 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Adaptation for Spatio-Temporal Forecasting
Apr 11, 2024



Spatio-temporal forecasting is crucial in real-world dynamic systems, predicting future changes using historical data from diverse locations. Existing methods often prioritize the development of intricate neural networks to capture the complex dependencies of the data, yet their accuracy fails to show sustained improvement. Besides, these methods also overlook node heterogeneity, hindering customized prediction modules from handling diverse regional nodes effectively. In this paper, our goal is not to propose a new model but to present a novel low-rank adaptation framework as an off-the-shelf plugin for existing spatial-temporal prediction models, termed ST-LoRA, which alleviates the aforementioned problems through node-level adjustments. Specifically, we first tailor a node adaptive low-rank layer comprising multiple trainable low-rank matrices. Additionally, we devise a multi-layer residual fusion stacking module, injecting the low-rank adapters into predictor modules of various models. Across six real-world traffic datasets and six different types of spatio-temporal prediction models, our approach minimally increases the parameters and training time of the original models by less than 4%, still achieving consistent and sustained performance enhancement.
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Jan 20, 2024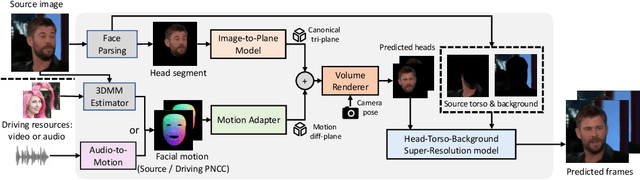

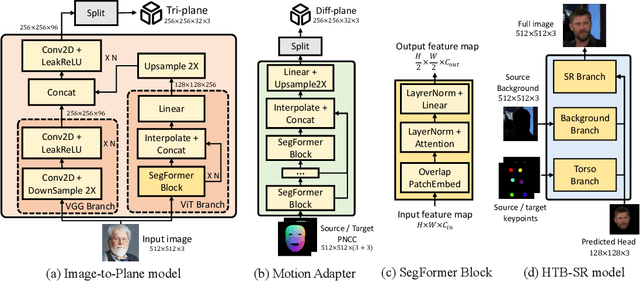
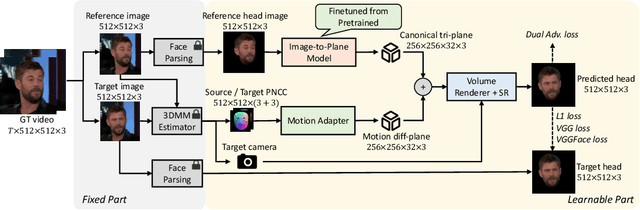
One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
Affordance-Driven Next-Best-View Planning for Robotic Grasping
Sep 18, 2023Grasping occluded objects in cluttered environments is an essential component in complex robotic manipulation tasks. In this paper, we introduce an AffordanCE-driven Next-Best-View planning policy (ACE-NBV) that tries to find a feasible grasp for target object via continuously observing scenes from new viewpoints. This policy is motivated by the observation that the grasp affordances of an occluded object can be better-measured under the view when the view-direction are the same as the grasp view. Specifically, our method leverages the paradigm of novel view imagery to predict the grasps affordances under previously unobserved view, and select next observation view based on the gain of the highest imagined grasp quality of the target object. The experimental results in simulation and on the real robot demonstrate the effectiveness of the proposed affordance-driven next-best-view planning policy. Additional results, code, and videos of real robot experiments can be found in the supplementary materials.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/