, and we explore the social impact of the recommended policies through simulated social scenarios. The paper results reveal promising potential to leverage LLMs for social policy making. If responsible guardrails and contextual calibrations are introduced in collaboration with local domain experts, LLMs can provide humans with valuable insights, in the form of alternative policies at scale.
Knowledge Base Construction for Knowledge-Augmented Text-to-SQL
May 28, 2025Text-to-SQL aims to translate natural language queries into SQL statements, which is practical as it enables anyone to easily retrieve the desired information from databases. Recently, many existing approaches tackle this problem with Large Language Models (LLMs), leveraging their strong capability in understanding user queries and generating corresponding SQL code. Yet, the parametric knowledge in LLMs might be limited to covering all the diverse and domain-specific queries that require grounding in various database schemas, which makes generated SQLs less accurate oftentimes. To tackle this, we propose constructing the knowledge base for text-to-SQL, a foundational source of knowledge, from which we retrieve and generate the necessary knowledge for given queries. In particular, unlike existing approaches that either manually annotate knowledge or generate only a few pieces of knowledge for each query, our knowledge base is comprehensive, which is constructed based on a combination of all the available questions and their associated database schemas along with their relevant knowledge, and can be reused for unseen databases from different datasets and domains. We validate our approach on multiple text-to-SQL datasets, considering both the overlapping and non-overlapping database scenarios, where it outperforms relevant baselines substantially.
Less is More: Efficient Weight Farcasting with 1-Layer Neural Network
May 05, 2025Addressing the computational challenges inherent in training large-scale deep neural networks remains a critical endeavor in contemporary machine learning research. While previous efforts have focused on enhancing training efficiency through techniques such as gradient descent with momentum, learning rate scheduling, and weight regularization, the demand for further innovation continues to burgeon as model sizes keep expanding. In this study, we introduce a novel framework which diverges from conventional approaches by leveraging long-term time series forecasting techniques. Our method capitalizes solely on initial and final weight values, offering a streamlined alternative for complex model architectures. We also introduce a novel regularizer that is tailored to enhance the forecasting performance of our approach. Empirical evaluations conducted on synthetic weight sequences and real-world deep learning architectures, including the prominent large language model DistilBERT, demonstrate the superiority of our method in terms of forecasting accuracy and computational efficiency. Notably, our framework showcases improved performance while requiring minimal additional computational overhead, thus presenting a promising avenue for accelerating the training process across diverse tasks and architectures.
Q-function Decomposition with Intervention Semantics with Factored Action Spaces
Apr 30, 2025Many practical reinforcement learning environments have a discrete factored action space that induces a large combinatorial set of actions, thereby posing significant challenges. Existing approaches leverage the regular structure of the action space and resort to a linear decomposition of Q-functions, which avoids enumerating all combinations of factored actions. In this paper, we consider Q-functions defined over a lower dimensional projected subspace of the original action space, and study the condition for the unbiasedness of decomposed Q-functions using causal effect estimation from the no unobserved confounder setting in causal statistics. This leads to a general scheme which we call action decomposed reinforcement learning that uses the projected Q-functions to approximate the Q-function in standard model-free reinforcement learning algorithms. The proposed approach is shown to improve sample complexity in a model-based reinforcement learning setting. We demonstrate improvements in sample efficiency compared to state-of-the-art baselines in online continuous control environments and a real-world offline sepsis treatment environment.
FactReasoner: A Probabilistic Approach to Long-Form Factuality Assessment for Large Language Models
Feb 25, 2025


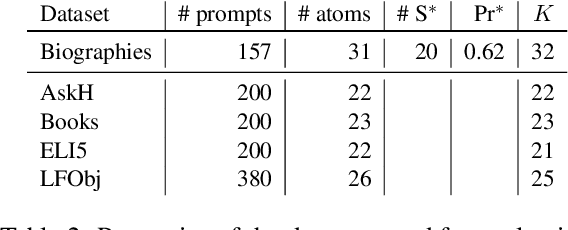
Large language models (LLMs) have demonstrated vast capabilities on generative tasks in recent years, yet they struggle with guaranteeing the factual correctness of the generated content. This makes these models unreliable in realistic situations where factually accurate responses are expected. In this paper, we propose FactReasoner, a new factuality assessor that relies on probabilistic reasoning to assess the factuality of a long-form generated response. Specifically, FactReasoner decomposes the response into atomic units, retrieves relevant contexts for them from an external knowledge source, and constructs a joint probability distribution over the atoms and contexts using probabilistic encodings of the logical relationships (entailment, contradiction) between the textual utterances corresponding to the atoms and contexts. FactReasoner then computes the posterior probability of whether atomic units in the response are supported by the retrieved contexts. Our experiments on labeled and unlabeled benchmark datasets demonstrate clearly that FactReasoner improves considerably over state-of-the-art prompt-based approaches in terms of both factual precision and recall.
Foundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning
Feb 02, 2024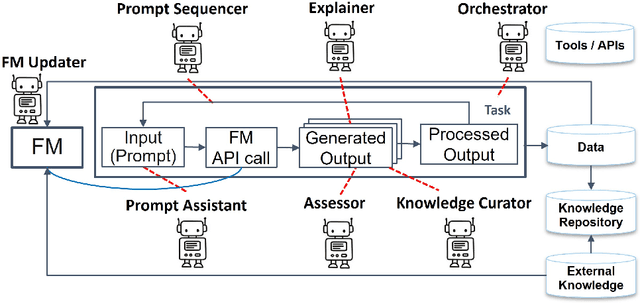


Foundation models (FMs) such as large language models have revolutionized the field of AI by showing remarkable performance in various tasks. However, they exhibit numerous limitations that prevent their broader adoption in many real-world systems, which often require a higher bar for trustworthiness and usability. Since FMs are trained using loss functions aimed at reconstructing the training corpus in a self-supervised manner, there is no guarantee that the model's output aligns with users' preferences for a specific task at hand. In this survey paper, we propose a conceptual framework that encapsulates different modes by which agents could interact with FMs and guide them suitably for a set of tasks, particularly through knowledge augmentation and reasoning. Our framework elucidates agent role categories such as updating the underlying FM, assisting with prompting the FM, and evaluating the FM output. We also categorize several state-of-the-art approaches into agent interaction protocols, highlighting the nature and extent of involvement of the various agent roles. The proposed framework provides guidance for future directions to further realize the power of FMs in practical AI systems.
Self-Supervised Contrastive Pre-Training for Multivariate Point Processes
Feb 01, 2024Self-supervision is one of the hallmarks of representation learning in the increasingly popular suite of foundation models including large language models such as BERT and GPT-3, but it has not been pursued in the context of multivariate event streams, to the best of our knowledge. We introduce a new paradigm for self-supervised learning for multivariate point processes using a transformer encoder. Specifically, we design a novel pre-training strategy for the encoder where we not only mask random event epochs but also insert randomly sampled "void" epochs where an event does not occur; this differs from the typical discrete-time pretext tasks such as word-masking in BERT but expands the effectiveness of masking to better capture continuous-time dynamics. To improve downstream tasks, we introduce a contrasting module that compares real events to simulated void instances. The pre-trained model can subsequently be fine-tuned on a potentially much smaller event dataset, similar conceptually to the typical transfer of popular pre-trained language models. We demonstrate the effectiveness of our proposed paradigm on the next-event prediction task using synthetic datasets and 3 real applications, observing a relative performance boost of as high as up to 20% compared to state-of-the-art models.
Distilling Event Sequence Knowledge From Large Language Models
Jan 14, 2024



Event sequence models have been found to be highly effective in the analysis and prediction of events. Building such models requires availability of abundant high-quality event sequence data. In certain applications, however, clean structured event sequences are not available, and automated sequence extraction results in data that is too noisy and incomplete. In this work, we explore the use of Large Language Models (LLMs) to generate event sequences that can effectively be used for probabilistic event model construction. This can be viewed as a mechanism of distilling event sequence knowledge from LLMs. Our approach relies on a Knowledge Graph (KG) of event concepts with partial causal relations to guide the generative language model for causal event sequence generation. We show that our approach can generate high-quality event sequences, filling a knowledge gap in the input KG. Furthermore, we explore how the generated sequences can be leveraged to discover useful and more complex structured knowledge from pattern mining and probabilistic event models. We release our sequence generation code and evaluation framework, as well as corpus of event sequence data.
Event Prediction using Case-Based Reasoning over Knowledge Graphs
Sep 21, 2023



Applying link prediction (LP) methods over knowledge graphs (KG) for tasks such as causal event prediction presents an exciting opportunity. However, typical LP models are ill-suited for this task as they are incapable of performing inductive link prediction for new, unseen event entities and they require retraining as knowledge is added or changed in the underlying KG. We introduce a case-based reasoning model, EvCBR, to predict properties about new consequent events based on similar cause-effect events present in the KG. EvCBR uses statistical measures to identify similar events and performs path-based predictions, requiring no training step. To generalize our methods beyond the domain of event prediction, we frame our task as a 2-hop LP task, where the first hop is a causal relation connecting a cause event to a new effect event and the second hop is a property about the new event which we wish to predict. The effectiveness of our method is demonstrated using a novel dataset of newsworthy events with causal relations curated from Wikidata, where EvCBR outperforms baselines including translational-distance-based, GNN-based, and rule-based LP models.
Summary Markov Models for Event Sequences
May 06, 2022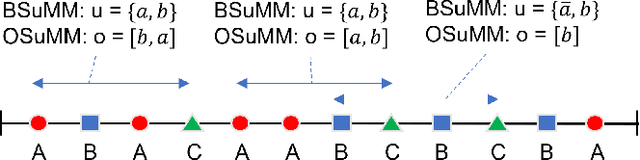

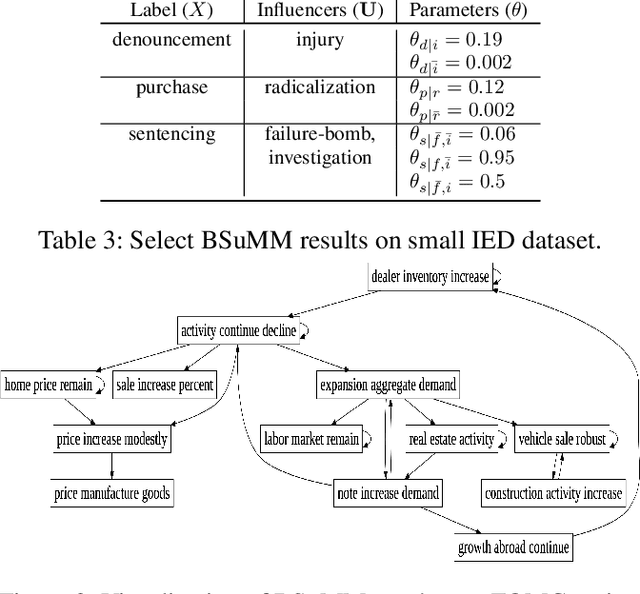
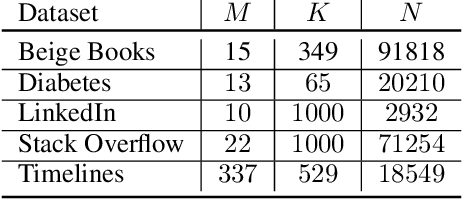
Datasets involving sequences of different types of events without meaningful time stamps are prevalent in many applications, for instance when extracted from textual corpora. We propose a family of models for such event sequences -- summary Markov models -- where the probability of observing an event type depends only on a summary of historical occurrences of its influencing set of event types. This Markov model family is motivated by Granger causal models for time series, with the important distinction that only one event can occur in a position in an event sequence. We show that a unique minimal influencing set exists for any set of event types of interest and choice of summary function, formulate two novel models from the general family that represent specific sequence dynamics, and propose a greedy search algorithm for learning them from event sequence data. We conduct an experimental investigation comparing the proposed models with relevant baselines, and illustrate their knowledge acquisition and discovery capabilities through case studies involving sequences from text.