 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Deep Predicate Invention with Pre-trained Foundation Models
Dec 19, 2025Long-horizon robotic tasks are hard due to continuous state-action spaces and sparse feedback. Symbolic world models help by decomposing tasks into discrete predicates that capture object properties and relations. Existing methods learn predicates either top-down, by prompting foundation models without data grounding, or bottom-up, from demonstrations without high-level priors. We introduce UniPred, a bilevel learning framework that unifies both. UniPred uses large language models (LLMs) to propose predicate effect distributions that supervise neural predicate learning from low-level data, while learned feedback iteratively refines the LLM hypotheses. Leveraging strong visual foundation model features, UniPred learns robust predicate classifiers in cluttered scenes. We further propose a predicate evaluation method that supports symbolic models beyond STRIPS assumptions. Across five simulated and one real-robot domains, UniPred achieves 2-4 times higher success rates than top-down methods and 3-4 times faster learning than bottom-up approaches, advancing scalable and flexible symbolic world modeling for robotics.
Bilevel Learning for Bilevel Planning
Feb 12, 2025A robot that learns from demonstrations should not just imitate what it sees -- it should understand the high-level concepts that are being demonstrated and generalize them to new tasks. Bilevel planning is a hierarchical model-based approach where predicates (relational state abstractions) can be leveraged to achieve compositional generalization. However, previous bilevel planning approaches depend on predicates that are either hand-engineered or restricted to very simple forms, limiting their scalability to sophisticated, high-dimensional state spaces. To address this limitation, we present IVNTR, the first bilevel planning approach capable of learning neural predicates directly from demonstrations. Our key innovation is a neuro-symbolic bilevel learning framework that mirrors the structure of bilevel planning. In IVNTR, symbolic learning of the predicate "effects" and neural learning of the predicate "functions" alternate, with each providing guidance for the other. We evaluate IVNTR in six diverse robot planning domains, demonstrating its effectiveness in abstracting various continuous and high-dimensional states. While most existing approaches struggle to generalize (with <35% success rate), our IVNTR achieves an average of 77% success rate on unseen tasks. Additionally, we showcase IVNTR on a mobile manipulator, where it learns to perform real-world mobile manipulation tasks and generalizes to unseen test scenarios that feature new objects, new states, and longer task horizons. Our findings underscore the promise of learning and planning with abstractions as a path towards high-level generalization.
Few-shot Policy (de)composition in Conversational Question Answering
Jan 20, 2025



The task of policy compliance detection (PCD) is to determine if a scenario is in compliance with respect to a set of written policies. In a conversational setting, the results of PCD can indicate if clarifying questions must be asked to determine compliance status. Existing approaches usually claim to have reasoning capabilities that are latent or require a large amount of annotated data. In this work, we propose logical decomposition for policy compliance (LDPC): a neuro-symbolic framework to detect policy compliance using large language models (LLMs) in a few-shot setting. By selecting only a few exemplars alongside recently developed prompting techniques, we demonstrate that our approach soundly reasons about policy compliance conversations by extracting sub-questions to be answered, assigning truth values from contextual information, and explicitly producing a set of logic statements from the given policies. The formulation of explicit logic graphs can in turn help answer PCDrelated questions with increased transparency and explainability. We apply this approach to the popular PCD and conversational machine reading benchmark, ShARC, and show competitive performance with no task-specific finetuning. We also leverage the inherently interpretable architecture of LDPC to understand where errors occur, revealing ambiguities in the ShARC dataset and highlighting the challenges involved with reasoning for conversational question answering.
Neural Reasoning Networks: Efficient Interpretable Neural Networks With Automatic Textual Explanations
Oct 10, 2024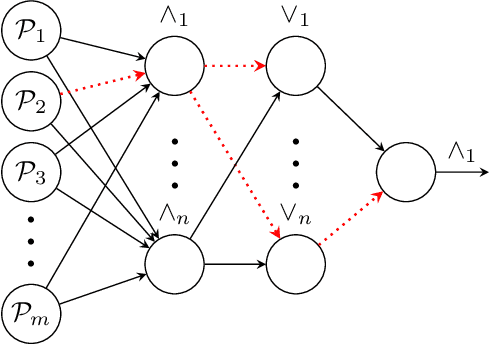

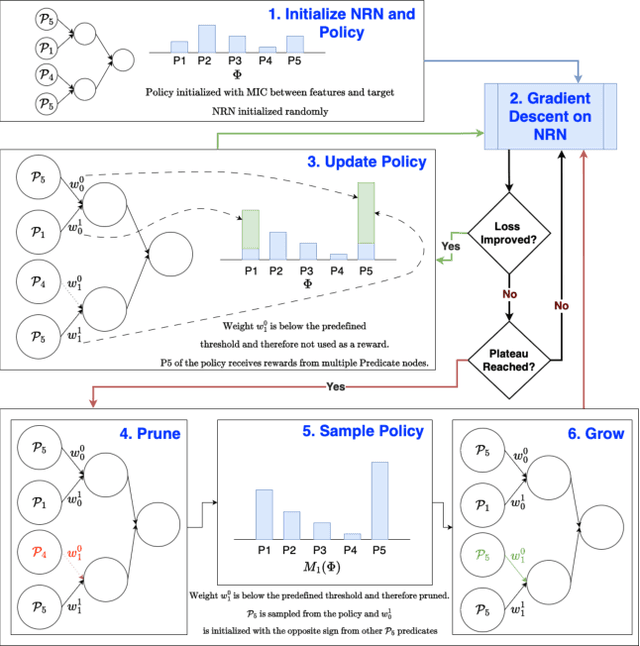

Recent advances in machine learning have led to a surge in adoption of neural networks for various tasks, but lack of interpretability remains an issue for many others in which an understanding of the features influencing the prediction is necessary to ensure fairness, safety, and legal compliance. In this paper we consider one class of such tasks, tabular dataset classification, and propose a novel neuro-symbolic architecture, Neural Reasoning Networks (NRN), that is scalable and generates logically sound textual explanations for its predictions. NRNs are connected layers of logical neurons which implement a form of real valued logic. A training algorithm (R-NRN) learns the weights of the network as usual using gradient descent optimization with backprop, but also learns the network structure itself using a bandit-based optimization. Both are implemented in an extension to PyTorch (https://github.com/IBM/torchlogic) that takes full advantage of GPU scaling and batched training. Evaluation on a diverse set of 22 open-source datasets for tabular classification demonstrates performance (measured by ROC AUC) which improves over multi-layer perceptron (MLP) and is statistically similar to other state-of-the-art approaches such as Random Forest, XGBoost and Gradient Boosted Trees, while offering 43% faster training and a more than 2 orders of magnitude reduction in the number of parameters required, on average. Furthermore, R-NRN explanations are shorter than the compared approaches while producing more accurate feature importance scores.
Evaluating Ensemble Methods for News Recommender Systems
Jun 23, 2024



News recommendation is crucial for facilitating individuals' access to articles, particularly amid the increasingly digital landscape of news consumption. Consequently, extensive research is dedicated to News Recommender Systems (NRS) with increasingly sophisticated algorithms. Despite this sustained scholarly inquiry, there exists a notable research gap regarding the potential synergy achievable by amalgamating these algorithms to yield superior outcomes. This paper endeavours to address this gap by demonstrating how ensemble methods can be used to combine many diverse state-of-the-art algorithms to achieve superior results on the Microsoft News dataset (MIND). Additionally, we identify scenarios where ensemble methods fail to improve results and offer explanations for this occurrence. Our findings demonstrate that a combination of NRS algorithms can outperform individual algorithms, provided that the base learners are sufficiently diverse, with improvements of up to 5\% observed for an ensemble consisting of a content-based BERT approach and the collaborative filtering LSTUR algorithm. Additionally, our results demonstrate the absence of any improvement when combining insufficiently distinct methods. These findings provide insight into successful approaches of ensemble methods in NRS and advocates for the development of better systems through appropriate ensemble solutions.
A Neuro-Symbolic Approach to Multi-Agent RL for Interpretability and Probabilistic Decision Making
Feb 21, 2024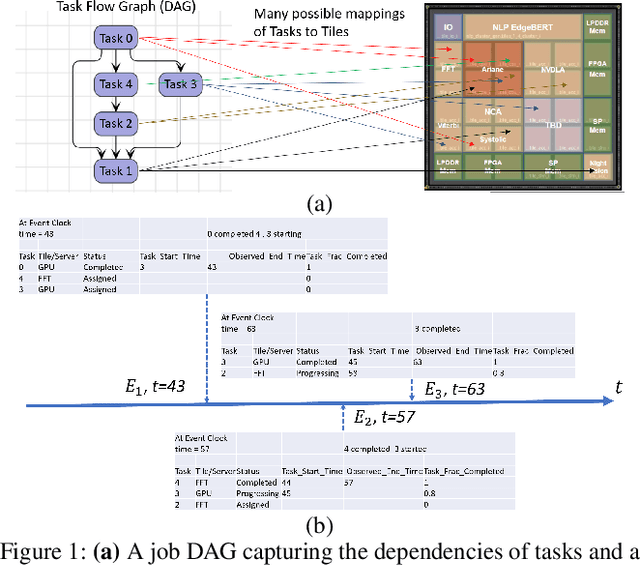
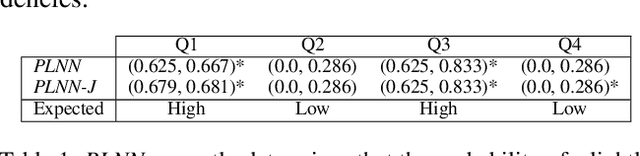

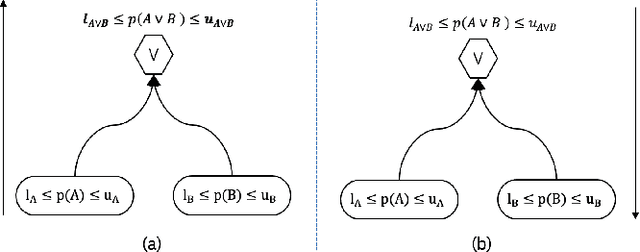
Multi-agent reinforcement learning (MARL) is well-suited for runtime decision-making in optimizing the performance of systems where multiple agents coexist and compete for shared resources. However, applying common deep learning-based MARL solutions to real-world problems suffers from issues of interpretability, sample efficiency, partial observability, etc. To address these challenges, we present an event-driven formulation, where decision-making is handled by distributed co-operative MARL agents using neuro-symbolic methods. The recently introduced neuro-symbolic Logical Neural Networks (LNN) framework serves as a function approximator for the RL, to train a rules-based policy that is both logical and interpretable by construction. To enable decision-making under uncertainty and partial observability, we developed a novel probabilistic neuro-symbolic framework, Probabilistic Logical Neural Networks (PLNN), which combines the capabilities of logical reasoning with probabilistic graphical models. In PLNN, the upward/downward inference strategy, inherited from LNN, is coupled with belief bounds by setting the activation function for the logical operator associated with each neural network node to a probability-respecting generalization of the Fr\'echet inequalities. These PLNN nodes form the unifying element that combines probabilistic logic and Bayes Nets, permitting inference for variables with unobserved states. We demonstrate our contributions by addressing key MARL challenges for power sharing in a system-on-chip application.
Compositional Program Generation for Systematic Generalization
Sep 28, 2023
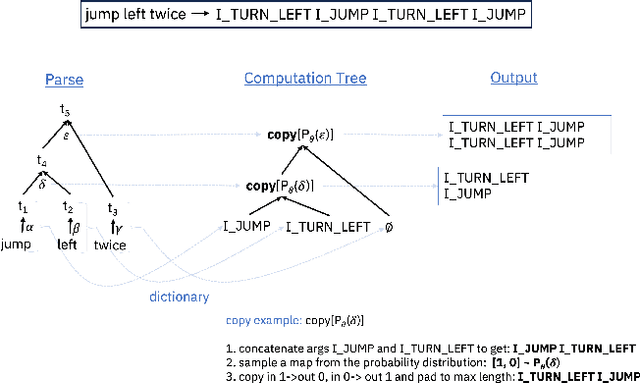
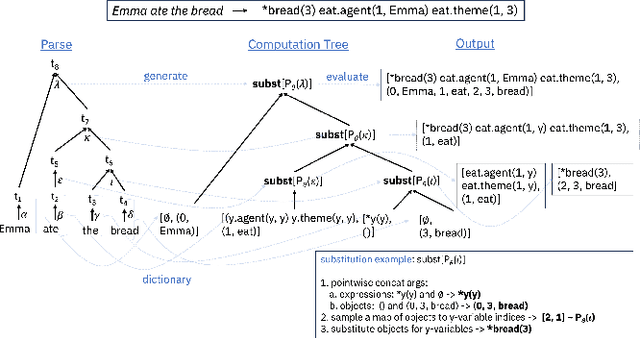

Compositional generalization is a key ability of humans that enables us to learn new concepts from only a handful examples. Machine learning models, including the now ubiquitous transformers, struggle to generalize in this way, and typically require thousands of examples of a concept during training in order to generalize meaningfully. This difference in ability between humans and artificial neural architectures, motivates this study on a neuro-symbolic architecture called the Compositional Program Generator (CPG). CPG has three key features: modularity, type abstraction, and recursive composition, that enable it to generalize both systematically to new concepts in a few-shot manner, as well as productively by length on various sequence-to-sequence language tasks. For each input, CPG uses a grammar of the input domain and a parser to generate a type hierarchy in which each grammar rule is assigned its own unique semantic module, a probabilistic copy or substitution program. Instances with the same hierarchy are processed with the same composed program, while those with different hierarchies may be processed with different programs. CPG learns parameters for the semantic modules and is able to learn the semantics for new types incrementally. Given a context-free grammar of the input language and a dictionary mapping each word in the source language to its interpretation in the output language, CPG can achieve perfect generalization on the SCAN and COGS benchmarks, in both standard and extreme few-shot settings.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023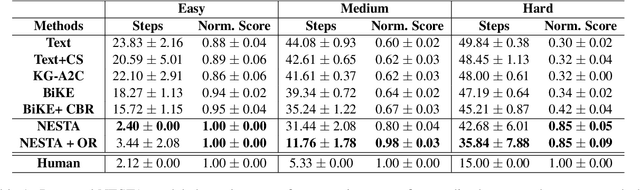
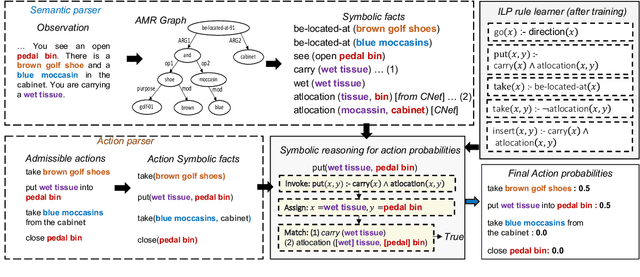
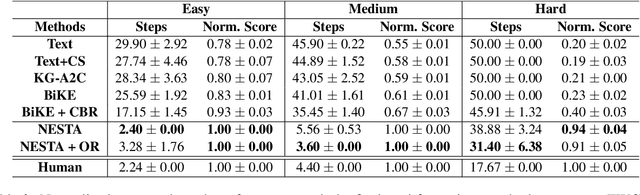
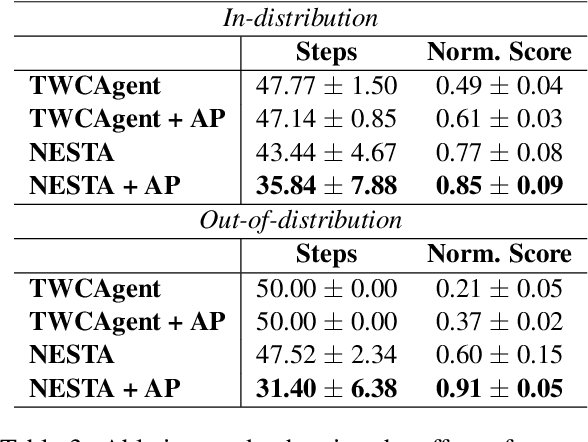
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
Scalable Learning of Latent Language Structure With Logical Offline Cycle Consistency
May 31, 2023



We introduce Logical Offline Cycle Consistency Optimization (LOCCO), a scalable, semi-supervised method for training a neural semantic parser. Conceptually, LOCCO can be viewed as a form of self-learning where the semantic parser being trained is used to generate annotations for unlabeled text that are then used as new supervision. To increase the quality of annotations, our method utilizes a count-based prior over valid formal meaning representations and a cycle-consistency score produced by a neural text generation model as additional signals. Both the prior and semantic parser are updated in an alternate fashion from full passes over the training data, which can be seen as approximating the marginalization of latent structures through stochastic variational inference. The use of a count-based prior, frozen text generation model, and offline annotation process yields an approach with negligible complexity and latency increases as compared to conventional self-learning. As an added bonus, the annotations produced by LOCCO can be trivially repurposed to train a neural text generation model. We demonstrate the utility of LOCCO on the well-known WebNLG benchmark where we obtain an improvement of 2 points against a self-learning parser under equivalent conditions, an improvement of 1.3 points against the previous state-of-the-art parser, and competitive text generation performance in terms of BLEU score.