 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoOdyssey: A Benchmark for Ultra-Long-Context and Omni-Modal Video Understanding
May 21, 2026Real-world long video understanding requires models to perform continuous tracking, information integration and memory retention over massive temporal spans within extreme video durations. Mastering this intense cognitive load constitutes the fundamental bottleneck in long video understanding. While existing benchmarks have driven progress by scaling up video duration, their evaluation tasks often require comprehending only short and isolated video segments, falling short of capturing the challenge of ultra-long-context reasoning. To measure this cognitive load, we emphasize continuous certificate length, defined as the video length a human must continuously watch to definitively answer a given question. Driven by this metric, we introduce VideoOdyssey, a benchmark specifically designed for ultra-long-context and omni-modal video understanding. VideoOdyssey is characterized by three key features: 1) Extreme video duration and diversity: spanning 11 domains and 54 subcategories with an average video duration of 109 minutes; 2) Comprehensive evaluation scenarios: offering two subsets to address different research focuses, i.e., VideoOdyssey-V for probing the limits of visual understanding in MLLMs, and VideoOdyssey-AV for evaluating synchronized audio-visual understanding for omni-modal models; 3) Ultra-long and multi-level continuous certificates: extending the average continuous certificate to 16 minutes for VideoOdyssey-V and 12.8 minutes for VideoOdyssey-AV. Crucially, we design 5 granular levels from seconds to hours, providing a comprehensive diagnostic tool to evaluate models across varying context lengths and cognitive loads. Extensive evaluations show that bottlenecks of current MLLMs extend beyond simple retrieval to include struggles with continuous reasoning across varying context lengths, fine-grained perception, and non-verbal omni-modal understanding.
Streaming Video Instruction Tuning
Dec 24, 2025



We present Streamo, a real-time streaming video LLM that serves as a general-purpose interactive assistant. Unlike existing online video models that focus narrowly on question answering or captioning, Streamo performs a broad spectrum of streaming video tasks, including real-time narration, action understanding, event captioning, temporal event grounding, and time-sensitive question answering. To develop such versatility, we construct Streamo-Instruct-465K, a large-scale instruction-following dataset tailored for streaming video understanding. The dataset covers diverse temporal contexts and multi-task supervision, enabling unified training across heterogeneous streaming tasks. After training end-to-end on the instruction-following dataset through a streamlined pipeline, Streamo exhibits strong temporal reasoning, responsive interaction, and broad generalization across a variety of streaming benchmarks. Extensive experiments show that Streamo bridges the gap between offline video perception models and real-time multimodal assistants, making a step toward unified, intelligent video understanding in continuous video streams.
Measuring Epistemic Humility in Multimodal Large Language Models
Sep 11, 2025Hallucinations in multimodal large language models (MLLMs) -- where the model generates content inconsistent with the input image -- pose significant risks in real-world applications, from misinformation in visual question answering to unsafe errors in decision-making. Existing benchmarks primarily test recognition accuracy, i.e., evaluating whether models can select the correct answer among distractors. This overlooks an equally critical capability for trustworthy AI: recognizing when none of the provided options are correct, a behavior reflecting epistemic humility. We present HumbleBench, a new hallucination benchmark designed to evaluate MLLMs' ability to reject plausible but incorrect answers across three hallucination types: object, relation, and attribute. Built from a panoptic scene graph dataset, we leverage fine-grained scene graph annotations to extract ground-truth entities and relations, and prompt GPT-4-Turbo to generate multiple-choice questions, followed by a rigorous manual filtering process. Each question includes a "None of the above" option, requiring models not only to recognize correct visual information but also to identify when no provided answer is valid. We evaluate a variety of state-of-the-art MLLMs -- including both general-purpose and specialized reasoning models -- on HumbleBench and share valuable findings and insights with the community. By incorporating explicit false-option rejection, HumbleBench fills a key gap in current evaluation suites, providing a more realistic measure of MLLM reliability in safety-critical settings. Our code and dataset are released publicly and can be accessed at https://github.com/maifoundations/HumbleBench.
Bootstrapping Grounded Chain-of-Thought in Multimodal LLMs for Data-Efficient Model Adaptation
Jul 03, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in interpreting images using natural language. However, without using large-scale datasets for retraining, these models are difficult to adapt to specialized vision tasks, e.g., chart understanding. This problem is caused by a mismatch between pre-training and downstream datasets: pre-training datasets primarily concentrate on scenes and objects but contain limited information about specialized, non-object images, such as charts and tables. In this paper, we share an interesting finding that training an MLLM with Chain-of-Thought (CoT) reasoning data can facilitate model adaptation in specialized vision tasks, especially under data-limited regimes. However, we identify a critical issue within CoT data distilled from pre-trained MLLMs, i.e., the data often contains multiple factual errors in the reasoning steps. To address the problem, we propose Grounded Chain-of-Thought (GCoT), a simple bootstrapping-based approach that aims to inject grounding information (i.e., bounding boxes) into CoT data, essentially making the reasoning steps more faithful to input images. We evaluate our approach on five specialized vision tasks, which cover a variety of visual formats including charts, tables, receipts, and reports. The results demonstrate that under data-limited regimes our approach significantly improves upon fine-tuning and distillation.
Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning
May 20, 2025Learning general-purpose reasoning capabilities has long been a challenging problem in AI. Recent research in large language models (LLMs), such as DeepSeek-R1, has shown that reinforcement learning techniques like GRPO can enable pre-trained LLMs to develop reasoning capabilities using simple question-answer pairs. In this paper, we aim to train visual language models (VLMs) to perform reasoning on image data through reinforcement learning and visual question-answer pairs, without any explicit chain-of-thought (CoT) supervision. Our findings indicate that simply applying reinforcement learning to a VLM -- by prompting the model to produce a reasoning chain before providing an answer -- can lead the model to develop shortcuts from easy questions, thereby reducing its ability to generalize across unseen data distributions. We argue that the key to mitigating shortcut learning is to encourage the model to interpret images prior to reasoning. Therefore, we train the model to adhere to a caption-reason-answer output format: initially generating a detailed caption for an image, followed by constructing an extensive reasoning chain. When trained on 273K CoT-free visual question-answer pairs and using only reinforcement learning, our model, named Visionary-R1, outperforms strong multimodal models, such as GPT-4o, Claude3.5-Sonnet, and Gemini-1.5-Pro, on multiple visual reasoning benchmarks.
Training-Free Watermarking for Autoregressive Image Generation
May 20, 2025



Invisible image watermarking can protect image ownership and prevent malicious misuse of visual generative models. However, existing generative watermarking methods are mainly designed for diffusion models while watermarking for autoregressive image generation models remains largely underexplored. We propose IndexMark, a training-free watermarking framework for autoregressive image generation models. IndexMark is inspired by the redundancy property of the codebook: replacing autoregressively generated indices with similar indices produces negligible visual differences. The core component in IndexMark is a simple yet effective match-then-replace method, which carefully selects watermark tokens from the codebook based on token similarity, and promotes the use of watermark tokens through token replacement, thereby embedding the watermark without affecting the image quality. Watermark verification is achieved by calculating the proportion of watermark tokens in generated images, with precision further improved by an Index Encoder. Furthermore, we introduce an auxiliary validation scheme to enhance robustness against cropping attacks. Experiments demonstrate that IndexMark achieves state-of-the-art performance in terms of image quality and verification accuracy, and exhibits robustness against various perturbations, including cropping, noises, Gaussian blur, random erasing, color jittering, and JPEG compression.
Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
May 19, 2025As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting these models to downstream tasks. In this paper, we aim to push the limits of memory-efficient training by minimizing memory usage on model weights, gradients, and optimizer states, within a unified framework. Our idea is to eliminate both gradients and optimizer states using zeroth-order optimization, which approximates gradients by perturbing weights during forward passes to identify gradient directions. To minimize memory usage on weights, we employ model quantization, e.g., converting from bfloat16 to int4. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients, which would otherwise require de-quantization and re-quantization. To overcome this challenge, we propose Quantized Zeroth-order Optimization (QZO), a novel approach that perturbs the continuous quantization scale for gradient estimation and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to both scalar-based and codebook-based post-training quantization methods. Compared to full-parameter fine-tuning in bfloat16, QZO can reduce the total memory cost by more than 18$\times$ for 4-bit LLMs, and enables fine-tuning Llama-2-13B and Stable Diffusion 3.5 Large within a single 24GB GPU.
Advances in Multimodal Adaptation and Generalization: From Traditional Approaches to Foundation Models
Jan 30, 2025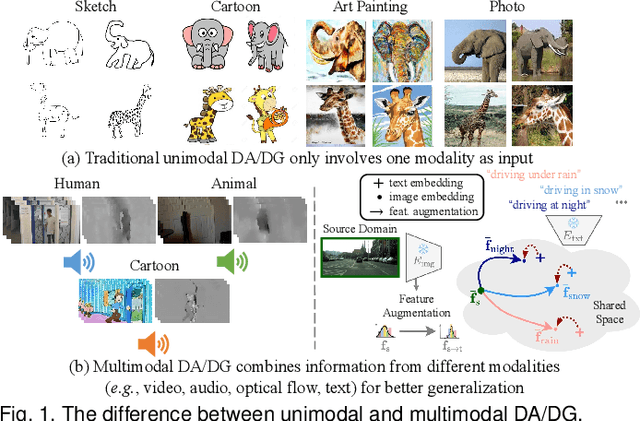
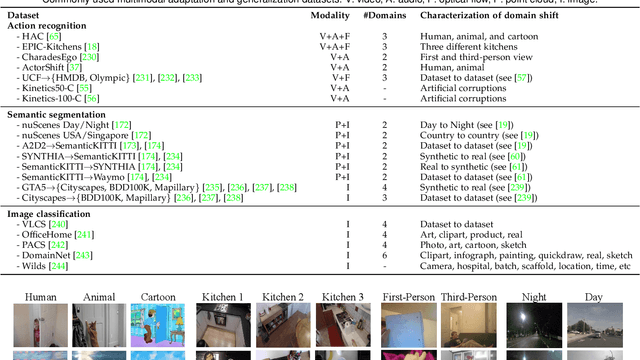
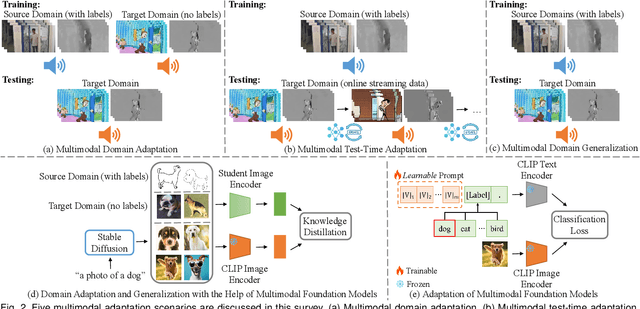
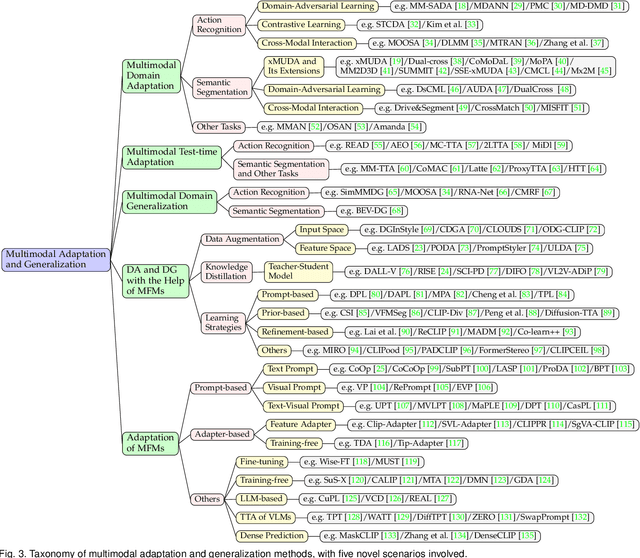
In real-world scenarios, achieving domain adaptation and generalization poses significant challenges, as models must adapt to or generalize across unknown target distributions. Extending these capabilities to unseen multimodal distributions, i.e., multimodal domain adaptation and generalization, is even more challenging due to the distinct characteristics of different modalities. Significant progress has been made over the years, with applications ranging from action recognition to semantic segmentation. Besides, the recent advent of large-scale pre-trained multimodal foundation models, such as CLIP, has inspired works leveraging these models to enhance adaptation and generalization performances or adapting them to downstream tasks. This survey provides the first comprehensive review of recent advances from traditional approaches to foundation models, covering: (1) Multimodal domain adaptation; (2) Multimodal test-time adaptation; (3) Multimodal domain generalization; (4) Domain adaptation and generalization with the help of multimodal foundation models; and (5) Adaptation of multimodal foundation models. For each topic, we formally define the problem and thoroughly review existing methods. Additionally, we analyze relevant datasets and applications, highlighting open challenges and potential future research directions. We maintain an active repository that contains up-to-date literature at https://github.com/donghao51/Awesome-Multimodal-Adaptation.
4D Panoptic Scene Graph Generation
May 16, 2024


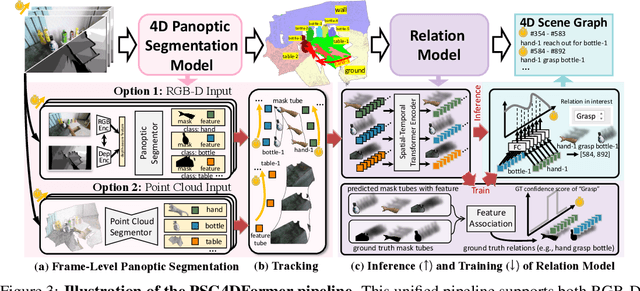
We are living in a three-dimensional space while moving forward through a fourth dimension: time. To allow artificial intelligence to develop a comprehensive understanding of such a 4D environment, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding. Specifically, PSG-4D abstracts rich 4D sensory data into nodes, which represent entities with precise location and status information, and edges, which capture the temporal relations. To facilitate research in this new area, we build a richly annotated PSG-4D dataset consisting of 3K RGB-D videos with a total of 1M frames, each of which is labeled with 4D panoptic segmentation masks as well as fine-grained, dynamic scene graphs. To solve PSG-4D, we propose PSG4DFormer, a Transformer-based model that can predict panoptic segmentation masks, track masks along the time axis, and generate the corresponding scene graphs via a relation component. Extensive experiments on the new dataset show that our method can serve as a strong baseline for future research on PSG-4D. In the end, we provide a real-world application example to demonstrate how we can achieve dynamic scene understanding by integrating a large language model into our PSG-4D system.
Dual Memory Networks: A Versatile Adaptation Approach for Vision-Language Models
Mar 26, 2024With the emergence of pre-trained vision-language models like CLIP, how to adapt them to various downstream classification tasks has garnered significant attention in recent research. The adaptation strategies can be typically categorized into three paradigms: zero-shot adaptation, few-shot adaptation, and the recently-proposed training-free few-shot adaptation. Most existing approaches are tailored for a specific setting and can only cater to one or two of these paradigms. In this paper, we introduce a versatile adaptation approach that can effectively work under all three settings. Specifically, we propose the dual memory networks that comprise dynamic and static memory components. The static memory caches training data knowledge, enabling training-free few-shot adaptation, while the dynamic memory preserves historical test features online during the testing process, allowing for the exploration of additional data insights beyond the training set. This novel capability enhances model performance in the few-shot setting and enables model usability in the absence of training data. The two memory networks employ the same flexible memory interactive strategy, which can operate in a training-free mode and can be further enhanced by incorporating learnable projection layers. Our approach is tested across 11 datasets under the three task settings. Remarkably, in the zero-shot scenario, it outperforms existing methods by over 3\% and even shows superior results against methods utilizing external training data. Additionally, our method exhibits robust performance against natural distribution shifts. Codes are available at \url{https://github.com/YBZh/DMN}.