 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen No Answer Is Correct: Diagnosing Absent Answer Detection for MLLMs in Video Understanding
Jun 06, 2026Multimodal large language models (MLLMs) have made substantial advancements in video understanding, yet the reliability of their responses remains underexplored. This work presents a diagnostic study of absent answer detection for MLLMs in video understanding, where the correct answer is deliberately excluded from the candidate set and a reliable model is expected to recognize that no valid option exists. We evaluate the absent answer detection behavior under three settings: multiple-choice questions augmented with an ``None of the Above'' option, open-ended generation with a detection instruction, and standard evaluation without any guidance. Across a diverse set of models and benchmarks, we find that MLLMs overwhelmingly select plausible distractors rather than detecting the absent answer. This failure is more pronounced in temporal reasoning tasks and worsens with denser frame sampling. We further explore chain-of-thought prompting as a mitigation strategy and find that while it substantially improves detection rates, performance remains unsatisfactory, suggesting that prompting-based strategies alone are insufficient to fully address this limitation. These findings expose a systematic failure in absent answer detection and highlight the need for explicit detection mechanisms in multimodal systems.
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
FlashFPS: Efficient Farthest Point Sampling for Large-Scale Point Clouds via Pruning and Caching
Apr 20, 2026Point-based Neural Networks (PNNs) have become a key approach for point cloud processing. However, a core operation in these models, Farthest Point Sampling (FPS), often introduces significant inference latency, especially for large-scale processing. Despite existing CUDA- and hardware-level optimizations, FPS remains a major bottleneck due to exhaustive computations across multiple network layers in PNNs, which hinders scalability. Through systematic analysis, we identify three substantial redundancies in FPS, including unnecessary full-cloud computations, redundant late-stage iterations, and predictable inter-layer outputs that make later FPS computations avoidable. To address these, we propose \textbf{\textit{FlashFPS}}, a hardware-agnostic, plug-and-play framework for FPS acceleration, composed of \textit{FPS-Prune} and \textit{FPS-Cache}. \textit{FPS-Prune} introduces candidate pruning and iteration pruning to reduce redundant computations in FPS while preserving sampling quality, and \textit{FPS-Cache} eliminates layer-wise redundancy via cache-and-reuse. Integrated into existing CUDA libraries and state-of-the-art PNN accelerators, \textit{FlashFPS} achieves 5.16$\times$ speedup over the standard CUDA baseline on GPU and 2.69$\times$ on PNN accelerators, with negligible accuracy loss, enabling efficient and scalable PNN inference. Codes are released at https://github.com/Yuzhe-Fu/FlashFPS.
Query-Conditioned Evidential Keyframe Sampling for MLLM-Based Long-Form Video Understanding
Apr 01, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on video question answering, but their application to long-form videos is constrained by limited context length and computational cost, making keyframe sampling essential. Existing approaches typically rely on semantic relevance or reinforcement learning, which either fail to capture evidential clues or suffer from inefficient combinatorial optimization. In this work, we propose an evidence-driven keyframe sampling framework grounded in information bottleneck theory. We formulate keyframe selection as maximizing the conditional mutual information between selected frames and the query, providing a principled objective that reflects each frame's contribution to answering the question. To make this objective tractable, we exploit its structure to derive a decomposed optimization that reduces subset selection to independent frame-level scoring. We further introduce a query-conditioned evidence scoring network trained with a contrastive objective to estimate evidential importance efficiently. Experiments on long-form video understanding benchmarks show that our method consistently outperforms prior sampling strategies under strict token budgets, while significantly improving training efficiency.
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
MUSE: A Run-Centric Platform for Multimodal Unified Safety Evaluation of Large Language Models
Mar 03, 2026Safety evaluation and red-teaming of large language models remain predominantly text-centric, and existing frameworks lack the infrastructure to systematically test whether alignment generalizes to audio, image, and video inputs. We present MUSE (Multimodal Unified Safety Evaluation), an open-source, run-centric platform that integrates automatic cross-modal payload generation, three multi-turn attack algorithms (Crescendo, PAIR, Violent Durian), provider-agnostic model routing, and an LLM judge with a five-level safety taxonomy into a single browser-based system. A dual-metric framework distinguishes hard Attack Success Rate (Compliance only) from soft ASR (including Partial Compliance), capturing partial information leakage that binary metrics miss. To probe whether alignment generalizes across modality boundaries, we introduce Inter-Turn Modality Switching (ITMS), which augments multi-turn attacks with per-turn modality rotation. Experiments across six multimodal LLMs from four providers show that multi-turn strategies can achieve up to 90-100% ASR against models with near-perfect single-turn refusal. ITMS does not uniformly raise final ASR on already-saturated baselines, but accelerates convergence by destabilizing early-turn defenses, and ablation reveals that the direction of modality effects is model-family-specific rather than universal, underscoring the need for provider-aware cross-modal safety testing.
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
Bridging the Perception Gap: A Lightweight Coarse-to-Fine Architecture for Edge Audio Systems
Jan 22, 2026Deploying Audio-Language Models (Audio-LLMs) on edge infrastructure exposes a persistent tension between perception depth and computational efficiency. Lightweight local models tend to produce passive perception - generic summaries that miss the subtle evidence required for multi-step audio reasoning - while indiscriminate cloud offloading incurs unacceptable latency, bandwidth cost, and privacy risk. We propose CoFi-Agent (Tool-Augmented Coarse-to-Fine Agent), a hybrid architecture targeting edge servers and gateways. It performs fast local perception and triggers conditional forensic refinement only when uncertainty is detected. CoFi-Agent runs an initial single-pass on a local 7B Audio-LLM, then a cloud controller gates difficult cases and issues lightweight plans for on-device tools such as temporal re-listening and local ASR. On the MMAR benchmark, CoFi-Agent improves accuracy from 27.20% to 53.60%, while achieving a better accuracy-efficiency trade-off than an always-on investigation pipeline. Overall, CoFi-Agent bridges the perception gap via tool-enabled, conditional edge-cloud collaboration under practical system constraints.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025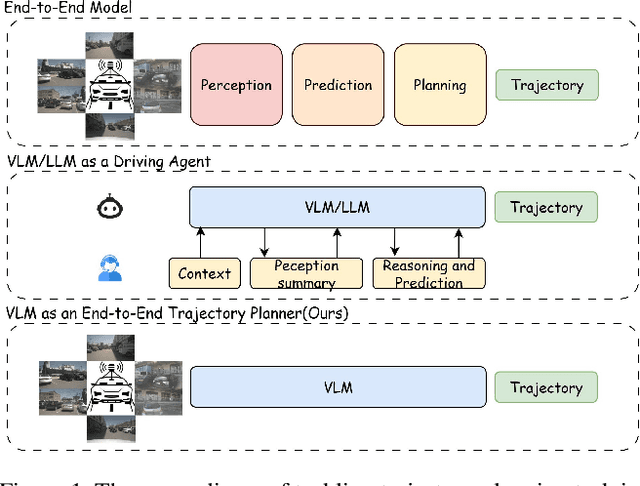
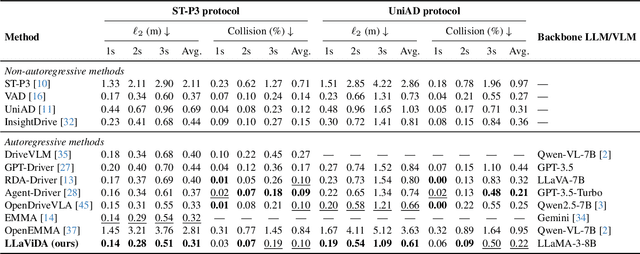
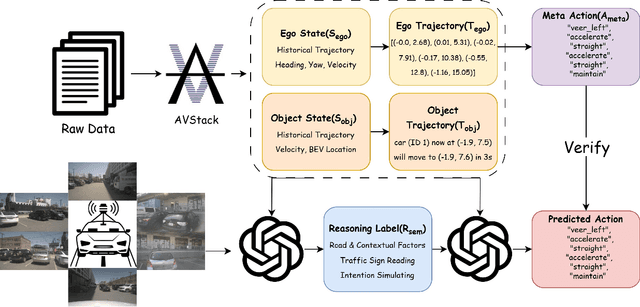
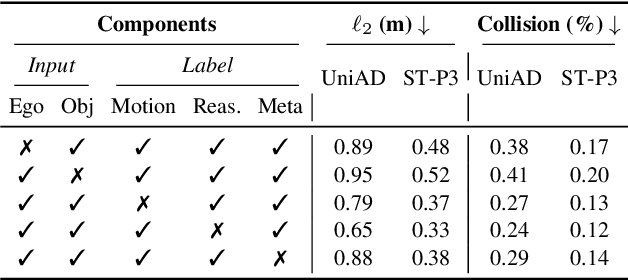
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.