 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain specific ontologies from Linked Open Data (LOD)
May 28, 2025Logical and probabilistic reasoning tasks that require a deeper knowledge of semantics are increasingly relying on general purpose ontologies such as Wikidata and DBpedia. However, tasks such as entity disambiguation and linking may benefit from domain specific knowledge graphs, which make it more efficient to consume the knowledge and easier to extend with proprietary content. We discuss our experience bootstrapping one such ontology for IT with a domain-agnostic pipeline, and extending it using domain-specific glossaries.
Incremental Analysis of Legacy Applications Using Knowledge Graphs for Application Modernization
May 11, 2025



Industries such as banking, telecom, and airlines - o6en have large so6ware systems that are several decades old. Many of these systems are written in old programming languages such as COBOL, PL/1, Assembler, etc. In many cases, the documentation is not updated, and those who developed/designed these systems are no longer around. Understanding these systems for either modernization or even regular maintenance has been a challenge. An extensive application may have natural boundaries based on its code dependencies and architecture. There are also other logical boundaries in an enterprise setting driven by business functions, data domains, etc. Due to these complications, the system architects generally plan their modernization across these logical boundaries in parts, thereby adopting an incremental approach for the modernization journey of the entire system. In this work, we present a so6ware system analysis tool that allows a subject ma=er expert (SME) or system architect to analyze a large so6ware system incrementally. We analyze the source code and other artifacts (such as data schema) to create a knowledge graph using a customizable ontology/schema. Entities and relations in our ontology can be defined for any combination of programming languages and platforms. Using this knowledge graph, the analyst can then define logical boundaries around dependent Entities (e.g. Programs, Transactions, Database Tables etc.). Our tool then presents different views showcasing the dependencies from the newly defined boundary to/from the other logical groups of the system. This exercise is repeated interactively to 1) Identify the Entities and groupings of interest for a modernization task and 2) Understand how a change in one part of the system may affect the other parts. To validate the efficacy of our tool, we provide an initial study of our system on two client applications.
Constructing Micro Knowledge Graphs from Technical Support Documents
Apr 14, 2025Short technical support pages such as IBM Technotes are quite common in technical support domain. These pages can be very useful as the knowledge sources for technical support applications such as chatbots, search engines and question-answering (QA) systems. Information extracted from documents to drive technical support applications is often stored in the form of Knowledge Graph (KG). Building KGs from a large corpus of documents poses a challenge of granularity because a large number of entities and actions are present in each page. The KG becomes virtually unusable if all entities and actions from these pages are stored in the KG. Therefore, only key entities and actions from each page are extracted and stored in the KG. This approach however leads to loss of knowledge represented by entities and actions left out of the KG as they are no longer available to graph search and reasoning functions. We propose a set of techniques to create micro knowledge graph (micrograph) for each of such web pages. The micrograph stores all the entities and actions in a page and also takes advantage of the structure of the page to represent exactly in which part of that page these entities and actions appeared, and also how they relate to each other. These micrographs can be used as additional knowledge sources by technical support applications. We define schemas for representing semi-structured and plain text knowledge present in the technical support web pages. Solutions in technical support domain include procedures made of steps. We also propose a technique to extract procedures from these webpages and the schemas to represent them in the micrographs. We also discuss how technical support applications can take advantage of the micrographs.
Automated Testing of COBOL to Java Transformation
Apr 14, 2025Recent advances in Large Language Model (LLM) based Generative AI techniques have made it feasible to translate enterprise-level code from legacy languages such as COBOL to modern languages such as Java or Python. While the results of LLM-based automatic transformation are encouraging, the resulting code cannot be trusted to correctly translate the original code, making manual validation of translated Java code from COBOL a necessary but time-consuming and labor-intensive process. In this paper, we share our experience of developing a testing framework for IBM Watsonx Code Assistant for Z (WCA4Z) [5], an industrial tool designed for COBOL to Java translation. The framework automates the process of testing the functional equivalence of the translated Java code against the original COBOL programs in an industry context. Our framework uses symbolic execution to generate unit tests for COBOL, mocking external calls and transforming them into JUnit tests to validate semantic equivalence with translated Java. The results not only help identify and repair any detected discrepancies but also provide feedback to improve the AI model.
Quantum neural networks facilitating quantum state classification
Apr 09, 2025The classification of quantum states into distinct classes poses a significant challenge. In this study, we address this problem using quantum neural networks in combination with a problem-inspired circuit and customised as well as predefined ans\"{a}tz. To facilitate the resource-efficient quantum state classification, we construct the dataset of quantum states using the proposed problem-inspired circuit. The problem-inspired circuit incorporates two-qubit parameterised unitary gates of varying entangling power, which is further integrated with the ans\"{a}tz, developing an entire quantum neural network. To demonstrate the capability of the selected ans\"{a}tz, we visualise the mitigated barren plateaus. The designed quantum neural network demonstrates the efficiency in binary and multi-class classification tasks. This work establishes a foundation for the classification of multi-qubit quantum states and offers the potential for generalisation to multi-qubit pure quantum states.
CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs
Nov 21, 2024



Machine Learning (ML) for software engineering (SE) has gained prominence due to its ability to significantly enhance the performance of various SE applications. This progress is largely attributed to the development of generalizable source code representations that effectively capture the syntactic and semantic characteristics of code. In recent years, pre-trained transformer-based models, inspired by natural language processing (NLP), have shown remarkable success in SE tasks. However, source code contains structural and semantic properties embedded within its grammar, which can be extracted from structured code-views like the Abstract Syntax Tree (AST), Data-Flow Graph (DFG), and Control-Flow Graph (CFG). These code-views can complement NLP techniques, further improving SE tasks. Unfortunately, there are no flexible frameworks to infuse arbitrary code-views into existing transformer-based models effectively. Therefore, in this work, we propose CodeSAM, a novel scalable framework to infuse multiple code-views into transformer-based models by creating self-attention masks. We use CodeSAM to fine-tune a small language model (SLM) like CodeBERT on the downstream SE tasks of semantic code search, code clone detection, and program classification. Experimental results show that by using this technique, we improve downstream performance when compared to SLMs like GraphCodeBERT and CodeBERT on all three tasks by utilizing individual code-views or a combination of code-views during fine-tuning. We believe that these results are indicative that techniques like CodeSAM can help create compact yet performant code SLMs that fit in resource constrained settings.
Uncertainty-Aware Deep Neural Representations for Visual Analysis of Vector Field Data
Jul 23, 2024



The widespread use of Deep Neural Networks (DNNs) has recently resulted in their application to challenging scientific visualization tasks. While advanced DNNs demonstrate impressive generalization abilities, understanding factors like prediction quality, confidence, robustness, and uncertainty is crucial. These insights aid application scientists in making informed decisions. However, DNNs lack inherent mechanisms to measure prediction uncertainty, prompting the creation of distinct frameworks for constructing robust uncertainty-aware models tailored to various visualization tasks. In this work, we develop uncertainty-aware implicit neural representations to model steady-state vector fields effectively. We comprehensively evaluate the efficacy of two principled deep uncertainty estimation techniques: (1) Deep Ensemble and (2) Monte Carlo Dropout, aimed at enabling uncertainty-informed visual analysis of features within steady vector field data. Our detailed exploration using several vector data sets indicate that uncertainty-aware models generate informative visualization results of vector field features. Furthermore, incorporating prediction uncertainty improves the resilience and interpretability of our DNN model, rendering it applicable for the analysis of non-trivial vector field data sets.
Advantages of quantum support vector machine in cross-domain classification of quantum states
Jun 30, 2024In this study, we use cross-domain classification using quantum machine learning for quantum advantages to address the entanglement versus separability paradigm. We further demonstrate the efficient classification of Bell diagonal states into zero and non-zero discord classes. The inherited structure of quantum states and its relation with a particular class of quantum states are exploited to intuitively approach the classification of different domain testing states, referred here as crossdomain classification. In addition, we extend our analysis to evaluate the robustness of our model for the analyzed problem using random unitary transformations. Using numerical analysis, our results clearly demonstrate the potential of QSVM for classifying quantum states across the multidimensional Hilbert space.
On the Achievable Rate of MIMO Narrowband PLC with Spatio-Temporal Correlated Noise
Aug 28, 2023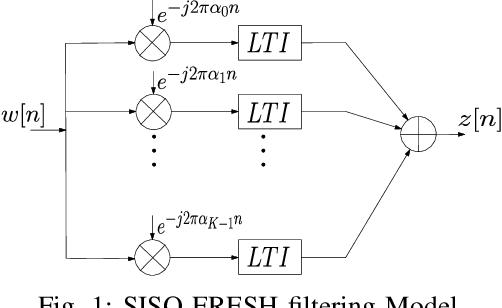
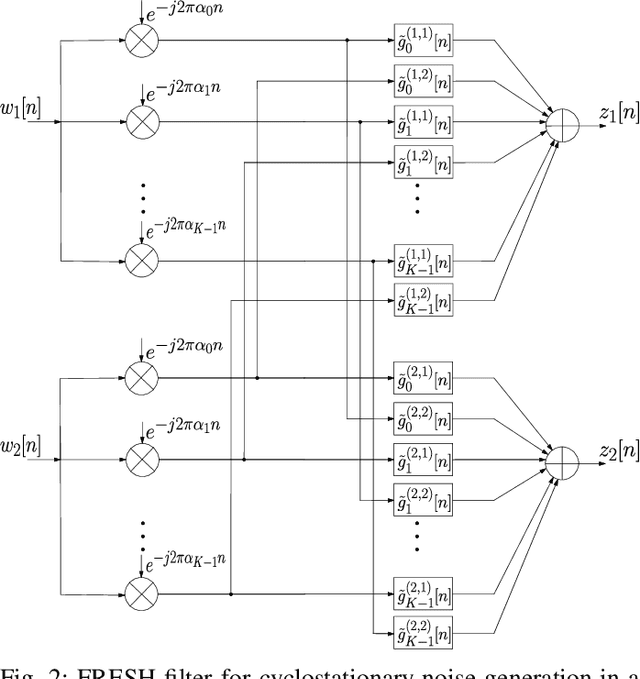
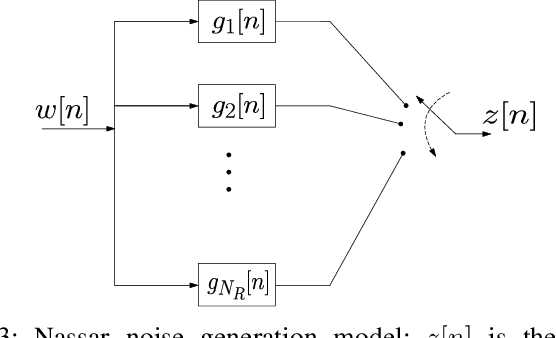

Narrowband power line communication (NB-PLC) systems are an attractive solution for supporting current and future smart grids. A technology proposed to enhance data rate in NB-PLC is multiple-input multiple-output (MIMO) transmission over multiple power line phases. To achieve reliable communication over MIMO NB-PLC, a key challenge is to take into account and mitigate the effects of temporally and spatially correlated cyclostationary noise. Noise samples in a cycle can be divided into three classes with different distributions, i.e. Gaussian, moderate impulsive, and strong impulsive. However, in this paper we first show that the impulsive classes in their turn can be divided into sub-classes with normal distributions and, after deriving the theoretical capacity, two noise sample sets with such characteristics are used to evaluate achievable information rates: one sample set is the measured noise in laboratory and the other is produced through MIMO frequency-shift (FRESH) filtering. The achievable information rates are attained by means of a spatio-temporal whitening of the portions of the cyclostationary correlated noise samples that belong to the Gaussian sub-classes. The proposed approach can be useful to design the optimal receiver in terms of bit allocation using waterfilling algorithm and to adapt modulation order.
COMEX: A Tool for Generating Customized Source Code Representations
Jul 10, 2023

Learning effective representations of source code is critical for any Machine Learning for Software Engineering (ML4SE) system. Inspired by natural language processing, large language models (LLMs) like Codex and CodeGen treat code as generic sequences of text and are trained on huge corpora of code data, achieving state of the art performance on several software engineering (SE) tasks. However, valid source code, unlike natural language, follows a strict structure and pattern governed by the underlying grammar of the programming language. Current LLMs do not exploit this property of the source code as they treat code like a sequence of tokens and overlook key structural and semantic properties of code that can be extracted from code-views like the Control Flow Graph (CFG), Data Flow Graph (DFG), Abstract Syntax Tree (AST), etc. Unfortunately, the process of generating and integrating code-views for every programming language is cumbersome and time consuming. To overcome this barrier, we propose our tool COMEX - a framework that allows researchers and developers to create and combine multiple code-views which can be used by machine learning (ML) models for various SE tasks. Some salient features of our tool are: (i) it works directly on source code (which need not be compilable), (ii) it currently supports Java and C#, (iii) it can analyze both method-level snippets and program-level snippets by using both intra-procedural and inter-procedural analysis, and (iv) it is easily extendable to other languages as it is built on tree-sitter - a widely used incremental parser that supports over 40 languages. We believe this easy-to-use code-view generation and customization tool will give impetus to research in source code representation learning methods and ML4SE. Tool: https://pypi.org/project/comex - GitHub: https://github.com/IBM/tree-sitter-codeviews - Demo: https://youtu.be/GER6U87FVbU