 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAucamp: An Underwater Camera-Based Multi-Robot Platform with Low-Cost, Distributed, and Robust Localization
Jun 11, 2025
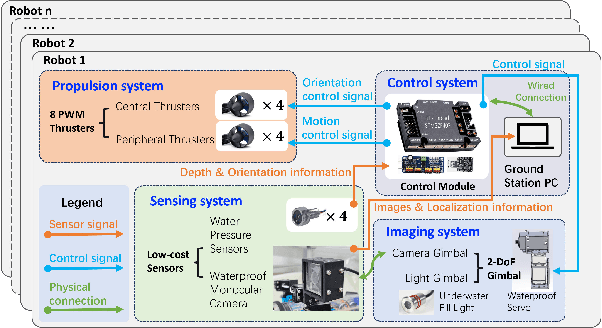

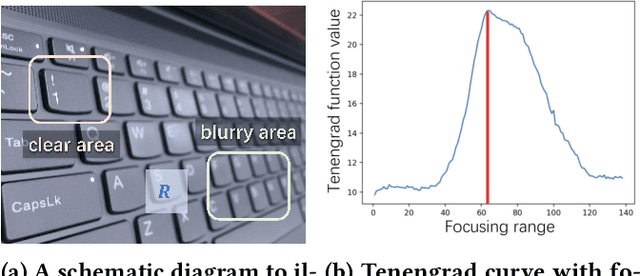
This paper introduces an underwater multi-robot platform, named Aucamp, characterized by cost-effective monocular-camera-based sensing, distributed protocol and robust orientation control for localization. We utilize the clarity feature to measure the distance, present the monocular imaging model, and estimate the position of the target object. We achieve global positioning in our platform by designing a distributed update protocol. The distributed algorithm enables the perception process to simultaneously cover a broader range, and greatly improves the accuracy and robustness of the positioning. Moreover, the explicit dynamics model of the robot in our platform is obtained, based on which, we propose a robust orientation control framework. The control system ensures that the platform maintains a balanced posture for each robot, thereby ensuring the stability of the localization system. The platform can swiftly recover from an forced unstable state to a stable horizontal posture. Additionally, we conduct extensive experiments and application scenarios to evaluate the performance of our platform. The proposed new platform may provide support for extensive marine exploration by underwater sensor networks.
IDEAL: Data Equilibrium Adaptation for Multi-Capability Language Model Alignment
May 19, 2025



Large Language Models (LLMs) have achieved impressive performance through Supervised Fine-tuning (SFT) on diverse instructional datasets. When training on multiple capabilities simultaneously, the mixture training dataset, governed by volumes of data from different domains, is a critical factor that directly impacts the final model's performance. Unlike many studies that focus on enhancing the quality of training datasets through data selection methods, few works explore the intricate relationship between the compositional quantity of mixture training datasets and the emergent capabilities of LLMs. Given the availability of a high-quality multi-domain training dataset, understanding the impact of data from each domain on the model's overall capabilities is crucial for preparing SFT data and training a well-balanced model that performs effectively across diverse domains. In this work, we introduce IDEAL, an innovative data equilibrium adaptation framework designed to effectively optimize volumes of data from different domains within mixture SFT datasets, thereby enhancing the model's alignment and performance across multiple capabilities. IDEAL employs a gradient-based approach to iteratively refine the training data distribution, dynamically adjusting the volumes of domain-specific data based on their impact on downstream task performance. By leveraging this adaptive mechanism, IDEAL ensures a balanced dataset composition, enabling the model to achieve robust generalization and consistent proficiency across diverse tasks. Experiments across different capabilities demonstrate that IDEAL outperforms conventional uniform data allocation strategies, achieving a comprehensive improvement of approximately 7% in multi-task evaluation scores.
Formation Maneuver Control Based on the Augmented Laplacian Method
May 09, 2025This paper proposes a novel formation maneuver control method for both 2-D and 3-D space, which enables the formation to translate, scale, and rotate with arbitrary orientation. The core innovation is the novel design of weights in the proposed augmented Laplacian matrix. Instead of using scalars, we represent weights as matrices, which are designed based on a specified rotation axis and allow the formation to perform rotation in 3-D space. To further improve the flexibility and scalability of the formation, the rotational axis adjustment approach and dynamic agent reconfiguration method are developed, allowing formations to rotate around arbitrary axes in 3-D space and new agents to join the formation. Theoretical analysis is provided to show that the proposed approach preserves the original configuration of the formation. The proposed method maintains the advantages of the complex Laplacian-based method, including reduced neighbor requirements and no reliance on generic or convex nominal configurations, while achieving arbitrary orientation rotations via a more simplified implementation. Simulations in both 2-D and 3-D space validate the effectiveness of the proposed method.
Analysis of On-policy Policy Gradient Methods under the Distribution Mismatch
Mar 28, 2025Policy gradient methods are one of the most successful methods for solving challenging reinforcement learning problems. However, despite their empirical successes, many SOTA policy gradient algorithms for discounted problems deviate from the theoretical policy gradient theorem due to the existence of a distribution mismatch. In this work, we analyze the impact of this mismatch on the policy gradient methods. Specifically, we first show that in the case of tabular parameterizations, the methods under the mismatch remain globally optimal. Then, we extend this analysis to more general parameterizations by leveraging the theory of biased stochastic gradient descent. Our findings offer new insights into the robustness of policy gradient methods as well as the gap between theoretical foundations and practical implementations.
Stochastic Trajectory Optimization for Demonstration Imitation
Aug 07, 2024


Humans often learn new skills by imitating the experts and gradually developing their proficiency. In this work, we introduce Stochastic Trajectory Optimization for Demonstration Imitation (STODI), a trajectory optimization framework for robots to imitate the shape of demonstration trajectories with improved dynamic performance. Consistent with the human learning process, demonstration imitation serves as an initial step, while trajectory optimization aims to enhance robot motion performance. By generating random noise and constructing proper cost functions, the STODI effectively explores and exploits generated noisy trajectories while preserving the demonstration shape characteristics. We employ three metrics to measure the similarity of trajectories in both the time and frequency domains to help with demonstration imitation. Theoretical analysis reveals relationships among these metrics, emphasizing the benefits of frequency-domain analysis for specific tasks. Experiments on a 7-DOF robotic arm in the PyBullet simulator validate the efficacy of the STODI framework, showcasing the improved optimization performance and stability compared to previous methods.
Inverse Reinforcement Learning with Unknown Reward Model based on Structural Risk Minimization
Dec 27, 2023Inverse reinforcement learning (IRL) usually assumes the model of the reward function is pre-specified and estimates the parameter only. However, how to determine a proper reward model is nontrivial. A simplistic model is less likely to contain the real reward function, while a model with high complexity leads to substantial computation cost and risks overfitting. This paper addresses this trade-off in IRL model selection by introducing the structural risk minimization (SRM) method from statistical learning. SRM selects an optimal reward function class from a hypothesis set minimizing both estimation error and model complexity. To formulate an SRM scheme for IRL, we estimate policy gradient by demonstration serving as empirical risk and establish the upper bound of Rademacher complexity of hypothesis classes as model penalty. The learning guarantee is further presented. In particular, we provide explicit SRM for the common linear weighted sum setting in IRL. Simulations demonstrate the performance and efficiency of our scheme.
Multiplayer Homicidal Chauffeur Reach-Avoid Games: A Pursuit Enclosure Function Approach
Nov 04, 2023This paper presents a multiplayer Homicidal Chauffeur reach-avoid differential game, which involves Dubins-car pursuers and simple-motion evaders. The goal of the pursuers is to cooperatively protect a planar convex region from the evaders, who strive to reach the region. We propose a cooperative strategy for the pursuers based on subgames for multiple pursuers against one evader and optimal task allocation. We introduce pursuit enclosure functions (PEFs) and propose a new enclosure region pursuit (ERP) winning approach that supports forward analysis for the strategy synthesis in the subgames. We show that if a pursuit coalition is able to defend the region against an evader under the ERP winning, then no more than two pursuers in the coalition are necessarily needed. We also propose a steer-to-ERP approach to certify the ERP winning and synthesize the ERP winning strategy. To implement the strategy, we introduce a positional PEF and provide the necessary parameters, states, and strategies that ensure the ERP winning for both one pursuer and two pursuers against one evader. Additionally, we formulate a binary integer program using the subgame outcomes to maximize the captured evaders in the ERP winning for the pursuit task allocation. Finally, we propose a multiplayer receding-horizon strategy where the ERP winnings are checked in each horizon, the task is allocated, and the strategies of the pursuers are determined. Numerical examples are provided to illustrate the results.
HiCRISP: A Hierarchical Closed-Loop Robotic Intelligent Self-Correction Planner
Sep 21, 2023



The integration of Large Language Models (LLMs) into robotics has revolutionized human-robot interactions and autonomous task planning. However, these systems are often unable to self-correct during the task execution, which hinders their adaptability in dynamic real-world environments. To address this issue, we present a Hierarchical Closed-loop Robotic Intelligent Self-correction Planner (HiCRISP), an innovative framework that enables robots to correct errors within individual steps during the task execution. HiCRISP actively monitors and adapts the task execution process, addressing both high-level planning and low-level action errors. Extensive benchmark experiments, encompassing virtual and real-world scenarios, showcase HiCRISP's exceptional performance, positioning it as a promising solution for robotic task planning with LLMs.
Affordance-Driven Next-Best-View Planning for Robotic Grasping
Sep 18, 2023Grasping occluded objects in cluttered environments is an essential component in complex robotic manipulation tasks. In this paper, we introduce an AffordanCE-driven Next-Best-View planning policy (ACE-NBV) that tries to find a feasible grasp for target object via continuously observing scenes from new viewpoints. This policy is motivated by the observation that the grasp affordances of an occluded object can be better-measured under the view when the view-direction are the same as the grasp view. Specifically, our method leverages the paradigm of novel view imagery to predict the grasps affordances under previously unobserved view, and select next observation view based on the gain of the highest imagined grasp quality of the target object. The experimental results in simulation and on the real robot demonstrate the effectiveness of the proposed affordance-driven next-best-view planning policy. Additional results, code, and videos of real robot experiments can be found in the supplementary materials.
Control Input Inference of Mobile Agents under Unknown Objective
Jul 20, 2023Trajectory and control secrecy is an important issue in robotics security. This paper proposes a novel algorithm for the control input inference of a mobile agent without knowing its control objective. Specifically, the algorithm first estimates the target state by applying external perturbations. Then we identify the objective function based on the inverse optimal control, providing the well-posedness proof and the identifiability analysis. Next, we obtain the optimal estimate of the control horizon using binary search. Finally, the agent's control optimization problem is reconstructed and solved to predict its input. Simulation illustrates the efficiency and the performance of the algorithm.