 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Mar 20, 2025We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Mar 15, 2025



Recent progress in 3D/4D scene generation emphasizes the importance of physical alignment throughout video generation and scene reconstruction. However, existing methods improve the alignment separately at each stage, making it difficult to manage subtle misalignments arising from another stage. Here, we present SteerX, a zero-shot inference-time steering method that unifies scene reconstruction into the generation process, tilting data distributions toward better geometric alignment. To this end, we introduce two geometric reward functions for 3D/4D scene generation by using pose-free feed-forward scene reconstruction models. Through extensive experiments, we demonstrate the effectiveness of SteerX in improving 3D/4D scene generation.
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Nov 25, 2024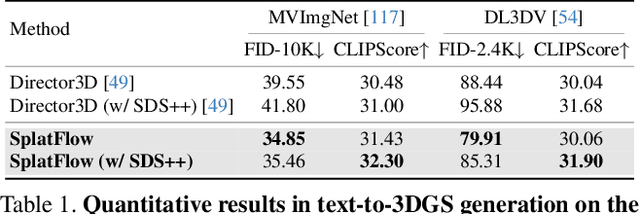


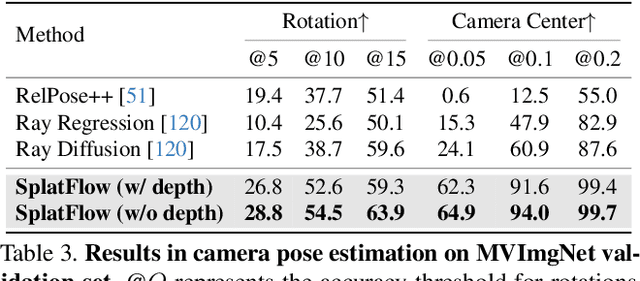
Text-based generation and editing of 3D scenes hold significant potential for streamlining content creation through intuitive user interactions. While recent advances leverage 3D Gaussian Splatting (3DGS) for high-fidelity and real-time rendering, existing methods are often specialized and task-focused, lacking a unified framework for both generation and editing. In this paper, we introduce SplatFlow, a comprehensive framework that addresses this gap by enabling direct 3DGS generation and editing. SplatFlow comprises two main components: a multi-view rectified flow (RF) model and a Gaussian Splatting Decoder (GSDecoder). The multi-view RF model operates in latent space, generating multi-view images, depths, and camera poses simultaneously, conditioned on text prompts, thus addressing challenges like diverse scene scales and complex camera trajectories in real-world settings. Then, the GSDecoder efficiently translates these latent outputs into 3DGS representations through a feed-forward 3DGS method. Leveraging training-free inversion and inpainting techniques, SplatFlow enables seamless 3DGS editing and supports a broad range of 3D tasks-including object editing, novel view synthesis, and camera pose estimation-within a unified framework without requiring additional complex pipelines. We validate SplatFlow's capabilities on the MVImgNet and DL3DV-7K datasets, demonstrating its versatility and effectiveness in various 3D generation, editing, and inpainting-based tasks.
Diffusion Model Patching via Mixture-of-Prompts
May 30, 2024



We present Diffusion Model Patching (DMP), a simple method to boost the performance of pre-trained diffusion models that have already reached convergence, with a negligible increase in parameters. DMP inserts a small, learnable set of prompts into the model's input space while keeping the original model frozen. The effectiveness of DMP is not merely due to the addition of parameters but stems from its dynamic gating mechanism, which selects and combines a subset of learnable prompts at every step of the generative process (e.g., reverse denoising steps). This strategy, which we term "mixture-of-prompts", enables the model to draw on the distinct expertise of each prompt, essentially "patching" the model's functionality at every step with minimal yet specialized parameters. Uniquely, DMP enhances the model by further training on the same dataset on which it was originally trained, even in a scenario where significant improvements are typically not expected due to model convergence. Experiments show that DMP significantly enhances the converged FID of DiT-L/2 on FFHQ 256x256 by 10.38%, achieved with only a 1.43% parameter increase and 50K additional training iterations.
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Mar 14, 2024



Diffusion models have achieved remarkable success across a range of generative tasks. Recent efforts to enhance diffusion model architectures have reimagined them as a form of multi-task learning, where each task corresponds to a denoising task at a specific noise level. While these efforts have focused on parameter isolation and task routing, they fall short of capturing detailed inter-task relationships and risk losing semantic information, respectively. In response, we introduce Switch Diffusion Transformer (Switch-DiT), which establishes inter-task relationships between conflicting tasks without compromising semantic information. To achieve this, we employ a sparse mixture-of-experts within each transformer block to utilize semantic information and facilitate handling conflicts in tasks through parameter isolation. Additionally, we propose a diffusion prior loss, encouraging similar tasks to share their denoising paths while isolating conflicting ones. Through these, each transformer block contains a shared expert across all tasks, where the common and task-specific denoising paths enable the diffusion model to construct its beneficial way of synergizing denoising tasks. Extensive experiments validate the effectiveness of our approach in improving both image quality and convergence rate, and further analysis demonstrates that Switch-DiT constructs tailored denoising paths across various generation scenarios.
HarmonyView: Harmonizing Consistency and Diversity in One-Image-to-3D
Dec 26, 2023Recent progress in single-image 3D generation highlights the importance of multi-view coherency, leveraging 3D priors from large-scale diffusion models pretrained on Internet-scale images. However, the aspect of novel-view diversity remains underexplored within the research landscape due to the ambiguity in converting a 2D image into 3D content, where numerous potential shapes can emerge. Here, we aim to address this research gap by simultaneously addressing both consistency and diversity. Yet, striking a balance between these two aspects poses a considerable challenge due to their inherent trade-offs. This work introduces HarmonyView, a simple yet effective diffusion sampling technique adept at decomposing two intricate aspects in single-image 3D generation: consistency and diversity. This approach paves the way for a more nuanced exploration of the two critical dimensions within the sampling process. Moreover, we propose a new evaluation metric based on CLIP image and text encoders to comprehensively assess the diversity of the generated views, which closely aligns with human evaluators' judgments. In experiments, HarmonyView achieves a harmonious balance, demonstrating a win-win scenario in both consistency and diversity.
DiffRef3D: A Diffusion-based Proposal Refinement Framework for 3D Object Detection
Oct 25, 2023Denoising diffusion models show remarkable performances in generative tasks, and their potential applications in perception tasks are gaining interest. In this paper, we introduce a novel framework named DiffRef3D which adopts the diffusion process on 3D object detection with point clouds for the first time. Specifically, we formulate the proposal refinement stage of two-stage 3D object detectors as a conditional diffusion process. During training, DiffRef3D gradually adds noise to the residuals between proposals and target objects, then applies the noisy residuals to proposals to generate hypotheses. The refinement module utilizes these hypotheses to denoise the noisy residuals and generate accurate box predictions. In the inference phase, DiffRef3D generates initial hypotheses by sampling noise from a Gaussian distribution as residuals and refines the hypotheses through iterative steps. DiffRef3D is a versatile proposal refinement framework that consistently improves the performance of existing 3D object detection models. We demonstrate the significance of DiffRef3D through extensive experiments on the KITTI benchmark. Code will be available.
Point-DynRF: Point-based Dynamic Radiance Fields from a Monocular Video
Oct 24, 2023Dynamic radiance fields have emerged as a promising approach for generating novel views from a monocular video. However, previous methods enforce the geometric consistency to dynamic radiance fields only between adjacent input frames, making it difficult to represent the global scene geometry and degenerates at the viewpoint that is spatio-temporally distant from the input camera trajectory. To solve this problem, we introduce point-based dynamic radiance fields (\textbf{Point-DynRF}), a novel framework where the global geometric information and the volume rendering process are trained by neural point clouds and dynamic radiance fields, respectively. Specifically, we reconstruct neural point clouds directly from geometric proxies and optimize both radiance fields and the geometric proxies using our proposed losses, allowing them to complement each other. We validate the effectiveness of our method with experiments on the NVIDIA Dynamic Scenes Dataset and several causally captured monocular video clips.
Denoising Task Routing for Diffusion Models
Oct 11, 2023Diffusion models generate highly realistic images through learning a multi-step denoising process, naturally embodying the principles of multi-task learning (MTL). Despite the inherent connection between diffusion models and MTL, there remains an unexplored area in designing neural architectures that explicitly incorporate MTL into the framework of diffusion models. In this paper, we present Denoising Task Routing (DTR), a simple add-on strategy for existing diffusion model architectures to establish distinct information pathways for individual tasks within a single architecture by selectively activating subsets of channels in the model. What makes DTR particularly compelling is its seamless integration of prior knowledge of denoising tasks into the framework: (1) Task Affinity: DTR activates similar channels for tasks at adjacent timesteps and shifts activated channels as sliding windows through timesteps, capitalizing on the inherent strong affinity between tasks at adjacent timesteps. (2) Task Weights: During the early stages (higher timesteps) of the denoising process, DTR assigns a greater number of task-specific channels, leveraging the insight that diffusion models prioritize reconstructing global structure and perceptually rich contents in earlier stages, and focus on simple noise removal in later stages. Our experiments demonstrate that DTR consistently enhances the performance of diffusion models across various evaluation protocols, all without introducing additional parameters. Furthermore, DTR contributes to accelerating convergence during training. Finally, we show the complementarity between our architectural approach and existing MTL optimization techniques, providing a more complete view of MTL within the context of diffusion training.