 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnonpsy: A Graph-Based Framework for Structure-Preserving De-identification of Psychiatric Narratives
Jan 20, 2026Psychiatric narratives encode patient identity not only through explicit identifiers but also through idiosyncratic life events embedded in their clinical structure. Existing de-identification approaches, including PHI masking and LLM-based synthetic rewriting, operate at the text level and offer limited control over which semantic elements are preserved or altered. We introduce Anonpsy, a de-identification framework that reformulates the task as graph-guided semantic rewriting. Anonpsy (1) converts each narrative into a semantic graph encoding clinical entities, temporal anchors, and typed relations; (2) applies graph-constrained perturbations that modify identifying context while preserving clinically essential structure; and (3) regenerates text via graph-conditioned LLM generation. Evaluated on 90 clinician-authored psychiatric case narratives, Anonpsy preserves diagnostic fidelity while achieving consistently low re-identification risk under expert, semantic, and GPT-5-based evaluations. Compared with a strong LLM-only rewriting baseline, Anonpsy yields substantially lower semantic similarity and identifiability. These results demonstrate that explicit structural representations combined with constrained generation provide an effective approach to de-identification for psychiatric narratives.
AutoMedic: An Automated Evaluation Framework for Clinical Conversational Agents with Medical Dataset Grounding
Dec 11, 2025Evaluating large language models (LLMs) has recently emerged as a critical issue for safe and trustworthy application of LLMs in the medical domain. Although a variety of static medical question-answering (QA) benchmarks have been proposed, many aspects remain underexplored, such as the effectiveness of LLMs in generating responses in dynamic, interactive clinical multi-turn conversation situations and the identification of multi-faceted evaluation strategies beyond simple accuracy. However, formally evaluating a dynamic, interactive clinical situation is hindered by its vast combinatorial space of possible patient states and interaction trajectories, making it difficult to standardize and quantitatively measure such scenarios. Here, we introduce AutoMedic, a multi-agent simulation framework that enables automated evaluation of LLMs as clinical conversational agents. AutoMedic transforms off-the-shelf static QA datasets into virtual patient profiles, enabling realistic and clinically grounded multi-turn clinical dialogues between LLM agents. The performance of various clinical conversational agents is then assessed based on our CARE metric, which provides a multi-faceted evaluation standard of clinical conversational accuracy, efficiency/strategy, empathy, and robustness. Our findings, validated by human experts, demonstrate the validity of AutoMedic as an automated evaluation framework for clinical conversational agents, offering practical guidelines for the effective development of LLMs in conversational medical applications.
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
Rethinking Test-Time Scaling for Medical AI: Model and Task-Aware Strategies for LLMs and VLMs
Jun 16, 2025



Test-time scaling has recently emerged as a promising approach for enhancing the reasoning capabilities of large language models or vision-language models during inference. Although a variety of test-time scaling strategies have been proposed, and interest in their application to the medical domain is growing, many critical aspects remain underexplored, including their effectiveness for vision-language models and the identification of optimal strategies for different settings. In this paper, we conduct a comprehensive investigation of test-time scaling in the medical domain. We evaluate its impact on both large language models and vision-language models, considering factors such as model size, inherent model characteristics, and task complexity. Finally, we assess the robustness of these strategies under user-driven factors, such as misleading information embedded in prompts. Our findings offer practical guidelines for the effective use of test-time scaling in medical applications and provide insights into how these strategies can be further refined to meet the reliability and interpretability demands of the medical domain.
Towards a general-purpose foundation model for fMRI analysis
Jun 11, 2025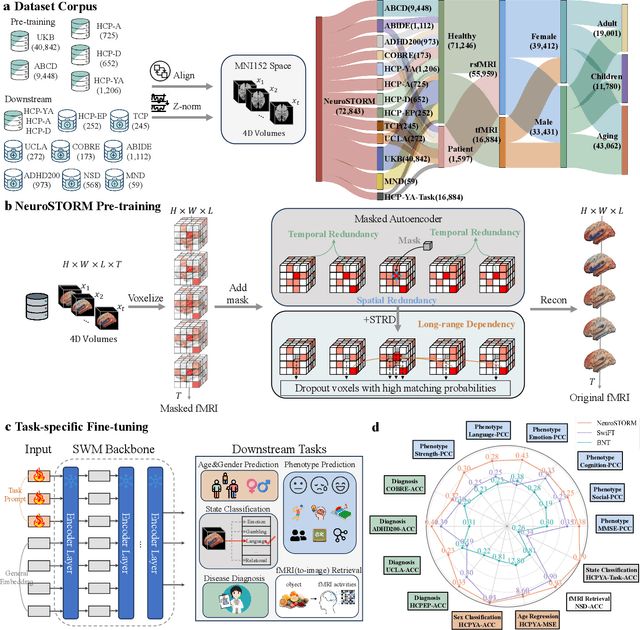

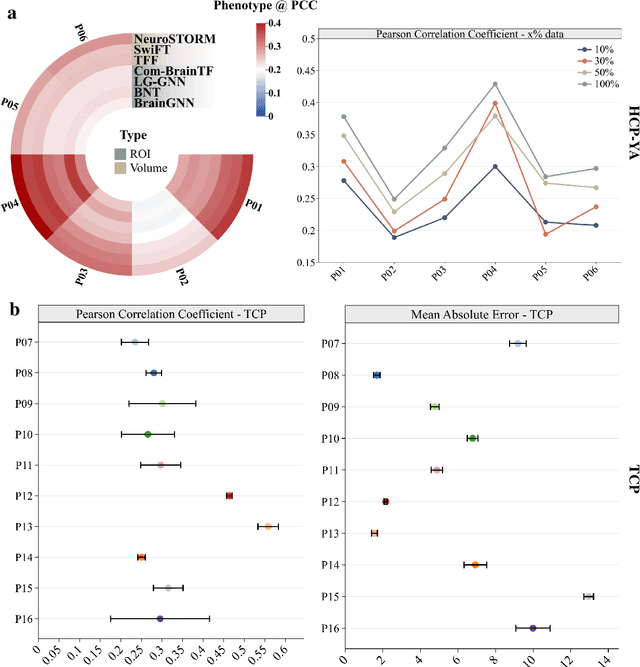
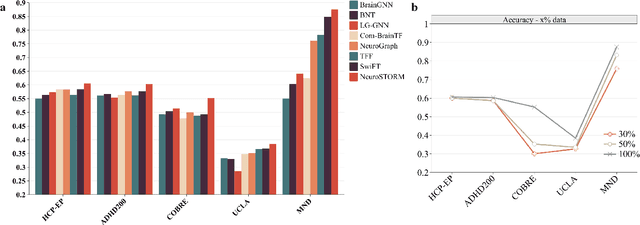
Functional Magnetic Resonance Imaging (fMRI) is essential for studying brain function and diagnosing neurological disorders, but current analysis methods face reproducibility and transferability issues due to complex pre-processing and task-specific models. We introduce NeuroSTORM (Neuroimaging Foundation Model with Spatial-Temporal Optimized Representation Modeling), a generalizable framework that directly learns from 4D fMRI volumes and enables efficient knowledge transfer across diverse applications. NeuroSTORM is pre-trained on 28.65 million fMRI frames (>9,000 hours) from over 50,000 subjects across multiple centers and ages 5 to 100. Using a Mamba backbone and a shifted scanning strategy, it efficiently processes full 4D volumes. We also propose a spatial-temporal optimized pre-training approach and task-specific prompt tuning to improve transferability. NeuroSTORM outperforms existing methods across five tasks: age/gender prediction, phenotype prediction, disease diagnosis, fMRI-to-image retrieval, and task-based fMRI classification. It demonstrates strong clinical utility on datasets from hospitals in the U.S., South Korea, and Australia, achieving top performance in disease diagnosis and cognitive phenotype prediction. NeuroSTORM provides a standardized, open-source foundation model to improve reproducibility and transferability in fMRI-based clinical research.
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Mar 20, 2025We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Mar 15, 2025Recent progress in 3D/4D scene generation emphasizes the importance of physical alignment throughout video generation and scene reconstruction. However, existing methods improve the alignment separately at each stage, making it difficult to manage subtle misalignments arising from another stage. Here, we present SteerX, a zero-shot inference-time steering method that unifies scene reconstruction into the generation process, tilting data distributions toward better geometric alignment. To this end, we introduce two geometric reward functions for 3D/4D scene generation by using pose-free feed-forward scene reconstruction models. Through extensive experiments, we demonstrate the effectiveness of SteerX in improving 3D/4D scene generation.
A Foundational Brain Dynamics Model via Stochastic Optimal Control
Feb 07, 2025We introduce a foundational model for brain dynamics that utilizes stochastic optimal control (SOC) and amortized inference. Our method features a continuous-discrete state space model (SSM) that can robustly handle the intricate and noisy nature of fMRI signals. To address computational limitations, we implement an approximation strategy grounded in the SOC framework. Additionally, we present a simulation-free latent dynamics approach that employs locally linear approximations, facilitating efficient and scalable inference. For effective representation learning, we derive an Evidence Lower Bound (ELBO) from the SOC formulation, which integrates smoothly with recent advancements in self-supervised learning (SSL), thereby promoting robust and transferable representations. Pre-trained on extensive datasets such as the UKB, our model attains state-of-the-art results across a variety of downstream tasks, including demographic prediction, trait analysis, disease diagnosis, and prognosis. Moreover, evaluating on external datasets such as HCP-A, ABIDE, and ADHD200 further validates its superior abilities and resilience across different demographic and clinical distributions. Our foundational model provides a scalable and efficient approach for deciphering brain dynamics, opening up numerous applications in neuroscience.
ContextMRI: Enhancing Compressed Sensing MRI through Metadata Conditioning
Jan 08, 2025Compressed sensing MRI seeks to accelerate MRI acquisition processes by sampling fewer k-space measurements and then reconstructing the missing data algorithmically. The success of these approaches often relies on strong priors or learned statistical models. While recent diffusion model-based priors have shown great potential, previous methods typically ignore clinically available metadata (e.g. patient demographics, imaging parameters, slice-specific information). In practice, metadata contains meaningful cues about the anatomy and acquisition protocol, suggesting it could further constrain the reconstruction problem. In this work, we propose ContextMRI, a text-conditioned diffusion model for MRI that integrates granular metadata into the reconstruction process. We train a pixel-space diffusion model directly on minimally processed, complex-valued MRI images. During inference, metadata is converted into a structured text prompt and fed to the model via CLIP text embeddings. By conditioning the prior on metadata, we unlock more accurate reconstructions and show consistent gains across multiple datasets, acceleration factors, and undersampling patterns. Our experiments demonstrate that increasing the fidelity of metadata, ranging from slice location and contrast to patient age, sex, and pathology, systematically boosts reconstruction performance. This work highlights the untapped potential of leveraging clinical context for inverse problems and opens a new direction for metadata-driven MRI reconstruction.
PSYCHE: A Multi-faceted Patient Simulation Framework for Evaluation of Psychiatric Assessment Conversational Agents
Jan 03, 2025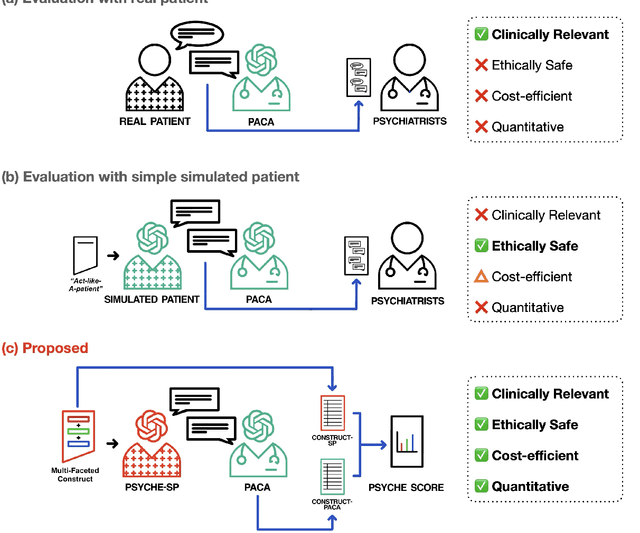



Recent advances in large language models (LLMs) have accelerated the development of conversational agents capable of generating human-like responses. Since psychiatric assessments typically involve complex conversational interactions between psychiatrists and patients, there is growing interest in developing LLM-based psychiatric assessment conversational agents (PACAs) that aim to simulate the role of psychiatrists in clinical evaluations. However, standardized methods for benchmarking the clinical appropriateness of PACAs' interaction with patients still remain underexplored. Here, we propose PSYCHE, a novel framework designed to enable the 1) clinically relevant, 2) ethically safe, 3) cost-efficient, and 4) quantitative evaluation of PACAs. This is achieved by simulating psychiatric patients based on a multi-faceted psychiatric construct that defines the simulated patients' profiles, histories, and behaviors, which PACAs are expected to assess. We validate the effectiveness of PSYCHE through a study with 10 board-certified psychiatrists, supported by an in-depth analysis of the simulated patient utterances.