 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemStruct: Contextualizing Semantic Embeddings with Structural Information for Schema Matching
May 29, 2026Schema matching is a fundamental step in integrating heterogeneous data sources. While Pre-trained Language Models (PLMs) have revolutionized this task by capturing linguistic semantics, they typically process tabular data as serialized text sequences of standalone column descriptions. This serialization discards critical structural information -- specifically, the row-level co-occurrences, i.e. the relational context -- forcing models to rely solely on column header semantics or standalone distributions. To bridge this gap, we propose SemStruct, a framework that joins the semantic power of frozen PLMs with the structural inductive bias of Graph Neural Networks (GNNs). We model the table as a heterogeneous graph where columns and values are nodes connected by rows, allowing the GNN to propagate disambiguating context across the structure. Unlike other state-of-the-art methods that require proprietary LLM access and fine-tuning of language models, SemStruct keeps the language model frozen and trains only a lightweight structural encoder. Extensive experiments on the Valentine and SOTAB-SM benchmarks demonstrate that SemStruct achieves state-of-the-art performance, outperforming fully fine-tuned baselines on complex, semantically joinable datasets. Furthermore, our ablation studies reveal that row representations serve primarily as topological conduits rather than semantic entities, validating the necessity of explicit structural modeling in schema matching.
Automatic Prompt Engineering with No Task Cues and No Tuning
Jan 06, 2026This paper presents a system for automatic prompt engineering that is much simpler in both design and application and yet as effective as the existing approaches. It requires no tuning and no explicit clues about the task. We evaluated our approach on cryptic column name expansion (CNE) in database tables, a task which is critical for tabular data search, access, and understanding and yet there has been very little existing work. We evaluated on datasets in two languages, English and German. This is the first work to report on the application of automatic prompt engineering for the CNE task. To the best of our knowledge, this is also the first work on the application of automatic prompt engineering for a language other than English.
DP-Bench: A Benchmark for Evaluating Data Product Creation Systems
Dec 16, 2025A data product is created with the intention of solving a specific problem, addressing a specific business usecase or meeting a particular need, going beyond just serving data as a raw asset. Data products enable end users to gain greater insights about their data. Since it was first introduced over a decade ago, there has been considerable work, especially in industry, to create data products manually or semi-automatically. However, there exists hardly any benchmark to evaluate automatic data product creation. In this work, we present a benchmark, first of its kind, for this task. We call it DP-Bench. We describe how this benchmark was created by taking advantage of existing work in ELT (Extract-Load-Transform) and Text-to-SQL benchmarks. We also propose a number of LLM based approaches that can be considered as baselines for generating data products automatically. We make the DP-Bench and supplementary materials available in https://huggingface.co/datasets/ibm-research/dp-bench .
Automatic Prompt Optimization for Knowledge Graph Construction: Insights from an Empirical Study
Jun 24, 2025A KG represents a network of entities and illustrates relationships between them. KGs are used for various applications, including semantic search and discovery, reasoning, decision-making, natural language processing, machine learning, and recommendation systems. Triple (subject-relation-object) extraction from text is the fundamental building block of KG construction and has been widely studied, for example, in early benchmarks such as ACE 2002 to more recent ones, such as WebNLG 2020, REBEL and SynthIE. While the use of LLMs is explored for KG construction, handcrafting reasonable task-specific prompts for LLMs is a labour-intensive exercise and can be brittle due to subtle changes in the LLM models employed. Recent work in NLP tasks (e.g. autonomy generation) uses automatic prompt optimization/engineering to address this challenge by generating optimal or near-optimal task-specific prompts given input-output examples. This empirical study explores the application of automatic prompt optimization for the triple extraction task using experimental benchmarking. We evaluate different settings by changing (a) the prompting strategy, (b) the LLM being used for prompt optimization and task execution, (c) the number of canonical relations in the schema (schema complexity), (d) the length and diversity of input text, (e) the metric used to drive the prompt optimization, and (f) the dataset being used for training and testing. We evaluate three different automatic prompt optimizers, namely, DSPy, APE, and TextGrad and use two different triple extraction datasets, SynthIE and REBEL. Through rigorous empirical evaluation, our main contribution highlights that automatic prompt optimization techniques can generate reasonable prompts similar to humans for triple extraction. In turn, these optimized prompts achieve improved results, particularly with increasing schema complexity and text size.
Domain specific ontologies from Linked Open Data (LOD)
May 28, 2025Logical and probabilistic reasoning tasks that require a deeper knowledge of semantics are increasingly relying on general purpose ontologies such as Wikidata and DBpedia. However, tasks such as entity disambiguation and linking may benefit from domain specific knowledge graphs, which make it more efficient to consume the knowledge and easier to extend with proprietary content. We discuss our experience bootstrapping one such ontology for IT with a domain-agnostic pipeline, and extending it using domain-specific glossaries.
Scholarly Wikidata: Population and Exploration of Conference Data in Wikidata using LLMs
Nov 13, 2024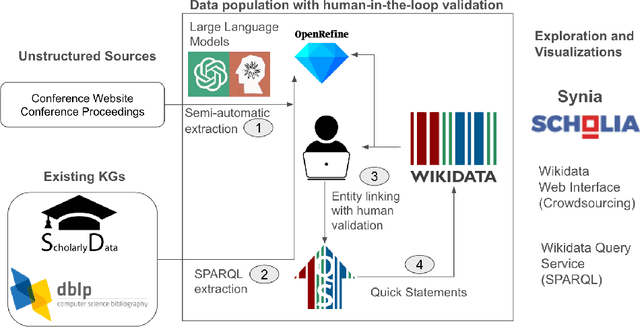
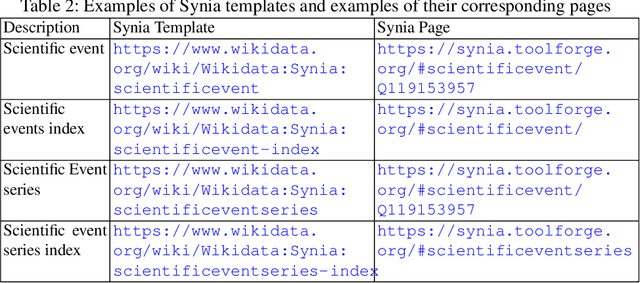

Several initiatives have been undertaken to conceptually model the domain of scholarly data using ontologies and to create respective Knowledge Graphs. Yet, the full potential seems unleashed, as automated means for automatic population of said ontologies are lacking, and respective initiatives from the Semantic Web community are not necessarily connected: we propose to make scholarly data more sustainably accessible by leveraging Wikidata's infrastructure and automating its population in a sustainable manner through LLMs by tapping into unstructured sources like conference Web sites and proceedings texts as well as already existing structured conference datasets. While an initial analysis shows that Semantic Web conferences are only minimally represented in Wikidata, we argue that our methodology can help to populate, evolve and maintain scholarly data as a community within Wikidata. Our main contributions include (a) an analysis of ontologies for representing scholarly data to identify gaps and relevant entities/properties in Wikidata, (b) semi-automated extraction -- requiring (minimal) manual validation -- of conference metadata (e.g., acceptance rates, organizer roles, programme committee members, best paper awards, keynotes, and sponsors) from websites and proceedings texts using LLMs. Finally, we discuss (c) extensions to visualization tools in the Wikidata context for data exploration of the generated scholarly data. Our study focuses on data from 105 Semantic Web-related conferences and extends/adds more than 6000 entities in Wikidata. It is important to note that the method can be more generally applicable beyond Semantic Web-related conferences for enhancing Wikidata's utility as a comprehensive scholarly resource. Source Repository: https://github.com/scholarly-wikidata/ DOI: https://doi.org/10.5281/zenodo.10989709 License: Creative Commons CC0 (Data), MIT (Code)
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Jun 12, 2024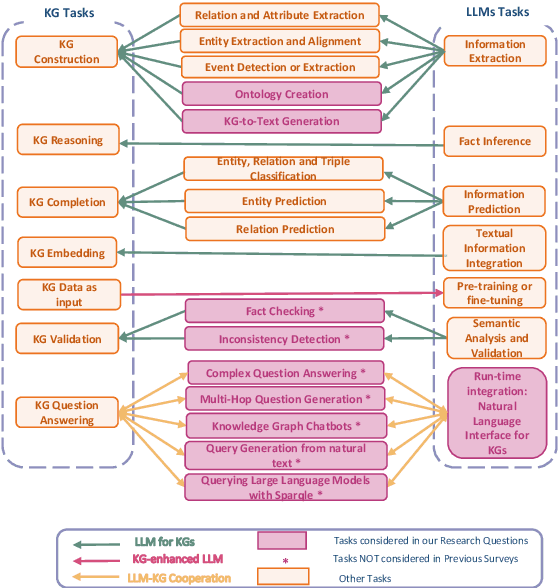
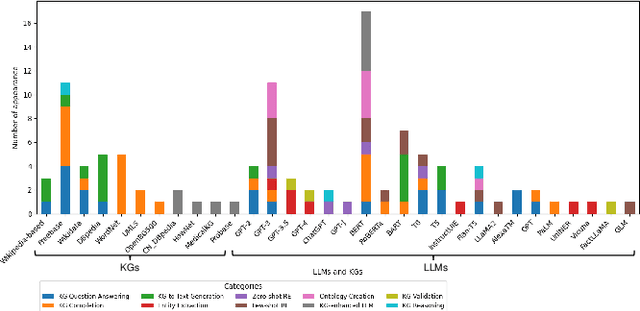
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
Matching Table Metadata with Business Glossaries Using Large Language Models
Sep 08, 2023



Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text
Aug 04, 2023
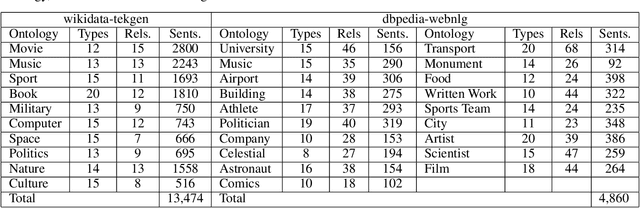


The recent advances in large language models (LLM) and foundation models with emergent capabilities have been shown to improve the performance of many NLP tasks. LLMs and Knowledge Graphs (KG) can complement each other such that LLMs can be used for KG construction or completion while existing KGs can be used for different tasks such as making LLM outputs explainable or fact-checking in Neuro-Symbolic manner. In this paper, we present Text2KGBench, a benchmark to evaluate the capabilities of language models to generate KGs from natural language text guided by an ontology. Given an input ontology and a set of sentences, the task is to extract facts from the text while complying with the given ontology (concepts, relations, domain/range constraints) and being faithful to the input sentences. We provide two datasets (i) Wikidata-TekGen with 10 ontologies and 13,474 sentences and (ii) DBpedia-WebNLG with 19 ontologies and 4,860 sentences. We define seven evaluation metrics to measure fact extraction performance, ontology conformance, and hallucinations by LLMs. Furthermore, we provide results for two baseline models, Vicuna-13B and Alpaca-LoRA-13B using automatic prompt generation from test cases. The baseline results show that there is room for improvement using both Semantic Web and Natural Language Processing techniques.
Finspector: A Human-Centered Visual Inspection Tool for Exploring and Comparing Biases among Foundation Models
May 26, 2023

Pre-trained transformer-based language models are becoming increasingly popular due to their exceptional performance on various benchmarks. However, concerns persist regarding the presence of hidden biases within these models, which can lead to discriminatory outcomes and reinforce harmful stereotypes. To address this issue, we propose Finspector, a human-centered visual inspection tool designed to detect biases in different categories through log-likelihood scores generated by language models. The goal of the tool is to enable researchers to easily identify potential biases using visual analytics, ultimately contributing to a fairer and more just deployment of these models in both academic and industrial settings. Finspector is available at https://github.com/IBM/finspector.