 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffolio: A Diffusion Model for Multivariate Probabilistic Financial Time-Series Forecasting and Portfolio Construction
Nov 10, 2025Probabilistic forecasting is crucial in multivariate financial time-series for constructing efficient portfolios that account for complex cross-sectional dependencies. In this paper, we propose Diffolio, a diffusion model designed for multivariate financial time-series forecasting and portfolio construction. Diffolio employs a denoising network with a hierarchical attention architecture, comprising both asset-level and market-level layers. Furthermore, to better reflect cross-sectional correlations, we introduce a correlation-guided regularizer informed by a stable estimate of the target correlation matrix. This structure effectively extracts salient features not only from historical returns but also from asset-specific and systematic covariates, significantly enhancing the performance of forecasts and portfolios. Experimental results on the daily excess returns of 12 industry portfolios show that Diffolio outperforms various probabilistic forecasting baselines in multivariate forecasting accuracy and portfolio performance. Moreover, in portfolio experiments, portfolios constructed from Diffolio's forecasts show consistently robust performance, thereby outperforming those from benchmarks by achieving higher Sharpe ratios for the mean-variance tangency portfolio and higher certainty equivalents for the growth-optimal portfolio. These results demonstrate the superiority of our proposed Diffolio in terms of not only statistical accuracy but also economic significance.
HU-based Foreground Masking for 3D Medical Masked Image Modeling
Sep 09, 2025While Masked Image Modeling (MIM) has revolutionized fields of computer vision, its adoption in 3D medical image computing has been limited by the use of random masking, which overlooks the density of anatomical objects. To address this limitation, we enhance the pretext task with a simple yet effective masking strategy. Leveraging Hounsfield Unit (HU) measurements, we implement an HU-based Foreground Masking, which focuses on the intensity distribution of visceral organs and excludes non-tissue regions, such as air and fluid, that lack diagnostically meaningful features. Extensive experiments on five public 3D medical imaging datasets demonstrate that our masking consistently improves performance, both in quality of segmentation and Dice score (BTCV:~84.64\%, Flare22:~92.43\%, MM-WHS:~90.67\%, Amos22:~88.64\%, BraTS:~78.55\%). These results underscore the importance of domain-centric MIM and suggest a promising direction for representation learning in medical image segmentation. Implementation is available at github.com/AISeedHub/SubFore/.
Toward Stable World Models: Measuring and Addressing World Instability in Generative Environments
Mar 11, 2025We present a novel study on enhancing the capability of preserving the content in world models, focusing on a property we term World Stability. Recent diffusion-based generative models have advanced the synthesis of immersive and realistic environments that are pivotal for applications such as reinforcement learning and interactive game engines. However, while these models excel in quality and diversity, they often neglect the preservation of previously generated scenes over time--a shortfall that can introduce noise into agent learning and compromise performance in safety-critical settings. In this work, we introduce an evaluation framework that measures world stability by having world models perform a sequence of actions followed by their inverses to return to their initial viewpoint, thereby quantifying the consistency between the starting and ending observations. Our comprehensive assessment of state-of-the-art diffusion-based world models reveals significant challenges in achieving high world stability. Moreover, we investigate several improvement strategies to enhance world stability. Our results underscore the importance of world stability in world modeling and provide actionable insights for future research in this domain.
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Nov 25, 2024Text-based generation and editing of 3D scenes hold significant potential for streamlining content creation through intuitive user interactions. While recent advances leverage 3D Gaussian Splatting (3DGS) for high-fidelity and real-time rendering, existing methods are often specialized and task-focused, lacking a unified framework for both generation and editing. In this paper, we introduce SplatFlow, a comprehensive framework that addresses this gap by enabling direct 3DGS generation and editing. SplatFlow comprises two main components: a multi-view rectified flow (RF) model and a Gaussian Splatting Decoder (GSDecoder). The multi-view RF model operates in latent space, generating multi-view images, depths, and camera poses simultaneously, conditioned on text prompts, thus addressing challenges like diverse scene scales and complex camera trajectories in real-world settings. Then, the GSDecoder efficiently translates these latent outputs into 3DGS representations through a feed-forward 3DGS method. Leveraging training-free inversion and inpainting techniques, SplatFlow enables seamless 3DGS editing and supports a broad range of 3D tasks-including object editing, novel view synthesis, and camera pose estimation-within a unified framework without requiring additional complex pipelines. We validate SplatFlow's capabilities on the MVImgNet and DL3DV-7K datasets, demonstrating its versatility and effectiveness in various 3D generation, editing, and inpainting-based tasks.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Diffusion Model Patching via Mixture-of-Prompts
May 30, 2024



We present Diffusion Model Patching (DMP), a simple method to boost the performance of pre-trained diffusion models that have already reached convergence, with a negligible increase in parameters. DMP inserts a small, learnable set of prompts into the model's input space while keeping the original model frozen. The effectiveness of DMP is not merely due to the addition of parameters but stems from its dynamic gating mechanism, which selects and combines a subset of learnable prompts at every step of the generative process (e.g., reverse denoising steps). This strategy, which we term "mixture-of-prompts", enables the model to draw on the distinct expertise of each prompt, essentially "patching" the model's functionality at every step with minimal yet specialized parameters. Uniquely, DMP enhances the model by further training on the same dataset on which it was originally trained, even in a scenario where significant improvements are typically not expected due to model convergence. Experiments show that DMP significantly enhances the converged FID of DiT-L/2 on FFHQ 256x256 by 10.38%, achieved with only a 1.43% parameter increase and 50K additional training iterations.
Pegasus-v1 Technical Report
Apr 23, 2024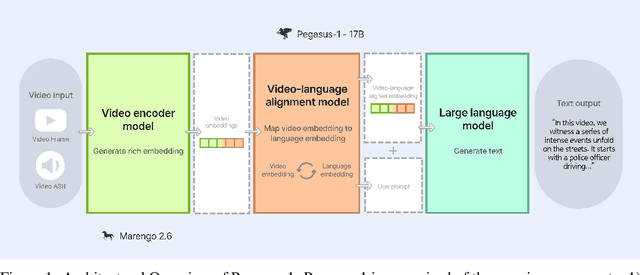
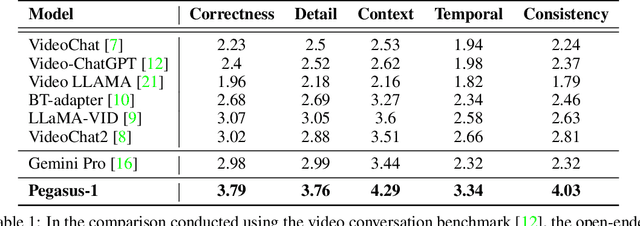


This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.
Denoising Task Difficulty-based Curriculum for Training Diffusion Models
Mar 15, 2024Diffusion-based generative models have emerged as powerful tools in the realm of generative modeling. Despite extensive research on denoising across various timesteps and noise levels, a conflict persists regarding the relative difficulties of the denoising tasks. While various studies argue that lower timesteps present more challenging tasks, others contend that higher timesteps are more difficult. To address this conflict, our study undertakes a comprehensive examination of task difficulties, focusing on convergence behavior and changes in relative entropy between consecutive probability distributions across timesteps. Our observational study reveals that denoising at earlier timesteps poses challenges characterized by slower convergence and higher relative entropy, indicating increased task difficulty at these lower timesteps. Building on these observations, we introduce an easy-to-hard learning scheme, drawing from curriculum learning, to enhance the training process of diffusion models. By organizing timesteps or noise levels into clusters and training models with descending orders of difficulty, we facilitate an order-aware training regime, progressing from easier to harder denoising tasks, thereby deviating from the conventional approach of training diffusion models simultaneously across all timesteps. Our approach leads to improved performance and faster convergence by leveraging the benefits of curriculum learning, while maintaining orthogonality with existing improvements in diffusion training techniques. We validate these advantages through comprehensive experiments in image generation tasks, including unconditional, class-conditional, and text-to-image generation.
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Mar 14, 2024



Diffusion models have achieved remarkable success across a range of generative tasks. Recent efforts to enhance diffusion model architectures have reimagined them as a form of multi-task learning, where each task corresponds to a denoising task at a specific noise level. While these efforts have focused on parameter isolation and task routing, they fall short of capturing detailed inter-task relationships and risk losing semantic information, respectively. In response, we introduce Switch Diffusion Transformer (Switch-DiT), which establishes inter-task relationships between conflicting tasks without compromising semantic information. To achieve this, we employ a sparse mixture-of-experts within each transformer block to utilize semantic information and facilitate handling conflicts in tasks through parameter isolation. Additionally, we propose a diffusion prior loss, encouraging similar tasks to share their denoising paths while isolating conflicting ones. Through these, each transformer block contains a shared expert across all tasks, where the common and task-specific denoising paths enable the diffusion model to construct its beneficial way of synergizing denoising tasks. Extensive experiments validate the effectiveness of our approach in improving both image quality and convergence rate, and further analysis demonstrates that Switch-DiT constructs tailored denoising paths across various generation scenarios.
HarmonyView: Harmonizing Consistency and Diversity in One-Image-to-3D
Dec 26, 2023Recent progress in single-image 3D generation highlights the importance of multi-view coherency, leveraging 3D priors from large-scale diffusion models pretrained on Internet-scale images. However, the aspect of novel-view diversity remains underexplored within the research landscape due to the ambiguity in converting a 2D image into 3D content, where numerous potential shapes can emerge. Here, we aim to address this research gap by simultaneously addressing both consistency and diversity. Yet, striking a balance between these two aspects poses a considerable challenge due to their inherent trade-offs. This work introduces HarmonyView, a simple yet effective diffusion sampling technique adept at decomposing two intricate aspects in single-image 3D generation: consistency and diversity. This approach paves the way for a more nuanced exploration of the two critical dimensions within the sampling process. Moreover, we propose a new evaluation metric based on CLIP image and text encoders to comprehensively assess the diversity of the generated views, which closely aligns with human evaluators' judgments. In experiments, HarmonyView achieves a harmonious balance, demonstrating a win-win scenario in both consistency and diversity.