 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Consistent Ski Rental with Distributional Advice
Mar 31, 2026The ski rental problem is a canonical model for online decision-making under uncertainty, capturing the fundamental trade-off between repeated rental costs and a one-time purchase. While classical algorithms focus on worst-case competitive ratios and recent "learning-augmented" methods leverage point-estimate predictions, neither approach fully exploits the richness of full distributional predictions while maintaining rigorous robustness guarantees. We address this gap by establishing a systematic framework that integrates distributional advice of unknown quality into both deterministic and randomized algorithms. For the deterministic setting, we formalize the problem under perfect distributional prediction and derive an efficient algorithm to compute the optimal threshold-buy day. We provide a rigorous performance analysis, identifying sufficient conditions on the predicted distribution under which the expected competitive ratio (ECR) matches the classic optimal randomized bound. To handle imperfect predictions, we propose the Clamp Policy, which restricts the buying threshold to a safe range controlled by a tunable parameter. We show that this policy is both robust, maintaining good performance even with large prediction errors, and consistent, approaching the optimal performance as predictions become accurate. For the randomized setting, we characterize the stopping distribution via a Water-Filling Algorithm, which optimizes expected cost while strictly satisfying robustness constraints. Experimental results across diverse distributions (Gaussian, geometric, and bi-modal) demonstrate that our framework improves consistency significantly over existing point-prediction baselines while maintaining comparable robustness.
SNAP: Speaker Nulling for Artifact Projection in Speech Deepfake Detection
Mar 21, 2026Recent advancements in text-to-speech technologies enable generating high-fidelity synthetic speech nearly indistinguishable from real human voices. While recent studies show the efficacy of self-supervised learning-based speech encoders for deepfake detection, these models struggle to generalize across unseen speakers. Our quantitative analysis suggests these encoder representations are substantially influenced by speaker information, causing detectors to exploit speaker-specific correlations rather than artifact-related cues. We call this phenomenon speaker entanglement. To mitigate this reliance, we introduce SNAP, a speaker-nulling framework. We estimate a speaker subspace and apply orthogonal projection to suppress speaker-dependent components, isolating synthesis artifacts within the residual features. By reducing speaker entanglement, SNAP encourages detectors to focus on artifact-related patterns, leading to state-of-the-art performance.
LiveWeb-IE: A Benchmark For Online Web Information Extraction
Mar 14, 2026Web information extraction (WIE) is the task of automatically extracting data from web pages, offering high utility for various applications. The evaluation of WIE systems has traditionally relied on benchmarks built from HTML snapshots captured at a single point in time. However, this offline evaluation paradigm fails to account for the temporally evolving nature of the web; consequently, performance on these static benchmarks often fails to generalize to dynamic real-world scenarios. To bridge this gap, we introduce \dataset, a new benchmark designed for evaluating WIE systems directly against live websites. Based on trusted and permission-granted websites, we curate natural language queries that require information extraction of various data categories, such as text, images, and hyperlinks. We further design these queries to represent four levels of complexity, based on the number and cardinality of attributes to be extracted, enabling a granular assessment of WIE systems. In addition, we propose Visual Grounding Scraper (VGS), a novel multi-stage agentic framework that mimics human cognitive processes by visually narrowing down web page content to extract desired information. Extensive experiments across diverse backbone models demonstrate the effectiveness and robustness of VGS. We believe that this study lays the foundation for developing practical and robust WIE systems.
Scaling Laws of SignSGD in Linear Regression: When Does It Outperform SGD?
Mar 02, 2026We study scaling laws of signSGD under a power-law random features (PLRF) model that accounts for both feature and target decay. We analyze the population risk of a linear model trained with one-pass signSGD on Gaussian-sketched features. We express the risk as a function of model size, training steps, learning rate, and the feature and target decay parameters. Comparing against the SGD risk analyzed by Paquette et al. (2024), we identify a drift-normalization effect and a noise-reshaping effect unique to signSGD. We then obtain compute-optimal scaling laws under the optimal choice of learning rate. Our analysis shows that the noise-reshaping effect can make the compute-optimal slope of signSGD steeper than that of SGD in regimes where noise is dominant. Finally, we observe that the widely used warmup-stable-decay (WSD) schedule further reduces the noise term and sharpens the compute-optimal slope, when feature decay is fast but target decay is slow.
Expanding Foundational Language Capabilities in Open-Source LLMs through a Korean Case Study
Sep 04, 2025We introduce Llama-3-Motif, a language model consisting of 102 billion parameters, specifically designed to enhance Korean capabilities while retaining strong performance in English. Developed on the Llama 3 architecture, Llama-3-Motif employs advanced training techniques, including LlamaPro and Masked Structure Growth, to effectively scale the model without altering its core Transformer architecture. Using the MoAI platform for efficient training across hyperscale GPU clusters, we optimized Llama-3-Motif using a carefully curated dataset that maintains a balanced ratio of Korean and English data. Llama-3-Motif shows decent performance on Korean-specific benchmarks, outperforming existing models and achieving results comparable to GPT-4.
Generating Animated Layouts as Structured Text Representations
May 02, 2025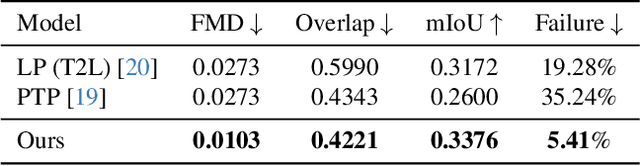
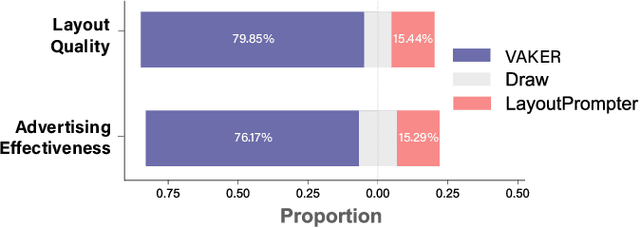
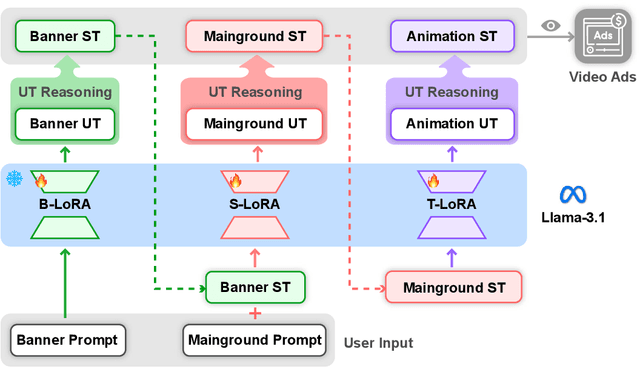
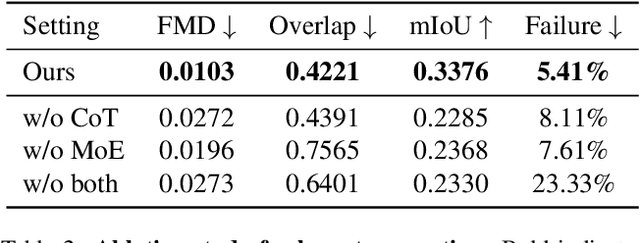
Despite the remarkable progress in text-to-video models, achieving precise control over text elements and animated graphics remains a significant challenge, especially in applications such as video advertisements. To address this limitation, we introduce Animated Layout Generation, a novel approach to extend static graphic layouts with temporal dynamics. We propose a Structured Text Representation for fine-grained video control through hierarchical visual elements. To demonstrate the effectiveness of our approach, we present VAKER (Video Ad maKER), a text-to-video advertisement generation pipeline that combines a three-stage generation process with Unstructured Text Reasoning for seamless integration with LLMs. VAKER fully automates video advertisement generation by incorporating dynamic layout trajectories for objects and graphics across specific video frames. Through extensive evaluations, we demonstrate that VAKER significantly outperforms existing methods in generating video advertisements. Project Page: https://yeonsangshin.github.io/projects/Vaker
CrashFixer: A crash resolution agent for the Linux kernel
Apr 29, 2025

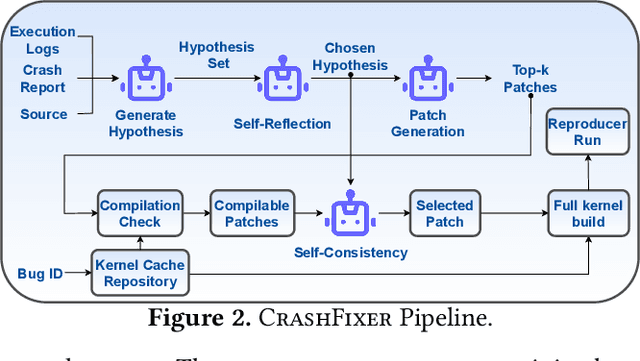
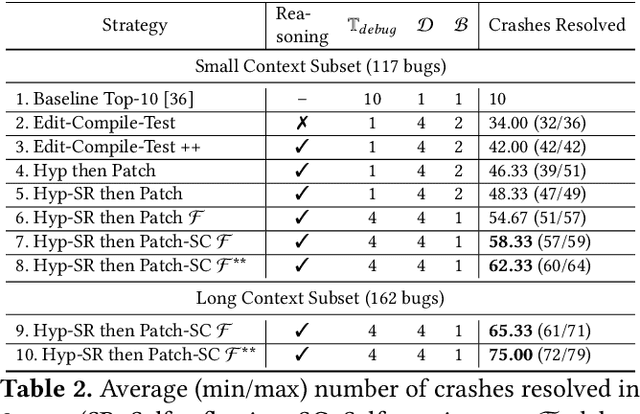
Code large language models (LLMs) have shown impressive capabilities on a multitude of software engineering tasks. In particular, they have demonstrated remarkable utility in the task of code repair. However, common benchmarks used to evaluate the performance of code LLMs are often limited to small-scale settings. In this work, we build upon kGym, which shares a benchmark for system-level Linux kernel bugs and a platform to run experiments on the Linux kernel. This paper introduces CrashFixer, the first LLM-based software repair agent that is applicable to Linux kernel bugs. Inspired by the typical workflow of a kernel developer, we identify the key capabilities an expert developer leverages to resolve a kernel crash. Using this as our guide, we revisit the kGym platform and identify key system improvements needed to practically run LLM-based agents at the scale of the Linux kernel (50K files and 20M lines of code). We implement these changes by extending kGym to create an improved platform - called kGymSuite, which will be open-sourced. Finally, the paper presents an evaluation of various repair strategies for such complex kernel bugs and showcases the value of explicitly generating a hypothesis before attempting to fix bugs in complex systems such as the Linux kernel. We also evaluated CrashFixer's capabilities on still open bugs, and found at least two patch suggestions considered plausible to resolve the reported bug.
Activating Self-Attention for Multi-Scene Absolute Pose Regression
Nov 03, 2024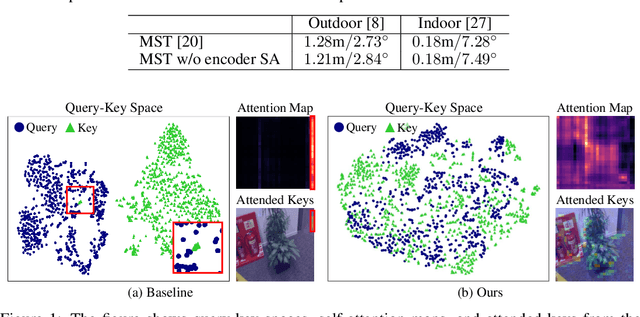
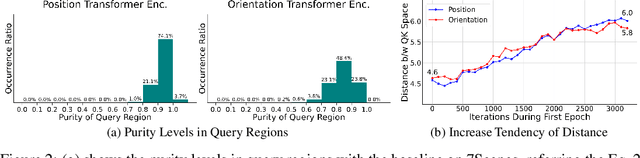

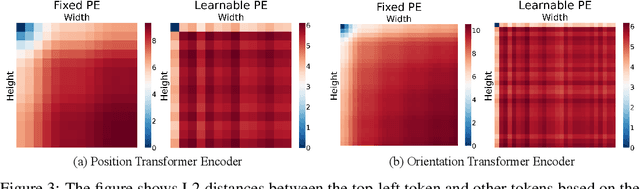
Multi-scene absolute pose regression addresses the demand for fast and memory-efficient camera pose estimation across various real-world environments. Nowadays, transformer-based model has been devised to regress the camera pose directly in multi-scenes. Despite its potential, transformer encoders are underutilized due to the collapsed self-attention map, having low representation capacity. This work highlights the problem and investigates it from a new perspective: distortion of query-key embedding space. Based on the statistical analysis, we reveal that queries and keys are mapped in completely different spaces while only a few keys are blended into the query region. This leads to the collapse of the self-attention map as all queries are considered similar to those few keys. Therefore, we propose simple but effective solutions to activate self-attention. Concretely, we present an auxiliary loss that aligns queries and keys, preventing the distortion of query-key space and encouraging the model to find global relations by self-attention. In addition, the fixed sinusoidal positional encoding is adopted instead of undertrained learnable one to reflect appropriate positional clues into the inputs of self-attention. As a result, our approach resolves the aforementioned problem effectively, thus outperforming existing methods in both outdoor and indoor scenes.
Single-shot reconstruction of three-dimensional morphology of biological cells in digital holographic microscopy using a physics-driven neural network
Sep 30, 2024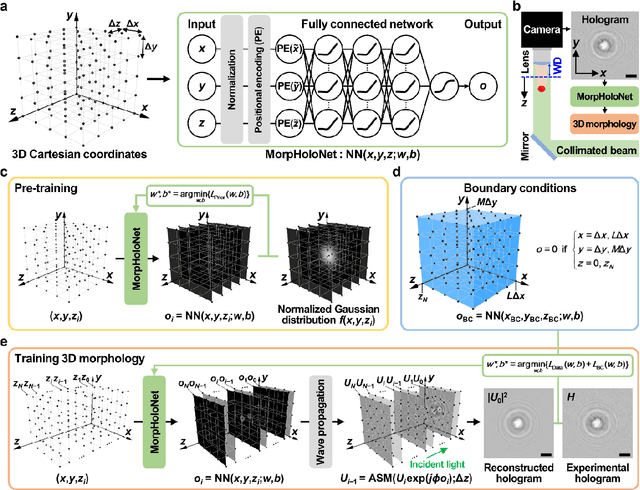

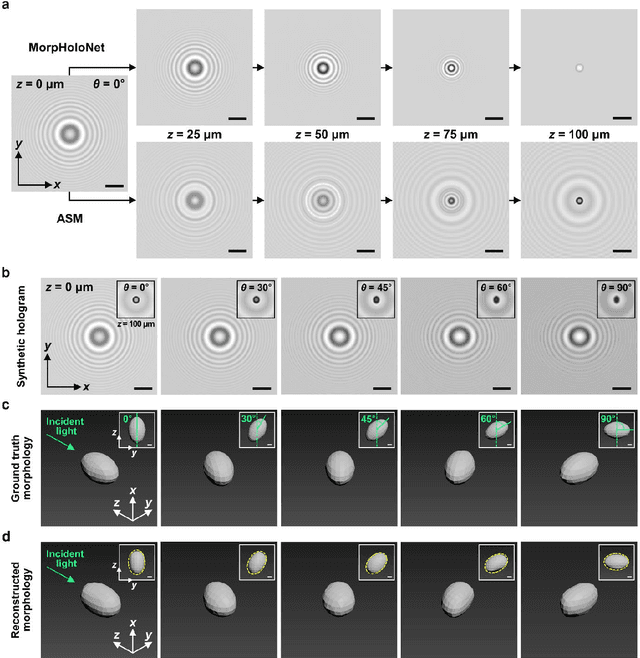
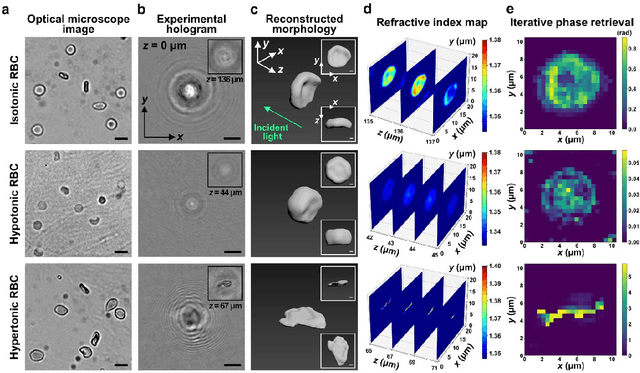
Recent advances in deep learning-based image reconstruction techniques have led to significant progress in phase retrieval using digital in-line holographic microscopy (DIHM). However, existing deep learning-based phase retrieval methods have technical limitations in generalization performance and three-dimensional (3D) morphology reconstruction from a single-shot hologram of biological cells. In this study, we propose a novel deep learning model, named MorpHoloNet, for single-shot reconstruction of 3D morphology by integrating physics-driven and coordinate-based neural networks. By simulating the optical diffraction of coherent light through a 3D phase shift distribution, the proposed MorpHoloNet is optimized by minimizing the loss between the simulated and input holograms on the sensor plane. Compared to existing DIHM methods that face challenges with twin image and phase retrieval problems, MorpHoloNet enables direct reconstruction of 3D complex light field and 3D morphology of a test sample from its single-shot hologram without requiring multiple phase-shifted holograms or angle scanning. The performance of the proposed MorpHoloNet is validated by reconstructing 3D morphologies and refractive index distributions from synthetic holograms of ellipsoids and experimental holograms of biological cells. The proposed deep learning model is utilized to reconstruct spatiotemporal variations in 3D translational and rotational behaviors and morphological deformations of biological cells from consecutive single-shot holograms captured using DIHM. MorpHoloNet would pave the way for advancing label-free, real-time 3D imaging and dynamic analysis of biological cells under various cellular microenvironments in biomedical and engineering fields.
Prediction-Feedback DETR for Temporal Action Detection
Aug 29, 2024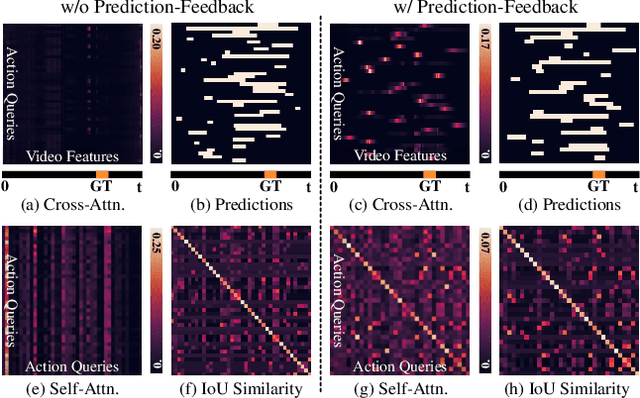
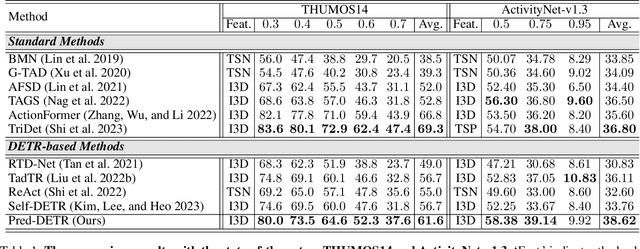
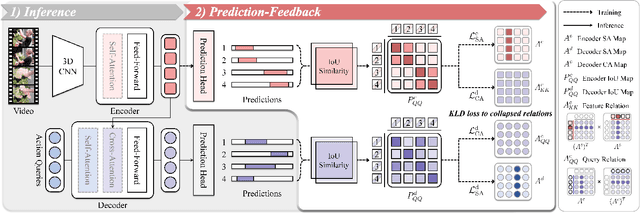
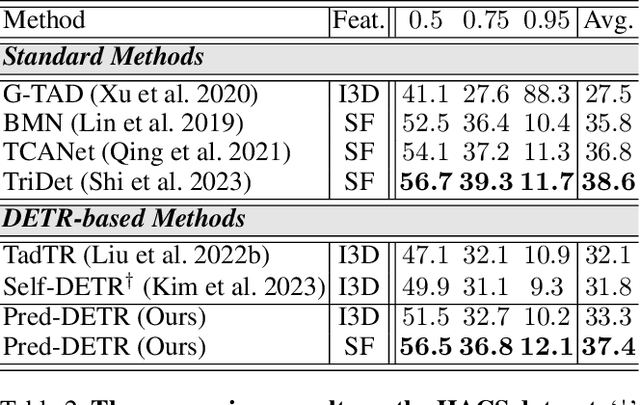
Temporal Action Detection (TAD) is fundamental yet challenging for real-world video applications. Leveraging the unique benefits of transformers, various DETR-based approaches have been adopted in TAD. However, it has recently been identified that the attention collapse in self-attention causes the performance degradation of DETR for TAD. Building upon previous research, this paper newly addresses the attention collapse problem in cross-attention within DETR-based TAD methods. Moreover, our findings reveal that cross-attention exhibits patterns distinct from predictions, indicating a short-cut phenomenon. To resolve this, we propose a new framework, Prediction-Feedback DETR (Pred-DETR), which utilizes predictions to restore the collapse and align the cross- and self-attention with predictions. Specifically, we devise novel prediction-feedback objectives using guidance from the relations of the predictions. As a result, Pred-DETR significantly alleviates the collapse and achieves state-of-the-art performance among DETR-based methods on various challenging benchmarks including THUMOS14, ActivityNet-v1.3, HACS, and FineAction.