 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Worst-Case Weighted Latency for Multi-Robot Persistent Monitoring: Theory and RL-Based Solutions
May 10, 2026We study multi-robot persistent monitoring on weighted graphs, where node weights encode monitoring priorities and edge weights encode travel distances. The goal is to design joint robot trajectories that minimize the worst-case weighted latency across all nodes over an infinite time horizon. The widely adopted worst-case latency objective evaluates team performance over the entire time horizon and therefore may fail to distinguish strategies with poor transient behavior but strong asymptotic performance. To address this limitation, we propose a family of tail-performance objectives that generalize the standard objective and study the resulting functional optimization problems. We establish several key theoretical properties, including the existence of optimal strategies, relationships among the proposed objectives and their corresponding optimization problems, approximation by periodic solutions to arbitrary accuracy, and reductions to event-driven decision models with discretized waiting times. Building on these results, we construct an equivalent event-driven Markov decision process (MDP), called the Tail Worst-case Latency-Optimizing Markov Decision Process (TWLO-MDP), which reformulates the tail-performance objective as a standard average-reward criterion. We then develop reinforcement-learning-based solution methods for the TWLO-MDP and introduce the multi-robot monitoring benchmark (M2Bench), a unified platform that supports the evaluation and comparison of heuristic and learning-based monitoring algorithms. Experiments on synthetic and realistic monitoring scenarios show that our methods effectively reduce the worst-case weighted latency and outperform representative baselines.
Aucamp: An Underwater Camera-Based Multi-Robot Platform with Low-Cost, Distributed, and Robust Localization
Jun 11, 2025
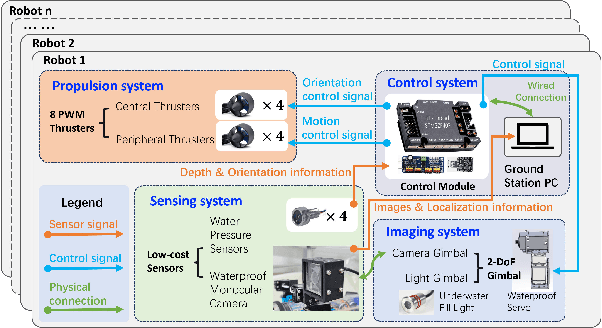

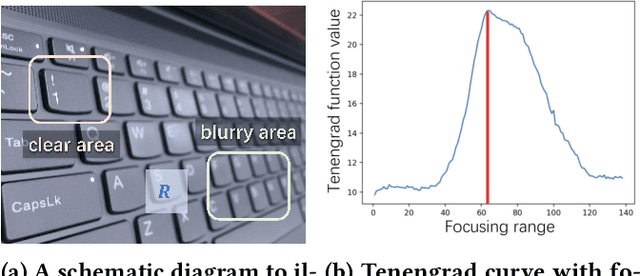
This paper introduces an underwater multi-robot platform, named Aucamp, characterized by cost-effective monocular-camera-based sensing, distributed protocol and robust orientation control for localization. We utilize the clarity feature to measure the distance, present the monocular imaging model, and estimate the position of the target object. We achieve global positioning in our platform by designing a distributed update protocol. The distributed algorithm enables the perception process to simultaneously cover a broader range, and greatly improves the accuracy and robustness of the positioning. Moreover, the explicit dynamics model of the robot in our platform is obtained, based on which, we propose a robust orientation control framework. The control system ensures that the platform maintains a balanced posture for each robot, thereby ensuring the stability of the localization system. The platform can swiftly recover from an forced unstable state to a stable horizontal posture. Additionally, we conduct extensive experiments and application scenarios to evaluate the performance of our platform. The proposed new platform may provide support for extensive marine exploration by underwater sensor networks.
Formation Maneuver Control Based on the Augmented Laplacian Method
May 09, 2025This paper proposes a novel formation maneuver control method for both 2-D and 3-D space, which enables the formation to translate, scale, and rotate with arbitrary orientation. The core innovation is the novel design of weights in the proposed augmented Laplacian matrix. Instead of using scalars, we represent weights as matrices, which are designed based on a specified rotation axis and allow the formation to perform rotation in 3-D space. To further improve the flexibility and scalability of the formation, the rotational axis adjustment approach and dynamic agent reconfiguration method are developed, allowing formations to rotate around arbitrary axes in 3-D space and new agents to join the formation. Theoretical analysis is provided to show that the proposed approach preserves the original configuration of the formation. The proposed method maintains the advantages of the complex Laplacian-based method, including reduced neighbor requirements and no reliance on generic or convex nominal configurations, while achieving arbitrary orientation rotations via a more simplified implementation. Simulations in both 2-D and 3-D space validate the effectiveness of the proposed method.
AquaGS: Fast Underwater Scene Reconstruction with SfM-Free Gaussian Splatting
May 03, 2025Underwater scene reconstruction is a critical tech-nology for underwater operations, enabling the generation of 3D models from images captured by underwater platforms. However, the quality of underwater images is often degraded due to medium interference, which limits the effectiveness of Structure-from-Motion (SfM) pose estimation, leading to subsequent reconstruction failures. Additionally, SfM methods typically operate at slower speeds, further hindering their applicability in real-time scenarios. In this paper, we introduce AquaGS, an SfM-free underwater scene reconstruction model based on the SeaThru algorithm, which facilitates rapid and accurate separation of scene details and medium features. Our approach initializes Gaussians by integrating state-of-the-art multi-view stereo (MVS) technology, employs implicit Neural Radiance Fields (NeRF) for rendering translucent media and utilizes the latest explicit 3D Gaussian Splatting (3DGS) technique to render object surfaces, which effectively addresses the limitations of traditional methods and accurately simulates underwater optical phenomena. Experimental results on the data set and the robot platform show that our model can complete high-precision reconstruction in 30 seconds with only 3 image inputs, significantly enhancing the practical application of the algorithm in robotic platforms.
Analysis of On-policy Policy Gradient Methods under the Distribution Mismatch
Mar 28, 2025Policy gradient methods are one of the most successful methods for solving challenging reinforcement learning problems. However, despite their empirical successes, many SOTA policy gradient algorithms for discounted problems deviate from the theoretical policy gradient theorem due to the existence of a distribution mismatch. In this work, we analyze the impact of this mismatch on the policy gradient methods. Specifically, we first show that in the case of tabular parameterizations, the methods under the mismatch remain globally optimal. Then, we extend this analysis to more general parameterizations by leveraging the theory of biased stochastic gradient descent. Our findings offer new insights into the robustness of policy gradient methods as well as the gap between theoretical foundations and practical implementations.
Advancing Pancreatic Cancer Prediction with a Next Visit Token Prediction Head on top of Med-BERT
Jan 03, 2025



Background: Recently, numerous foundation models pretrained on extensive data have demonstrated efficacy in disease prediction using Electronic Health Records (EHRs). However, there remains some unanswered questions on how to best utilize such models especially with very small fine-tuning cohorts. Methods: We utilized Med-BERT, an EHR-specific foundation model, and reformulated the disease binary prediction task into a token prediction task and a next visit mask token prediction task to align with Med-BERT's pretraining task format in order to improve the accuracy of pancreatic cancer (PaCa) prediction in both few-shot and fully supervised settings. Results: The reformulation of the task into a token prediction task, referred to as Med-BERT-Sum, demonstrates slightly superior performance in both few-shot scenarios and larger data samples. Furthermore, reformulating the prediction task as a Next Visit Mask Token Prediction task (Med-BERT-Mask) significantly outperforms the conventional Binary Classification (BC) prediction task (Med-BERT-BC) by 3% to 7% in few-shot scenarios with data sizes ranging from 10 to 500 samples. These findings highlight that aligning the downstream task with Med-BERT's pretraining objectives substantially enhances the model's predictive capabilities, thereby improving its effectiveness in predicting both rare and common diseases. Conclusion: Reformatting disease prediction tasks to align with the pretraining of foundation models enhances prediction accuracy, leading to earlier detection and timely intervention. This approach improves treatment effectiveness, survival rates, and overall patient outcomes for PaCa and potentially other cancers.
Prompting Large Language Models for Clinical Temporal Relation Extraction
Dec 04, 2024Objective: This paper aims to prompt large language models (LLMs) for clinical temporal relation extraction (CTRE) in both few-shot and fully supervised settings. Materials and Methods: This study utilizes four LLMs: Encoder-based GatorTron-Base (345M)/Large (8.9B); Decoder-based LLaMA3-8B/MeLLaMA-13B. We developed full (FFT) and parameter-efficient (PEFT) fine-tuning strategies and evaluated these strategies on the 2012 i2b2 CTRE task. We explored four fine-tuning strategies for GatorTron-Base: (1) Standard Fine-Tuning, (2) Hard-Prompting with Unfrozen LLMs, (3) Soft-Prompting with Frozen LLMs, and (4) Low-Rank Adaptation (LoRA) with Frozen LLMs. For GatorTron-Large, we assessed two PEFT strategies-Soft-Prompting and LoRA with Frozen LLMs-leveraging Quantization techniques. Additionally, LLaMA3-8B and MeLLaMA-13B employed two PEFT strategies: LoRA strategy with Quantization (QLoRA) applied to Frozen LLMs using instruction tuning and standard fine-tuning. Results: Under fully supervised settings, Hard-Prompting with Unfrozen GatorTron-Base achieved the highest F1 score (89.54%), surpassing the SOTA model (85.70%) by 3.74%. Additionally, two variants of QLoRA adapted to GatorTron-Large and Standard Fine-Tuning of GatorTron-Base exceeded the SOTA model by 2.36%, 1.88%, and 0.25%, respectively. Decoder-based models with frozen parameters outperformed their Encoder-based counterparts in this setting; however, the trend reversed in few-shot scenarios. Discussions and Conclusions: This study presented new methods that significantly improved CTRE performance, benefiting downstream tasks reliant on CTRE systems. The findings underscore the importance of selecting appropriate models and fine-tuning strategies based on task requirements and data availability. Future work will explore larger models and broader CTRE applications.
Smart Predict-then-Optimize Method with Dependent Data: Risk Bounds and Calibration of Autoregression
Nov 19, 2024The predict-then-optimize (PTO) framework is indispensable for addressing practical stochastic decision-making tasks. It consists of two crucial steps: initially predicting unknown parameters of an optimization model and subsequently solving the problem based on these predictions. Elmachtoub and Grigas [1] introduced the Smart Predict-then-Optimize (SPO) loss for the framework, which gauges the decision error arising from predicted parameters, and a convex surrogate, the SPO+ loss, which incorporates the underlying structure of the optimization model. The consistency of these different loss functions is guaranteed under the assumption of i.i.d. training data. Nevertheless, various types of data are often dependent, such as power load fluctuations over time. This dependent nature can lead to diminished model performance in testing or real-world applications. Motivated to make intelligent predictions for time series data, we present an autoregressive SPO method directly targeting the optimization problem at the decision stage in this paper, where the conditions of consistency are no longer met. Therefore, we first analyze the generalization bounds of the SPO loss within our autoregressive model. Subsequently, the uniform calibration results in Liu and Grigas [2] are extended in the proposed model. Finally, we conduct experiments to empirically demonstrate the effectiveness of the SPO+ surrogate compared to the absolute loss and the least squares loss, especially when the cost vectors are determined by stationary dynamical systems and demonstrate the relationship between normalized regret and mixing coefficients.
Stochastic Trajectory Optimization for Demonstration Imitation
Aug 07, 2024


Humans often learn new skills by imitating the experts and gradually developing their proficiency. In this work, we introduce Stochastic Trajectory Optimization for Demonstration Imitation (STODI), a trajectory optimization framework for robots to imitate the shape of demonstration trajectories with improved dynamic performance. Consistent with the human learning process, demonstration imitation serves as an initial step, while trajectory optimization aims to enhance robot motion performance. By generating random noise and constructing proper cost functions, the STODI effectively explores and exploits generated noisy trajectories while preserving the demonstration shape characteristics. We employ three metrics to measure the similarity of trajectories in both the time and frequency domains to help with demonstration imitation. Theoretical analysis reveals relationships among these metrics, emphasizing the benefits of frequency-domain analysis for specific tasks. Experiments on a 7-DOF robotic arm in the PyBullet simulator validate the efficacy of the STODI framework, showcasing the improved optimization performance and stability compared to previous methods.
The Dark Side of Function Calling: Pathways to Jailbreaking Large Language Models
Jul 25, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their power comes with significant security considerations. While extensive research has been conducted on the safety of LLMs in chat mode, the security implications of their function calling feature have been largely overlooked. This paper uncovers a critical vulnerability in the function calling process of LLMs, introducing a novel "jailbreak function" attack method that exploits alignment discrepancies, user coercion, and the absence of rigorous safety filters. Our empirical study, conducted on six state-of-the-art LLMs including GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-pro, reveals an alarming average success rate of over 90\% for this attack. We provide a comprehensive analysis of why function calls are susceptible to such attacks and propose defensive strategies, including the use of defensive prompts. Our findings highlight the urgent need for enhanced security measures in the function calling capabilities of LLMs, contributing to the field of AI safety by identifying a previously unexplored risk, designing an effective attack method, and suggesting practical defensive measures. Our code is available at https://github.com/wooozihui/jailbreakfunction.