 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI Grading on Real-World Handwritten College Mathematics: A Large-Scale Study Toward a Benchmark
Mar 01, 2026Grading in large undergraduate STEM courses often yields minimal feedback due to heavy instructional workloads. We present a large-scale empirical study of AI grading on real, handwritten single-variable calculus work from UC Irvine. Using OCR-conditioned large language models with structured, rubric-guided prompting, our system produces scores and formative feedback for thousands of free-response quiz submissions from nearly 800 students. In a setting with no single ground-truth label, we evaluate performance against official teaching-assistant grades, student surveys, and independent human review, finding strong alignment with TA scoring and a large majority of AI-generated feedback rated as correct or acceptable across quizzes. Beyond calculus, this setting highlights core challenges in OCR-conditioned mathematical reasoning and partial-credit assessment. We analyze key failure modes, propose practical rubric- and prompt-design principles, and introduce a multi-perspective evaluation protocol for reliable, real-course deployment. Building on the dataset and evaluation framework developed here, we outline a standardized benchmark for AI grading of handwritten mathematics to support reproducible comparison and future research.
Diffusion Models with Heavy-Tailed Targets: Score Estimation and Sampling Guarantees
Jan 10, 2026Score-based diffusion models have become a powerful framework for generative modeling, with score estimation as a central statistical bottleneck. Existing guarantees for score estimation largely focus on light-tailed targets or rely on restrictive assumptions such as compact support, which are often violated by heavy-tailed data in practice. In this work, we study conventional (Gaussian) score-based diffusion models when the target distribution is heavy-tailed and belongs to a Sobolev class with smoothness parameter $β>0$. We consider both exponential and polynomial tail decay, indexed by a tail parameter $γ$. Using kernel density estimation, we derive sharp minimax rates for score estimation, revealing a qualitative dichotomy: under exponential tails, the rate matches the light-tailed case up to polylogarithmic factors, whereas under polynomial tails the rate depends explicitly on $γ$. We further provide sampling guarantees for the associated continuous reverse dynamics. In total variation, the generated distribution converges at the minimax optimal rate $n^{-β/(2β+d)}$ under exponential tails (up to logarithmic factors), and at a $γ$-dependent rate under polynomial tails. Whether the latter sampling rate is minimax optimal remains an open question. These results characterize the statistical limits of score estimation and the resulting sampling accuracy for heavy-tailed targets, extending diffusion theory beyond the light-tailed setting.
SingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025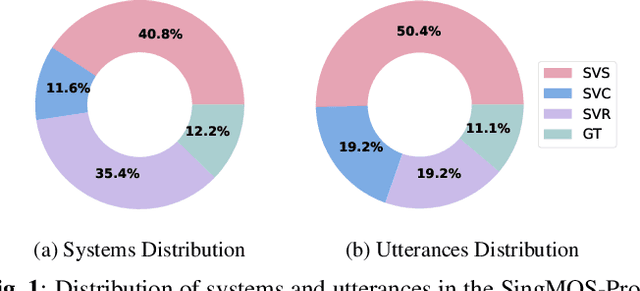

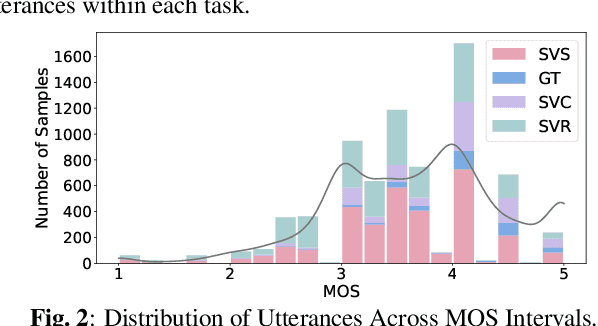

Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
RLHGNN: Reinforcement Learning-driven Heterogeneous Graph Neural Network for Next Activity Prediction in Business Processes
Jul 03, 2025Next activity prediction represents a fundamental challenge for optimizing business processes in service-oriented architectures such as microservices environments, distributed enterprise systems, and cloud-native platforms, which enables proactive resource allocation and dynamic service composition. Despite the prevalence of sequence-based methods, these approaches fail to capture non-sequential relationships that arise from parallel executions and conditional dependencies. Even though graph-based approaches address structural preservation, they suffer from homogeneous representations and static structures that apply uniform modeling strategies regardless of individual process complexity characteristics. To address these limitations, we introduce RLHGNN, a novel framework that transforms event logs into heterogeneous process graphs with three distinct edge types grounded in established process mining theory. Our approach creates four flexible graph structures by selectively combining these edges to accommodate different process complexities, and employs reinforcement learning formulated as a Markov Decision Process to automatically determine the optimal graph structure for each specific process instance. RLHGNN then applies heterogeneous graph convolution with relation-specific aggregation strategies to effectively predict the next activity. This adaptive methodology enables precise modeling of both sequential and non-sequential relationships in service interactions. Comprehensive evaluation on six real-world datasets demonstrates that RLHGNN consistently outperforms state-of-the-art approaches. Furthermore, it maintains an inference latency of approximately 1 ms per prediction, representing a highly practical solution suitable for real-time business process monitoring applications. The source code is available at https://github.com/Joker3993/RLHGNN.
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
Apr 23, 2025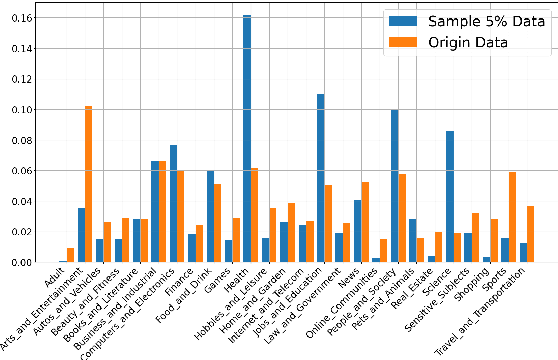
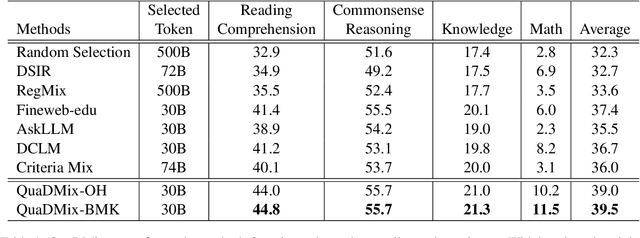
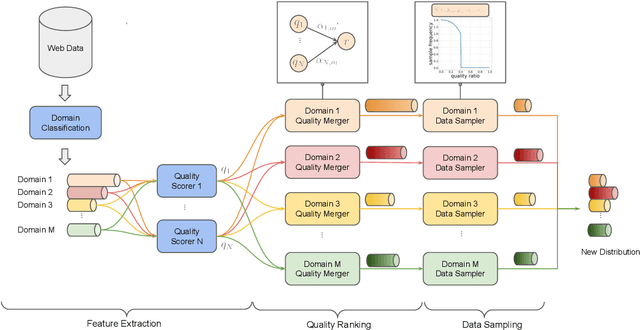

Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
Advancing Wasserstein Convergence Analysis of Score-Based Models: Insights from Discretization and Second-Order Acceleration
Feb 07, 2025
Score-based diffusion models have emerged as powerful tools in generative modeling, yet their theoretical foundations remain underexplored. In this work, we focus on the Wasserstein convergence analysis of score-based diffusion models. Specifically, we investigate the impact of various discretization schemes, including Euler discretization, exponential integrators, and midpoint randomization methods. Our analysis provides a quantitative comparison of these discrete approximations, emphasizing their influence on convergence behavior. Furthermore, we explore scenarios where Hessian information is available and propose an accelerated sampler based on the local linearization method. We demonstrate that this Hessian-based approach achieves faster convergence rates of order $\widetilde{\mathcal{O}}\left(\frac{1}{\varepsilon}\right)$ significantly improving upon the standard rate $\widetilde{\mathcal{O}}\left(\frac{1}{\varepsilon^2}\right)$ of vanilla diffusion models, where $\varepsilon$ denotes the target accuracy.
Muskits-ESPnet: A Comprehensive Toolkit for Singing Voice Synthesis in New Paradigm
Sep 11, 2024

This research presents Muskits-ESPnet, a versatile toolkit that introduces new paradigms to Singing Voice Synthesis (SVS) through the application of pretrained audio models in both continuous and discrete approaches. Specifically, we explore discrete representations derived from SSL models and audio codecs and offer significant advantages in versatility and intelligence, supporting multi-format inputs and adaptable data processing workflows for various SVS models. The toolkit features automatic music score error detection and correction, as well as a perception auto-evaluation module to imitate human subjective evaluating scores. Muskits-ESPnet is available at \url{https://github.com/espnet/espnet}.
An Adaptive Tensor-Train Decomposition Approach for Efficient Deep Neural Network Compression
Aug 02, 2024



In the field of model compression, choosing an appropriate rank for tensor decomposition is pivotal for balancing model compression rate and efficiency. However, this selection, whether done manually or through optimization-based automatic methods, often increases computational complexity. Manual rank selection lacks efficiency and scalability, often requiring extensive trial-and-error, while optimization-based automatic methods significantly increase the computational burden. To address this, we introduce a novel, automatic, and budget-aware rank selection method for efficient model compression, which employs Layer-Wise Imprinting Quantitation (LWIQ). LWIQ quantifies each layer's significance within a neural network by integrating a proxy classifier. This classifier assesses the layer's impact on overall model performance, allowing for a more informed adjustment of tensor rank. Furthermore, our approach includes a scaling factor to cater to varying computational budget constraints. This budget awareness eliminates the need for repetitive rank recalculations for different budget scenarios. Experimental results on the CIFAR-10 dataset show that our LWIQ improved by 63.2$\%$ in rank search efficiency, and the accuracy only dropped by 0.86$\%$ with 3.2x less model size on the ResNet-56 model as compared to the state-of-the-art proxy-based automatic tensor rank selection method.
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Jun 13, 2024


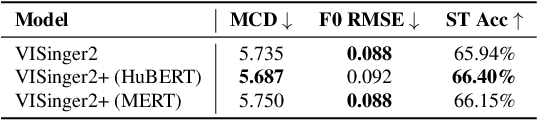
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Global Well-posedness and Convergence Analysis of Score-based Generative Models via Sharp Lipschitz Estimates
May 25, 2024We establish global well-posedness and convergence of the score-based generative models (SGM) under minimal general assumptions of initial data for score estimation. For the smooth case, we start from a Lipschitz bound of the score function with optimal time length. The optimality is validated by an example whose Lipschitz constant of scores is bounded at initial but blows up in finite time. This necessitates the separation of time scales in conventional bounds for non-log-concave distributions. In contrast, our follow up analysis only relies on a local Lipschitz condition and is valid globally in time. This leads to the convergence of numerical scheme without time separation. For the non-smooth case, we show that the optimal Lipschitz bound is O(1/t) in the point-wise sense for distributions supported on a compact, smooth and low-dimensional manifold with boundary.