 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-LA: Difference-of-Convex Langevin Algorithm
Jan 30, 2026We study a sampling problem whose target distribution is $π\propto \exp(-f-r)$ where the data fidelity term $f$ is Lipschitz smooth while the regularizer term $r=r_1-r_2$ is a non-smooth difference-of-convex (DC) function, i.e., $r_1,r_2$ are convex. By leveraging the DC structure of $r$, we can smooth out $r$ by applying Moreau envelopes to $r_1$ and $r_2$ separately. In line of DC programming, we then redistribute the concave part of the regularizer to the data fidelity and study its corresponding proximal Langevin algorithm (termed DC-LA). We establish convergence of DC-LA to the target distribution $π$, up to discretization and smoothing errors, in the $q$-Wasserstein distance for all $q \in \mathbb{N}^*$, under the assumption that $V$ is distant dissipative. Our results improve previous work on non-log-concave sampling in terms of a more general framework and assumptions. Numerical experiments show that DC-LA produces accurate distributions in synthetic settings and reliably provides uncertainty quantification in a real-world Computed Tomography application.
Physics-Informed Design of Input Convex Neural Networks for Consistency Optimal Transport Flow Matching
Nov 08, 2025We propose a consistency model based on the optimal-transport flow. A physics-informed design of partially input-convex neural networks (PICNN) plays a central role in constructing the flow field that emulates the displacement interpolation. During the training stage, we couple the Hamilton-Jacobi (HJ) residual in the OT formulation with the original flow matching loss function. Our approach avoids inner optimization subproblems that are present in previous one-step OFM approaches. During the prediction stage, our approach supports both one-step (Brenier-map) and multi-step ODE sampling from the same learned potential, leveraging the straightness of the OT flow. We validate scalability and performance on standard OT benchmarks.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

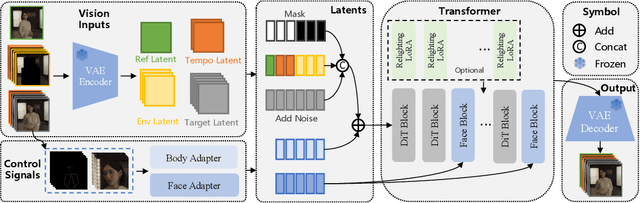
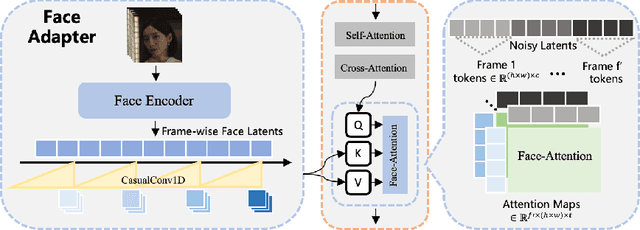
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
PODNO: Proper Orthogonal Decomposition Neural Operators
Apr 25, 2025In this paper, we introduce Proper Orthogonal Decomposition Neural Operators (PODNO) for solving partial differential equations (PDEs) dominated by high-frequency components. Building on the structure of Fourier Neural Operators (FNO), PODNO replaces the Fourier transform with (inverse) orthonormal transforms derived from the Proper Orthogonal Decomposition (POD) method to construct the integral kernel. Due to the optimality of POD basis, the PODNO has potential to outperform FNO in both accuracy and computational efficiency for high-frequency problems. From analysis point of view, we established the universality of a generalization of PODNO, termed as Generalized Spectral Operator (GSO). In addition, we evaluate PODNO's performance numerically on dispersive equations such as the Nonlinear Schrodinger (NLS) equation and the Kadomtsev-Petviashvili (KP) equation.
OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication
Apr 03, 2025Recent years have witnessed remarkable advances in talking head generation, owing to its potential to revolutionize the human-AI interaction from text interfaces into realistic video chats. However, research on text-driven talking heads remains underexplored, with existing methods predominantly adopting a cascaded pipeline that combines TTS systems with audio-driven talking head models. This conventional pipeline not only introduces system complexity and latency overhead but also fundamentally suffers from asynchronous audiovisual output and stylistic discrepancies between generated speech and visual expressions. To address these limitations, we introduce OmniTalker, an end-to-end unified framework that simultaneously generates synchronized speech and talking head videos from text and reference video in real-time zero-shot scenarios, while preserving both speech style and facial styles. The framework employs a dual-branch diffusion transformer architecture: the audio branch synthesizes mel-spectrograms from text, while the visual branch predicts fine-grained head poses and facial dynamics. To bridge modalities, we introduce a novel audio-visual fusion module that integrates cross-modal information to ensure temporal synchronization and stylistic coherence between audio and visual outputs. Furthermore, our in-context reference learning module effectively captures both speech and facial style characteristics from a single reference video without introducing an extra style extracting module. To the best of our knowledge, OmniTalker presents the first unified framework that jointly models speech style and facial style in a zero-shot setting, achieving real-time inference speed of 25 FPS. Extensive experiments demonstrate that our method surpasses existing approaches in generation quality, particularly excelling in style preservation and audio-video synchronization.
Wasserstein Bounds for generative diffusion models with Gaussian tail targets
Dec 15, 2024We present an estimate of the Wasserstein distance between the data distribution and the generation of score-based generative models, assuming an $\epsilon$-accurate approximation of the score and a Gaussian-type tail behavior of the data distribution. The complexity bound in dimension is $O(\sqrt{d})$, with a logarithmic constant. Such Gaussian tail assumption applies to the distribution of a compact support target with early stopping technique and the Bayesian posterior with a bounded observation operator. Corresponding convergence and complexity bounds are derived. The crux of the analysis lies in the Lipchitz bound of the score, which is related to the Hessian estimate of a viscous Hamilton-Jacobi equation (vHJ). This latter is demonstrated by employing a dimension independent kernel estimate. Consequently, our complexity bound scales linearly (up to a logarithmic constant) with the square root of the trace of the covariance operator, which relates to the invariant distribution of forward process. Our analysis also extends to the probabilistic flow ODE, as the sampling process.
Global Well-posedness and Convergence Analysis of Score-based Generative Models via Sharp Lipschitz Estimates
May 25, 2024We establish global well-posedness and convergence of the score-based generative models (SGM) under minimal general assumptions of initial data for score estimation. For the smooth case, we start from a Lipschitz bound of the score function with optimal time length. The optimality is validated by an example whose Lipschitz constant of scores is bounded at initial but blows up in finite time. This necessitates the separation of time scales in conventional bounds for non-log-concave distributions. In contrast, our follow up analysis only relies on a local Lipschitz condition and is valid globally in time. This leads to the convergence of numerical scheme without time separation. For the non-smooth case, we show that the optimal Lipschitz bound is O(1/t) in the point-wise sense for distributions supported on a compact, smooth and low-dimensional manifold with boundary.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
Understanding the diffusion models by conditional expectations
Jan 20, 2023This paper provide several mathematical analyses of the diffusion model in machine learning. The drift term of the backwards sampling process is represented as a conditional expectation involving the data distribution and the forward diffusion. The training process aims to find such a drift function by minimizing the mean-squared residue related to the conditional expectation. Using small-time approximations of the Green's function of the forward diffusion, we show that the analytical mean drift function in DDPM and the score function in SGM asymptotically blow up in the final stages of the sampling process for singular data distributions such as those concentrated on lower-dimensional manifolds, and is therefore difficult to approximate by a network. To overcome this difficulty, we derive a new target function and associated loss, which remains bounded even for singular data distributions. We illustrate the theoretical findings with several numerical examples.
A variational neural network approach for glacier modelling with nonlinear rheology
Sep 05, 2022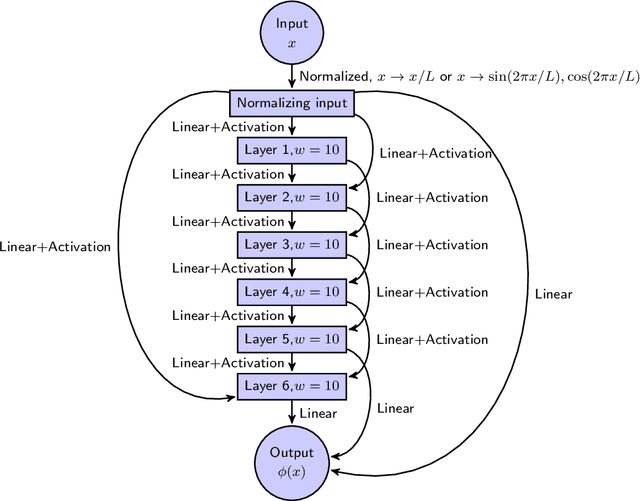
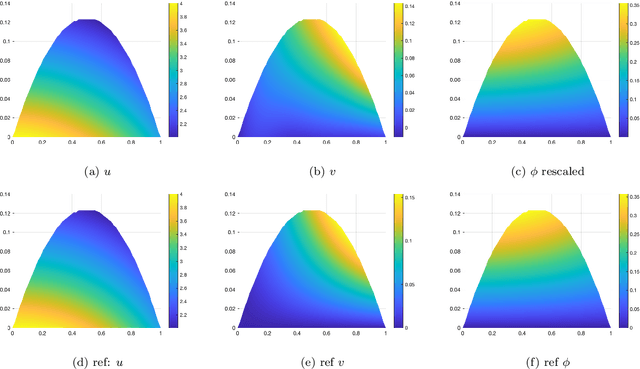
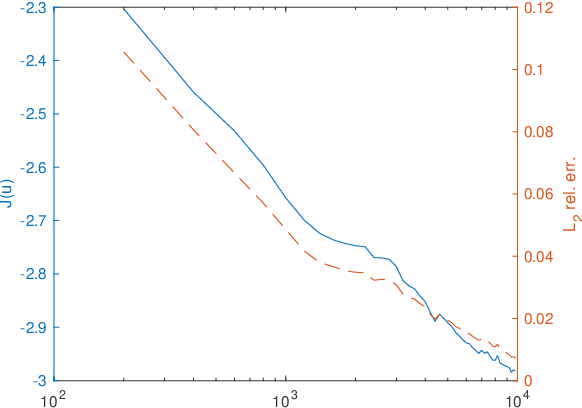
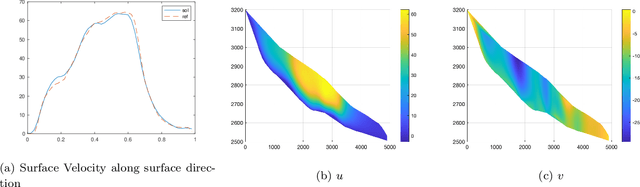
In this paper, we propose a mesh-free method to solve full stokes equation which models the glacier movement with nonlinear rheology. Our approach is inspired by the Deep-Ritz method proposed in [12]. We first formulate the solution of non-Newtonian ice flow model into the minimizer of a variational integral with boundary constraints. The solution is then approximated by a deep neural network whose loss function is the variational integral plus soft constraint from the mixed boundary conditions. Instead of introducing mesh grids or basis functions to evaluate the loss function, our method only requires uniform samplers of the domain and boundaries. To address instability in real-world scaling, we re-normalize the input of the network at the first layer and balance the regularizing factors for each individual boundary. Finally, we illustrate the performance of our method by several numerical experiments, including a 2D model with analytical solution, Arolla glacier model with real scaling and a 3D model with periodic boundary conditions. Numerical results show that our proposed method is efficient in solving the non-Newtonian mechanics arising from glacier modeling with nonlinear rheology.