 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Jan 22, 2026Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V
Improving Video Diffusion Transformer Training by Multi-Feature Fusion and Alignment from Self-Supervised Vision Encoders
Sep 11, 2025Video diffusion models have advanced rapidly in the recent years as a result of series of architectural innovations (e.g., diffusion transformers) and use of novel training objectives (e.g., flow matching). In contrast, less attention has been paid to improving the feature representation power of such models. In this work, we show that training video diffusion models can benefit from aligning the intermediate features of the video generator with feature representations of pre-trained vision encoders. We propose a new metric and conduct an in-depth analysis of various vision encoders to evaluate their discriminability and temporal consistency, thereby assessing their suitability for video feature alignment. Based on the analysis, we present Align4Gen which provides a novel multi-feature fusion and alignment method integrated into video diffusion model training. We evaluate Align4Gen both for unconditional and class-conditional video generation tasks and show that it results in improved video generation as quantified by various metrics. Full video results are available on our project page: https://align4gen.github.io/align4gen/
ContextMRI: Enhancing Compressed Sensing MRI through Metadata Conditioning
Jan 08, 2025Compressed sensing MRI seeks to accelerate MRI acquisition processes by sampling fewer k-space measurements and then reconstructing the missing data algorithmically. The success of these approaches often relies on strong priors or learned statistical models. While recent diffusion model-based priors have shown great potential, previous methods typically ignore clinically available metadata (e.g. patient demographics, imaging parameters, slice-specific information). In practice, metadata contains meaningful cues about the anatomy and acquisition protocol, suggesting it could further constrain the reconstruction problem. In this work, we propose ContextMRI, a text-conditioned diffusion model for MRI that integrates granular metadata into the reconstruction process. We train a pixel-space diffusion model directly on minimally processed, complex-valued MRI images. During inference, metadata is converted into a structured text prompt and fed to the model via CLIP text embeddings. By conditioning the prior on metadata, we unlock more accurate reconstructions and show consistent gains across multiple datasets, acceleration factors, and undersampling patterns. Our experiments demonstrate that increasing the fidelity of metadata, ranging from slice location and contrast to patient age, sex, and pathology, systematically boosts reconstruction performance. This work highlights the untapped potential of leveraging clinical context for inverse problems and opens a new direction for metadata-driven MRI reconstruction.
Optical-Flow Guided Prompt Optimization for Coherent Video Generation
Nov 23, 2024While text-to-video diffusion models have made significant strides, many still face challenges in generating videos with temporal consistency. Within diffusion frameworks, guidance techniques have proven effective in enhancing output quality during inference; however, applying these methods to video diffusion models introduces additional complexity of handling computations across entire sequences. To address this, we propose a novel framework called MotionPrompt that guides the video generation process via optical flow. Specifically, we train a discriminator to distinguish optical flow between random pairs of frames from real videos and generated ones. Given that prompts can influence the entire video, we optimize learnable token embeddings during reverse sampling steps by using gradients from a trained discriminator applied to random frame pairs. This approach allows our method to generate visually coherent video sequences that closely reflect natural motion dynamics, without compromising the fidelity of the generated content. We demonstrate the effectiveness of our approach across various models.
ACDC: Autoregressive Coherent Multimodal Generation using Diffusion Correction
Oct 07, 2024

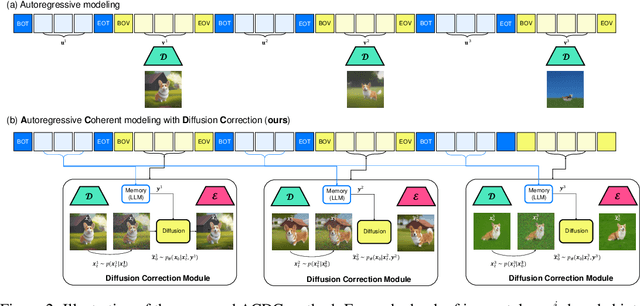
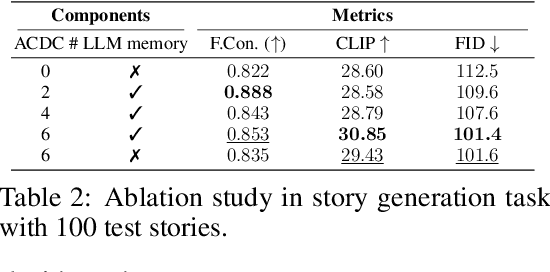
Autoregressive models (ARMs) and diffusion models (DMs) represent two leading paradigms in generative modeling, each excelling in distinct areas: ARMs in global context modeling and long-sequence generation, and DMs in generating high-quality local contexts, especially for continuous data such as images and short videos. However, ARMs often suffer from exponential error accumulation over long sequences, leading to physically implausible results, while DMs are limited by their local context generation capabilities. In this work, we introduce Autoregressive Coherent multimodal generation with Diffusion Correction (ACDC), a zero-shot approach that combines the strengths of both ARMs and DMs at the inference stage without the need for additional fine-tuning. ACDC leverages ARMs for global context generation and memory-conditioned DMs for local correction, ensuring high-quality outputs by correcting artifacts in generated multimodal tokens. In particular, we propose a memory module based on large language models (LLMs) that dynamically adjusts the conditioning texts for the DMs, preserving crucial global context information. Our experiments on multimodal tasks, including coherent multi-frame story generation and autoregressive video generation, demonstrate that ACDC effectively mitigates the accumulation of errors and significantly enhances the quality of generated outputs, achieving superior performance while remaining agnostic to specific ARM and DM architectures. Project page: https://acdc2025.github.io/
VideoGuide: Improving Video Diffusion Models without Training Through a Teacher's Guide
Oct 06, 2024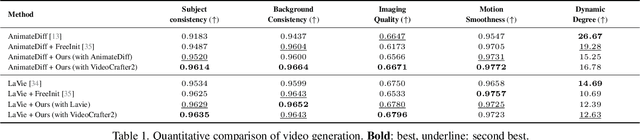
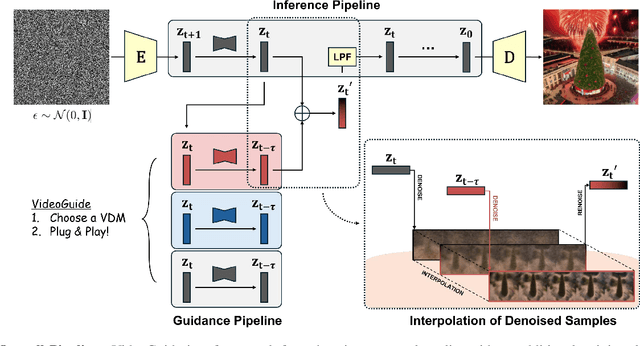


Text-to-image (T2I) diffusion models have revolutionized visual content creation, but extending these capabilities to text-to-video (T2V) generation remains a challenge, particularly in preserving temporal consistency. Existing methods that aim to improve consistency often cause trade-offs such as reduced imaging quality and impractical computational time. To address these issues we introduce VideoGuide, a novel framework that enhances the temporal consistency of pretrained T2V models without the need for additional training or fine-tuning. Instead, VideoGuide leverages any pretrained video diffusion model (VDM) or itself as a guide during the early stages of inference, improving temporal quality by interpolating the guiding model's denoised samples into the sampling model's denoising process. The proposed method brings about significant improvement in temporal consistency and image fidelity, providing a cost-effective and practical solution that synergizes the strengths of various video diffusion models. Furthermore, we demonstrate prior distillation, revealing that base models can achieve enhanced text coherence by utilizing the superior data prior of the guiding model through the proposed method. Project Page: http://videoguide2025.github.io/