 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
Parameter Efficient Mamba Tuning via Projector-targeted Diagonal-centric Linear Transformation
Nov 21, 2024Despite the growing interest in Mamba architecture as a potential replacement for Transformer architecture, parameter-efficient fine-tuning (PEFT) approaches for Mamba remain largely unexplored. In our study, we introduce two key insights-driven strategies for PEFT in Mamba architecture: (1) While state-space models (SSMs) have been regarded as the cornerstone of Mamba architecture, then expected to play a primary role in transfer learning, our findings reveal that Projectors -- not SSMs -- are the predominant contributors to transfer learning, and (2) Based on our observation that adapting pretrained Projectors to new tasks can be effectively approximated through a near-diagonal linear transformation, we propose a novel PEFT method specialized to Mamba architecture: Projector-targeted Diagonal-centric Linear Transformation (ProDiaL). ProDiaL focuses on optimizing only diagonal-centric linear transformation matrices, without directly fine-tuning the pretrained Projector weights. This targeted approach allows efficient task adaptation, utilizing less than 1% of the total parameters, and exhibits strong performance across both vision and language Mamba models, highlighting its versatility and effectiveness.
Diffusion Model Patching via Mixture-of-Prompts
May 30, 2024



We present Diffusion Model Patching (DMP), a simple method to boost the performance of pre-trained diffusion models that have already reached convergence, with a negligible increase in parameters. DMP inserts a small, learnable set of prompts into the model's input space while keeping the original model frozen. The effectiveness of DMP is not merely due to the addition of parameters but stems from its dynamic gating mechanism, which selects and combines a subset of learnable prompts at every step of the generative process (e.g., reverse denoising steps). This strategy, which we term "mixture-of-prompts", enables the model to draw on the distinct expertise of each prompt, essentially "patching" the model's functionality at every step with minimal yet specialized parameters. Uniquely, DMP enhances the model by further training on the same dataset on which it was originally trained, even in a scenario where significant improvements are typically not expected due to model convergence. Experiments show that DMP significantly enhances the converged FID of DiT-L/2 on FFHQ 256x256 by 10.38%, achieved with only a 1.43% parameter increase and 50K additional training iterations.
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Mar 14, 2024



Diffusion models have achieved remarkable success across a range of generative tasks. Recent efforts to enhance diffusion model architectures have reimagined them as a form of multi-task learning, where each task corresponds to a denoising task at a specific noise level. While these efforts have focused on parameter isolation and task routing, they fall short of capturing detailed inter-task relationships and risk losing semantic information, respectively. In response, we introduce Switch Diffusion Transformer (Switch-DiT), which establishes inter-task relationships between conflicting tasks without compromising semantic information. To achieve this, we employ a sparse mixture-of-experts within each transformer block to utilize semantic information and facilitate handling conflicts in tasks through parameter isolation. Additionally, we propose a diffusion prior loss, encouraging similar tasks to share their denoising paths while isolating conflicting ones. Through these, each transformer block contains a shared expert across all tasks, where the common and task-specific denoising paths enable the diffusion model to construct its beneficial way of synergizing denoising tasks. Extensive experiments validate the effectiveness of our approach in improving both image quality and convergence rate, and further analysis demonstrates that Switch-DiT constructs tailored denoising paths across various generation scenarios.
NEO-KD: Knowledge-Distillation-Based Adversarial Training for Robust Multi-Exit Neural Networks
Nov 01, 2023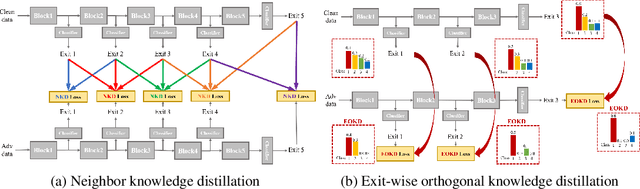
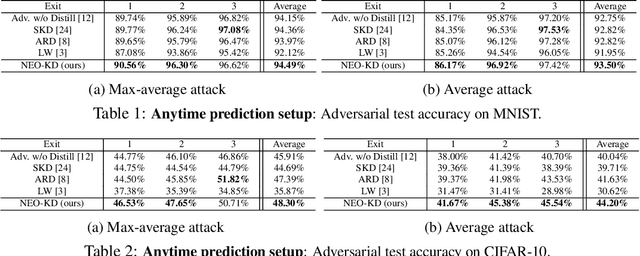
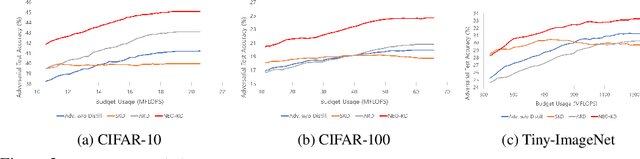
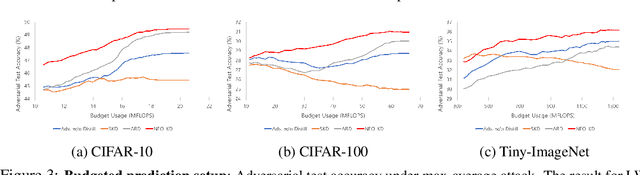
While multi-exit neural networks are regarded as a promising solution for making efficient inference via early exits, combating adversarial attacks remains a challenging problem. In multi-exit networks, due to the high dependency among different submodels, an adversarial example targeting a specific exit not only degrades the performance of the target exit but also reduces the performance of all other exits concurrently. This makes multi-exit networks highly vulnerable to simple adversarial attacks. In this paper, we propose NEO-KD, a knowledge-distillation-based adversarial training strategy that tackles this fundamental challenge based on two key contributions. NEO-KD first resorts to neighbor knowledge distillation to guide the output of the adversarial examples to tend to the ensemble outputs of neighbor exits of clean data. NEO-KD also employs exit-wise orthogonal knowledge distillation for reducing adversarial transferability across different submodels. The result is a significantly improved robustness against adversarial attacks. Experimental results on various datasets/models show that our method achieves the best adversarial accuracy with reduced computation budgets, compared to the baselines relying on existing adversarial training or knowledge distillation techniques for multi-exit networks.