 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Analysis of Legacy Applications Using Knowledge Graphs for Application Modernization
May 11, 2025



Industries such as banking, telecom, and airlines - o6en have large so6ware systems that are several decades old. Many of these systems are written in old programming languages such as COBOL, PL/1, Assembler, etc. In many cases, the documentation is not updated, and those who developed/designed these systems are no longer around. Understanding these systems for either modernization or even regular maintenance has been a challenge. An extensive application may have natural boundaries based on its code dependencies and architecture. There are also other logical boundaries in an enterprise setting driven by business functions, data domains, etc. Due to these complications, the system architects generally plan their modernization across these logical boundaries in parts, thereby adopting an incremental approach for the modernization journey of the entire system. In this work, we present a so6ware system analysis tool that allows a subject ma=er expert (SME) or system architect to analyze a large so6ware system incrementally. We analyze the source code and other artifacts (such as data schema) to create a knowledge graph using a customizable ontology/schema. Entities and relations in our ontology can be defined for any combination of programming languages and platforms. Using this knowledge graph, the analyst can then define logical boundaries around dependent Entities (e.g. Programs, Transactions, Database Tables etc.). Our tool then presents different views showcasing the dependencies from the newly defined boundary to/from the other logical groups of the system. This exercise is repeated interactively to 1) Identify the Entities and groupings of interest for a modernization task and 2) Understand how a change in one part of the system may affect the other parts. To validate the efficacy of our tool, we provide an initial study of our system on two client applications.
CrashFixer: A crash resolution agent for the Linux kernel
Apr 29, 2025

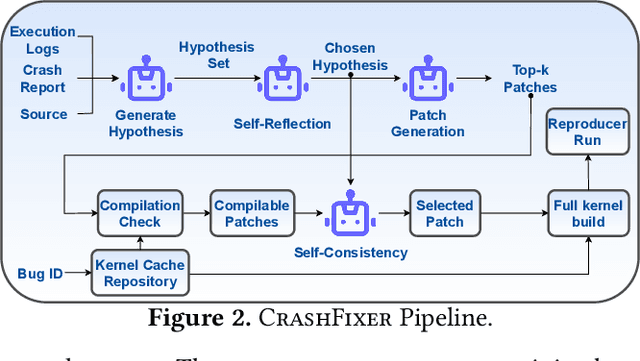
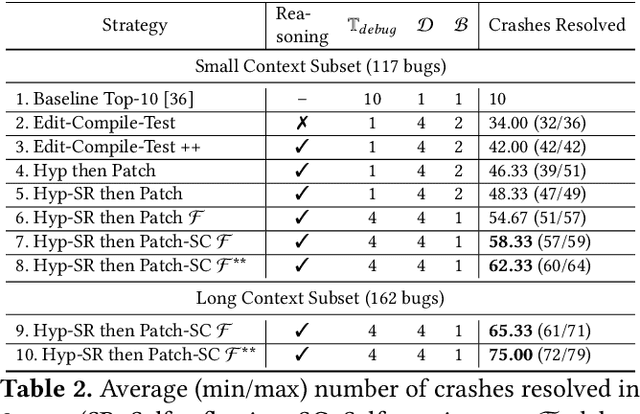
Code large language models (LLMs) have shown impressive capabilities on a multitude of software engineering tasks. In particular, they have demonstrated remarkable utility in the task of code repair. However, common benchmarks used to evaluate the performance of code LLMs are often limited to small-scale settings. In this work, we build upon kGym, which shares a benchmark for system-level Linux kernel bugs and a platform to run experiments on the Linux kernel. This paper introduces CrashFixer, the first LLM-based software repair agent that is applicable to Linux kernel bugs. Inspired by the typical workflow of a kernel developer, we identify the key capabilities an expert developer leverages to resolve a kernel crash. Using this as our guide, we revisit the kGym platform and identify key system improvements needed to practically run LLM-based agents at the scale of the Linux kernel (50K files and 20M lines of code). We implement these changes by extending kGym to create an improved platform - called kGymSuite, which will be open-sourced. Finally, the paper presents an evaluation of various repair strategies for such complex kernel bugs and showcases the value of explicitly generating a hypothesis before attempting to fix bugs in complex systems such as the Linux kernel. We also evaluated CrashFixer's capabilities on still open bugs, and found at least two patch suggestions considered plausible to resolve the reported bug.
CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs
Nov 21, 2024



Machine Learning (ML) for software engineering (SE) has gained prominence due to its ability to significantly enhance the performance of various SE applications. This progress is largely attributed to the development of generalizable source code representations that effectively capture the syntactic and semantic characteristics of code. In recent years, pre-trained transformer-based models, inspired by natural language processing (NLP), have shown remarkable success in SE tasks. However, source code contains structural and semantic properties embedded within its grammar, which can be extracted from structured code-views like the Abstract Syntax Tree (AST), Data-Flow Graph (DFG), and Control-Flow Graph (CFG). These code-views can complement NLP techniques, further improving SE tasks. Unfortunately, there are no flexible frameworks to infuse arbitrary code-views into existing transformer-based models effectively. Therefore, in this work, we propose CodeSAM, a novel scalable framework to infuse multiple code-views into transformer-based models by creating self-attention masks. We use CodeSAM to fine-tune a small language model (SLM) like CodeBERT on the downstream SE tasks of semantic code search, code clone detection, and program classification. Experimental results show that by using this technique, we improve downstream performance when compared to SLMs like GraphCodeBERT and CodeBERT on all three tasks by utilizing individual code-views or a combination of code-views during fine-tuning. We believe that these results are indicative that techniques like CodeSAM can help create compact yet performant code SLMs that fit in resource constrained settings.
COMEX: A Tool for Generating Customized Source Code Representations
Jul 10, 2023

Learning effective representations of source code is critical for any Machine Learning for Software Engineering (ML4SE) system. Inspired by natural language processing, large language models (LLMs) like Codex and CodeGen treat code as generic sequences of text and are trained on huge corpora of code data, achieving state of the art performance on several software engineering (SE) tasks. However, valid source code, unlike natural language, follows a strict structure and pattern governed by the underlying grammar of the programming language. Current LLMs do not exploit this property of the source code as they treat code like a sequence of tokens and overlook key structural and semantic properties of code that can be extracted from code-views like the Control Flow Graph (CFG), Data Flow Graph (DFG), Abstract Syntax Tree (AST), etc. Unfortunately, the process of generating and integrating code-views for every programming language is cumbersome and time consuming. To overcome this barrier, we propose our tool COMEX - a framework that allows researchers and developers to create and combine multiple code-views which can be used by machine learning (ML) models for various SE tasks. Some salient features of our tool are: (i) it works directly on source code (which need not be compilable), (ii) it currently supports Java and C#, (iii) it can analyze both method-level snippets and program-level snippets by using both intra-procedural and inter-procedural analysis, and (iv) it is easily extendable to other languages as it is built on tree-sitter - a widely used incremental parser that supports over 40 languages. We believe this easy-to-use code-view generation and customization tool will give impetus to research in source code representation learning methods and ML4SE. Tool: https://pypi.org/project/comex - GitHub: https://github.com/IBM/tree-sitter-codeviews - Demo: https://youtu.be/GER6U87FVbU
Monolith to Microservices: Representing Application Software through Heterogeneous GNN
Dec 17, 2021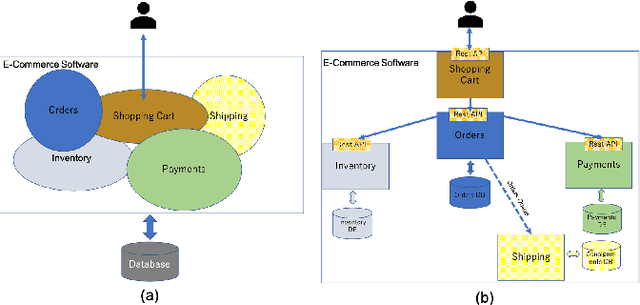


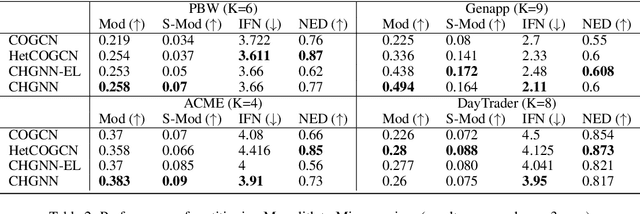
Monolith software applications encapsulate all functional capabilities into a single deployable unit. While there is an intention to maintain clean separation of functionalities even within the monolith, they tend to get compromised with the growing demand for new functionalities, changing team members, tough timelines, non-availability of skill sets, etc. As such applications age, they become hard to understand and maintain. Therefore, microservice architectures are increasingly used as they advocate building an application through multiple smaller sized, loosely coupled functional services, wherein each service owns a single functional responsibility. This approach has made microservices architecture as the natural choice for cloud based applications. But the challenges in the automated separation of functional modules for the already written monolith code slows down their migration task. Graphs are a natural choice to represent software applications. Various software artifacts like programs, tables and files become nodes in the graph and the different relationships they share, such as function calls, inheritance, resource(tables, files) access types (Create, Read, Update, Delete) can be represented as links in the graph. We therefore deduce this traditional application decomposition problem to a heterogeneous graph based clustering task. Our solution is the first of its kind to leverage heterogeneous graph neural network to learn representations of such diverse software entities and their relationships for the clustering task. We study the effectiveness by comparing with works from both software engineering and existing graph representation based techniques. We experiment with applications written in an object oriented language like Java and a procedural language like COBOL and show that our work is applicable across different programming paradigms.
Modeling Live Video Streaming: Real-Time Classification, QoE Inference, and Field Evaluation
Dec 05, 2021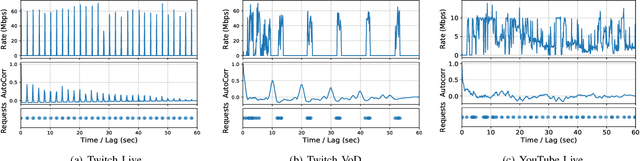

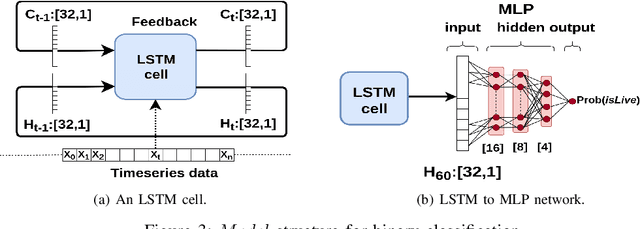
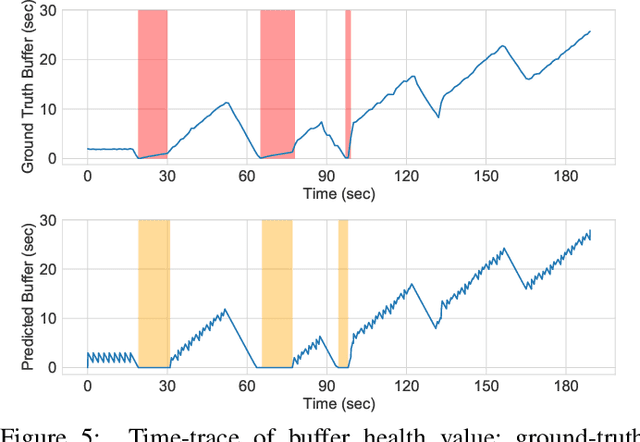
Social media, professional sports, and video games are driving rapid growth in live video streaming, on platforms such as Twitch and YouTube Live. Live streaming experience is very susceptible to short-time-scale network congestion since client playback buffers are often no more than a few seconds. Unfortunately, identifying such streams and measuring their QoE for network management is challenging, since content providers largely use the same delivery infrastructure for live and video-on-demand (VoD) streaming, and packet inspection techniques (including SNI/DNS query monitoring) cannot always distinguish between the two. In this paper, we design, build, and deploy ReCLive: a machine learning method for live video detection and QoE measurement based on network-level behavioral characteristics. Our contributions are four-fold: (1) We analyze about 23,000 video streams from Twitch and YouTube, and identify key features in their traffic profile that differentiate live and on-demand streaming. We release our traffic traces as open data to the public; (2) We develop an LSTM-based binary classifier model that distinguishes live from on-demand streams in real-time with over 95% accuracy across providers; (3) We develop a method that estimates QoE metrics of live streaming flows in terms of resolution and buffer stall events with overall accuracies of 93% and 90%, respectively; and (4) Finally, we prototype our solution, train it in the lab, and deploy it in a live ISP network serving more than 7,000 subscribers. Our method provides ISPs with fine-grained visibility into live video streams, enabling them to measure and improve user experience.
Adversarial Black-Box Attacks On Text Classifiers Using Multi-Objective Genetic Optimization Guided By Deep Networks
Nov 10, 2020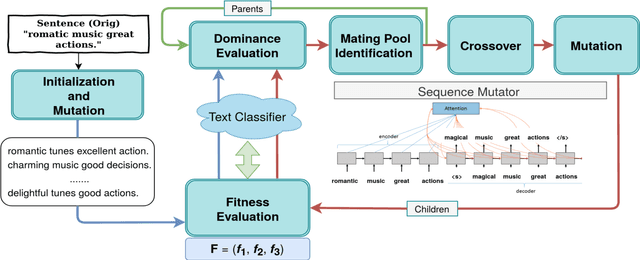


We propose a novel genetic-algorithm technique that generates black-box adversarial examples which successfully fool neural network based text classifiers. We perform a genetic search with multi-objective optimization guided by deep learning based inferences and Seq2Seq mutation to generate semantically similar but imperceptible adversaries. We compare our approach with DeepWordBug (DWB) on SST and IMDB sentiment datasets by attacking three trained models viz. char-LSTM, word-LSTM and elmo-LSTM. On an average, we achieve an attack success rate of 65.67% for SST and 36.45% for IMDB across the three models showing an improvement of 49.48% and 101% respectively. Furthermore, our qualitative study indicates that 94% of the time, the users were not able to distinguish between an original and adversarial sample.