 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTeP: A General and Scalable Framework for Solving Video Inverse Problems with Spatiotemporal Diffusion Priors
Apr 10, 2025We study how to solve general Bayesian inverse problems involving videos using diffusion model priors. While it is desirable to use a video diffusion prior to effectively capture complex temporal relationships, due to the computational and data requirements of training such a model, prior work has instead relied on image diffusion priors on single frames combined with heuristics to enforce temporal consistency. However, these approaches struggle with faithfully recovering the underlying temporal relationships, particularly for tasks with high temporal uncertainty. In this paper, we demonstrate the feasibility of practical and accessible spatiotemporal diffusion priors by fine-tuning latent video diffusion models from pretrained image diffusion models using limited videos in specific domains. Leveraging this plug-and-play spatiotemporal diffusion prior, we introduce a general and scalable framework for solving video inverse problems. We then apply our framework to two challenging scientific video inverse problems--black hole imaging and dynamic MRI. Our framework enables the generation of diverse, high-fidelity video reconstructions that not only fit observations but also recover multi-modal solutions. By incorporating a spatiotemporal diffusion prior, we significantly improve our ability to capture complex temporal relationships in the data while also enhancing spatial fidelity.
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
Mar 14, 2025



Plug-and-play diffusion priors (PnPDP) have emerged as a promising research direction for solving inverse problems. However, current studies primarily focus on natural image restoration, leaving the performance of these algorithms in scientific inverse problems largely unexplored. To address this gap, we introduce \textsc{InverseBench}, a framework that evaluates diffusion models across five distinct scientific inverse problems. These problems present unique structural challenges that differ from existing benchmarks, arising from critical scientific applications such as optical tomography, medical imaging, black hole imaging, seismology, and fluid dynamics. With \textsc{InverseBench}, we benchmark 14 inverse problem algorithms that use plug-and-play diffusion priors against strong, domain-specific baselines, offering valuable new insights into the strengths and weaknesses of existing algorithms. To facilitate further research and development, we open-source the codebase, along with datasets and pre-trained models, at https://devzhk.github.io/InverseBench/.
HumorReject: Decoupling LLM Safety from Refusal Prefix via A Little Humor
Jan 23, 2025

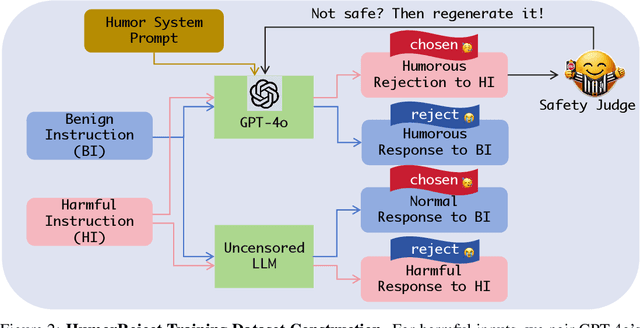
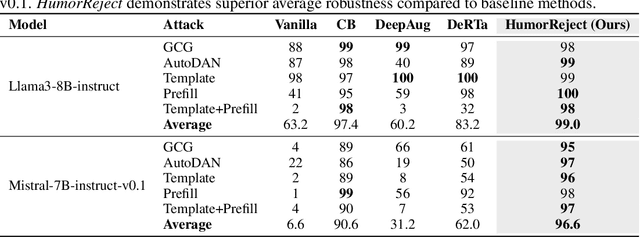
Large Language Models (LLMs) commonly rely on explicit refusal prefixes for safety, making them vulnerable to prefix injection attacks. We introduce HumorReject, a novel data-driven approach that fundamentally reimagines LLM safety by decoupling it from refusal prefixes through the use of humor as an indirect refusal strategy. Rather than explicitly rejecting harmful instructions, HumorReject responds with contextually appropriate humor that naturally defuses potentially dangerous requests while maintaining engaging interactions. Our approach effectively addresses the common "over-defense" issues in existing safety mechanisms, demonstrating superior robustness against various attack vectors while preserving natural and high-quality interactions on legitimate tasks. Our findings suggest that innovations at the data level are even more fundamental than the alignment algorithm itself in achieving effective LLM safety, opening new directions for developing more resilient and user-friendly AI systems.
ContextMRI: Enhancing Compressed Sensing MRI through Metadata Conditioning
Jan 08, 2025Compressed sensing MRI seeks to accelerate MRI acquisition processes by sampling fewer k-space measurements and then reconstructing the missing data algorithmically. The success of these approaches often relies on strong priors or learned statistical models. While recent diffusion model-based priors have shown great potential, previous methods typically ignore clinically available metadata (e.g. patient demographics, imaging parameters, slice-specific information). In practice, metadata contains meaningful cues about the anatomy and acquisition protocol, suggesting it could further constrain the reconstruction problem. In this work, we propose ContextMRI, a text-conditioned diffusion model for MRI that integrates granular metadata into the reconstruction process. We train a pixel-space diffusion model directly on minimally processed, complex-valued MRI images. During inference, metadata is converted into a structured text prompt and fed to the model via CLIP text embeddings. By conditioning the prior on metadata, we unlock more accurate reconstructions and show consistent gains across multiple datasets, acceleration factors, and undersampling patterns. Our experiments demonstrate that increasing the fidelity of metadata, ranging from slice location and contrast to patient age, sex, and pathology, systematically boosts reconstruction performance. This work highlights the untapped potential of leveraging clinical context for inverse problems and opens a new direction for metadata-driven MRI reconstruction.
Mining Glitch Tokens in Large Language Models via Gradient-based Discrete Optimization
Oct 19, 2024
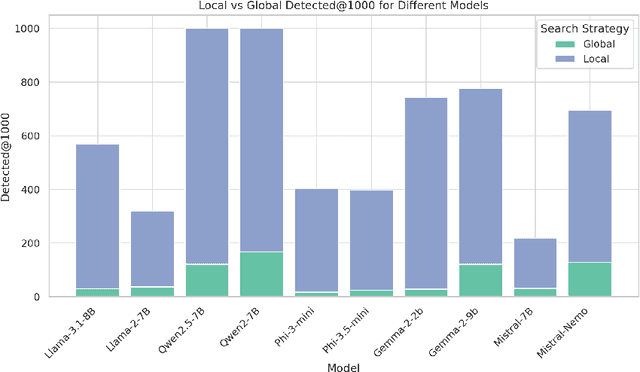
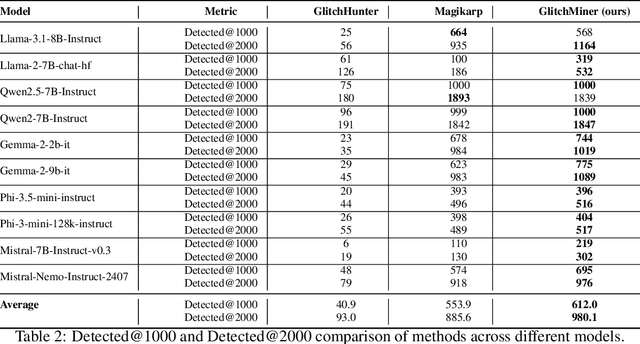
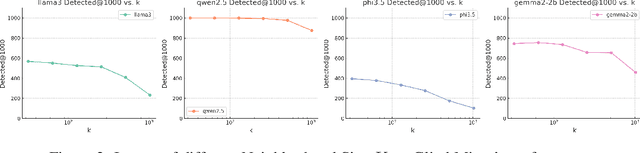
Glitch tokens in Large Language Models (LLMs) can trigger unpredictable behaviors, compromising model reliability and safety. Existing detection methods often rely on manual observation to infer the prior distribution of glitch tokens, which is inefficient and lacks adaptability across diverse model architectures. To address these limitations, we introduce GlitchMiner, a gradient-based discrete optimization framework designed for efficient glitch token detection in LLMs. GlitchMiner leverages an entropy-based loss function to quantify the uncertainty in model predictions and integrates first-order Taylor approximation with a local search strategy to effectively explore the token space. Our evaluation across various mainstream LLM architectures demonstrates that GlitchMiner surpasses existing methods in both detection precision and adaptability. In comparison to the previous state-of-the-art, GlitchMiner achieves an average improvement of 19.07% in precision@1000 for glitch token detection. By enabling efficient detection of glitch tokens, GlitchMiner provides a valuable tool for assessing and mitigating potential vulnerabilities in LLMs, contributing to their overall security.
The Dark Side of Function Calling: Pathways to Jailbreaking Large Language Models
Jul 25, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their power comes with significant security considerations. While extensive research has been conducted on the safety of LLMs in chat mode, the security implications of their function calling feature have been largely overlooked. This paper uncovers a critical vulnerability in the function calling process of LLMs, introducing a novel "jailbreak function" attack method that exploits alignment discrepancies, user coercion, and the absence of rigorous safety filters. Our empirical study, conducted on six state-of-the-art LLMs including GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-pro, reveals an alarming average success rate of over 90\% for this attack. We provide a comprehensive analysis of why function calls are susceptible to such attacks and propose defensive strategies, including the use of defensive prompts. Our findings highlight the urgent need for enhanced security measures in the function calling capabilities of LLMs, contributing to the field of AI safety by identifying a previously unexplored risk, designing an effective attack method, and suggesting practical defensive measures. Our code is available at https://github.com/wooozihui/jailbreakfunction.
Principled Probabilistic Imaging using Diffusion Models as Plug-and-Play Priors
May 29, 2024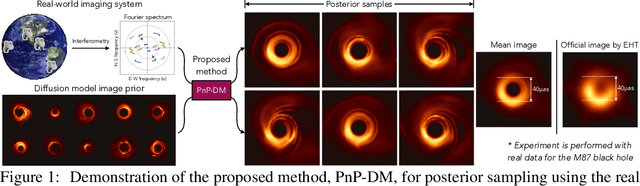
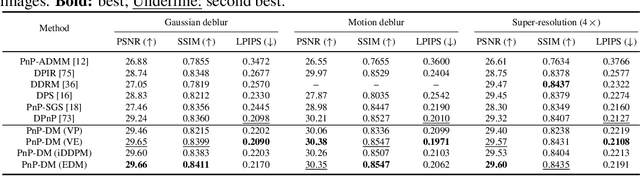
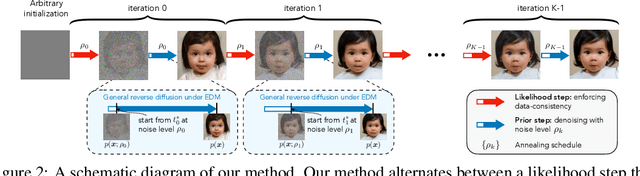

Diffusion models (DMs) have recently shown outstanding capability in modeling complex image distributions, making them expressive image priors for solving Bayesian inverse problems. However, most existing DM-based methods rely on approximations in the generative process to be generic to different inverse problems, leading to inaccurate sample distributions that deviate from the target posterior defined within the Bayesian framework. To harness the generative power of DMs while avoiding such approximations, we propose a Markov chain Monte Carlo algorithm that performs posterior sampling for general inverse problems by reducing it to sampling the posterior of a Gaussian denoising problem. Crucially, we leverage a general DM formulation as a unified interface that allows for rigorously solving the denoising problem with a range of state-of-the-art DMs. We demonstrate the effectiveness of the proposed method on six inverse problems (three linear and three nonlinear), including a real-world black hole imaging problem. Experimental results indicate that our proposed method offers more accurate reconstructions and posterior estimation compared to existing DM-based imaging inverse methods.
Provable Probabilistic Imaging using Score-Based Generative Priors
Oct 16, 2023Estimating high-quality images while also quantifying their uncertainty are two desired features in an image reconstruction algorithm for solving ill-posed inverse problems. In this paper, we propose plug-and-play Monte Carlo (PMC) as a principled framework for characterizing the space of possible solutions to a general inverse problem. PMC is able to incorporate expressive score-based generative priors for high-quality image reconstruction while also performing uncertainty quantification via posterior sampling. In particular, we introduce two PMC algorithms which can be viewed as the sampling analogues of the traditional plug-and-play priors (PnP) and regularization by denoising (RED) algorithms. We also establish a theoretical analysis for characterizing the convergence of the PMC algorithms. Our analysis provides non-asymptotic stationarity guarantees for both algorithms, even in the presence of non-log-concave likelihoods and imperfect score networks. We demonstrate the performance of the PMC algorithms on multiple representative inverse problems with both linear and nonlinear forward models. Experimental results show that PMC significantly improves reconstruction quality and enables high-fidelity uncertainty quantification.
AdvFunMatch: When Consistent Teaching Meets Adversarial Robustness
May 25, 2023

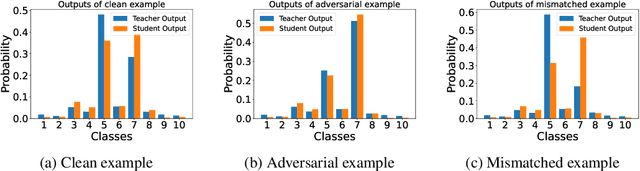
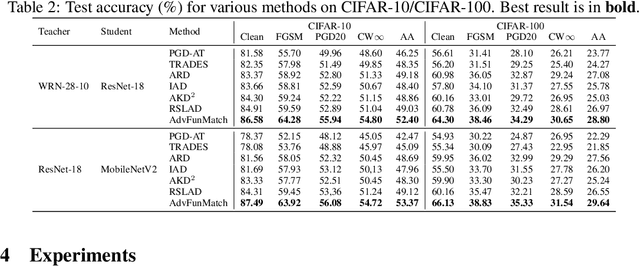
\emph{Consistent teaching} is an effective paradigm for implementing knowledge distillation (KD), where both student and teacher models receive identical inputs, and KD is treated as a function matching task (FunMatch). However, one limitation of FunMatch is that it does not account for the transfer of adversarial robustness, a model's resistance to adversarial attacks. To tackle this problem, we propose a simple but effective strategy called Adversarial Function Matching (AdvFunMatch), which aims to match distributions for all data points within the $\ell_p$-norm ball of the training data, in accordance with consistent teaching. Formulated as a min-max optimization problem, AdvFunMatch identifies the worst-case instances that maximizes the KL-divergence between teacher and student model outputs, which we refer to as "mismatched examples," and then matches the outputs on these mismatched examples. Our experimental results show that AdvFunMatch effectively produces student models with both high clean accuracy and robustness. Furthermore, we reveal that strong data augmentations (\emph{e.g.}, AutoAugment) are beneficial in AdvFunMatch, whereas prior works have found them less effective in adversarial training. Code is available at \url{https://gitee.com/zihui998/adv-fun-match}.
Demystifying Oversmoothing in Attention-Based Graph Neural Networks
May 25, 2023
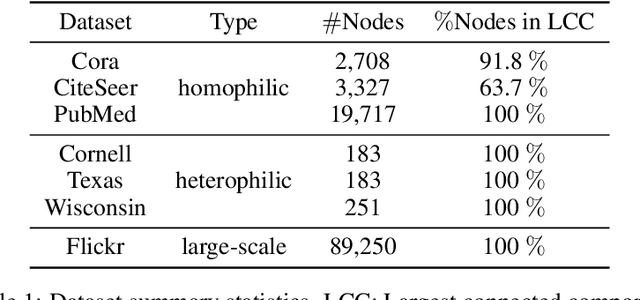
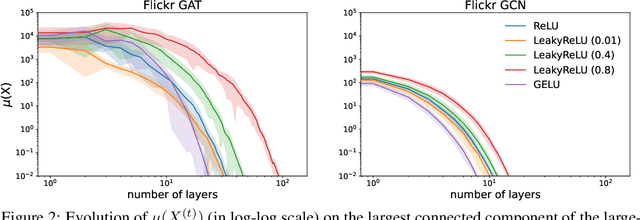
Oversmoothing in Graph Neural Networks (GNNs) refers to the phenomenon where increasing network depth leads to homogeneous node representations. While previous work has established that Graph Convolutional Networks (GCNs) exponentially lose expressive power, it remains controversial whether the graph attention mechanism can mitigate oversmoothing. In this work, we provide a definitive answer to this question through a rigorous mathematical analysis, by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools and techniques from the theory of products of inhomogeneous matrices and the joint spectral radius. We establish that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and loses expressive power exponentially. The proposed framework extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models. In particular, our analysis accounts for asymmetric, state-dependent and time-varying aggregation operators and a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU and SiLU.