 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing 3D Scenes in Native High Dynamic Range
Nov 17, 2025High Dynamic Range (HDR) imaging is essential for professional digital media creation, e.g., filmmaking, virtual production, and photorealistic rendering. However, 3D scene reconstruction has primarily focused on Low Dynamic Range (LDR) data, limiting its applicability to professional workflows. Existing approaches that reconstruct HDR scenes from LDR observations rely on multi-exposure fusion or inverse tone-mapping, which increase capture complexity and depend on synthetic supervision. With the recent emergence of cameras that directly capture native HDR data in a single exposure, we present the first method for 3D scene reconstruction that directly models native HDR observations. We propose {\bf Native High dynamic range 3D Gaussian Splatting (NH-3DGS)}, which preserves the full dynamic range throughout the reconstruction pipeline. Our key technical contribution is a novel luminance-chromaticity decomposition of the color representation that enables direct optimization from native HDR camera data. We demonstrate on both synthetic and real multi-view HDR datasets that NH-3DGS significantly outperforms existing methods in reconstruction quality and dynamic range preservation, enabling professional-grade 3D reconstruction directly from native HDR captures. Code and datasets will be made available.
Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
May 19, 2025As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting these models to downstream tasks. In this paper, we aim to push the limits of memory-efficient training by minimizing memory usage on model weights, gradients, and optimizer states, within a unified framework. Our idea is to eliminate both gradients and optimizer states using zeroth-order optimization, which approximates gradients by perturbing weights during forward passes to identify gradient directions. To minimize memory usage on weights, we employ model quantization, e.g., converting from bfloat16 to int4. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients, which would otherwise require de-quantization and re-quantization. To overcome this challenge, we propose Quantized Zeroth-order Optimization (QZO), a novel approach that perturbs the continuous quantization scale for gradient estimation and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to both scalar-based and codebook-based post-training quantization methods. Compared to full-parameter fine-tuning in bfloat16, QZO can reduce the total memory cost by more than 18$\times$ for 4-bit LLMs, and enables fine-tuning Llama-2-13B and Stable Diffusion 3.5 Large within a single 24GB GPU.
High Dynamic Range Novel View Synthesis with Single Exposure
May 02, 2025
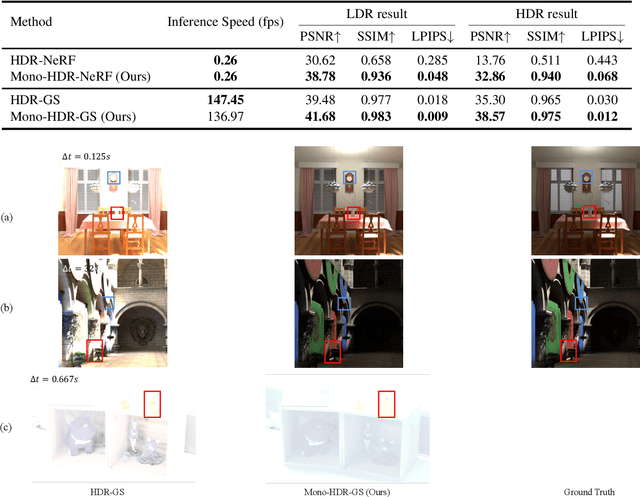
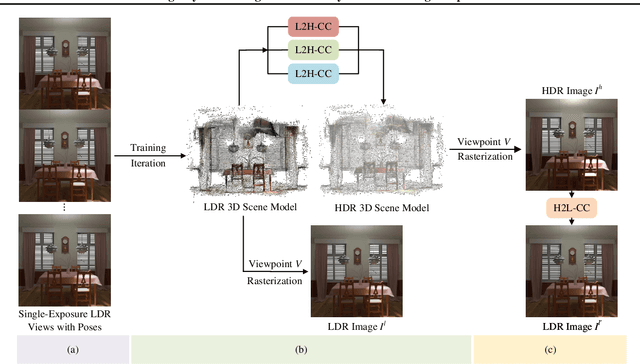
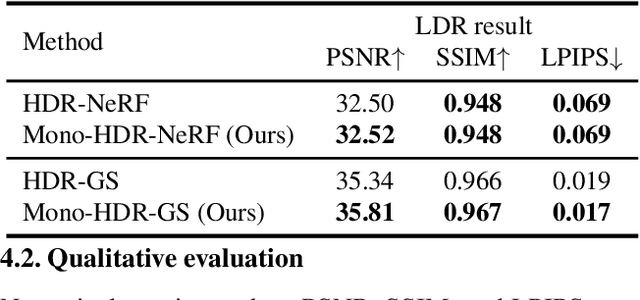
High Dynamic Range Novel View Synthesis (HDR-NVS) aims to establish a 3D scene HDR model from Low Dynamic Range (LDR) imagery. Typically, multiple-exposure LDR images are employed to capture a wider range of brightness levels in a scene, as a single LDR image cannot represent both the brightest and darkest regions simultaneously. While effective, this multiple-exposure HDR-NVS approach has significant limitations, including susceptibility to motion artifacts (e.g., ghosting and blurring), high capture and storage costs. To overcome these challenges, we introduce, for the first time, the single-exposure HDR-NVS problem, where only single exposure LDR images are available during training. We further introduce a novel approach, Mono-HDR-3D, featuring two dedicated modules formulated by the LDR image formation principles, one for converting LDR colors to HDR counterparts, and the other for transforming HDR images to LDR format so that unsupervised learning is enabled in a closed loop. Designed as a meta-algorithm, our approach can be seamlessly integrated with existing NVS models. Extensive experiments show that Mono-HDR-3D significantly outperforms previous methods. Source code will be released.
RobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Oct 01, 2024



Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover's Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
Towards Fewer Labels: Support Pair Active Learning for Person Re-identification
Apr 21, 2022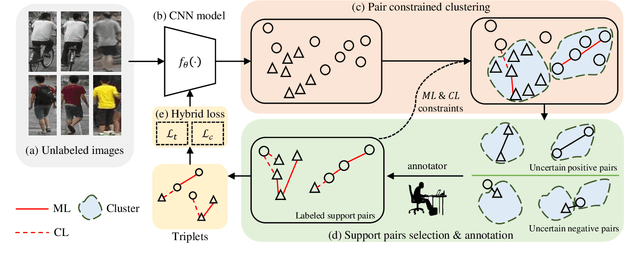
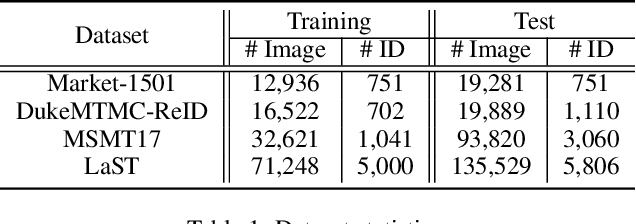
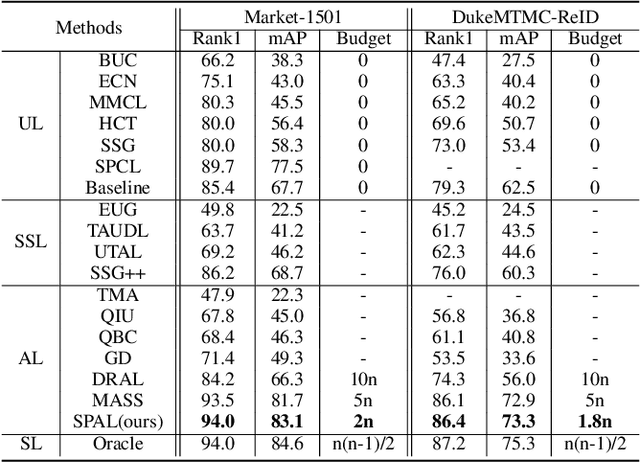
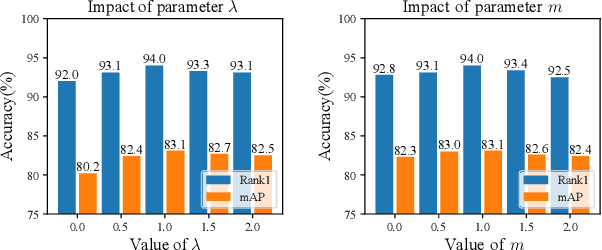
Supervised-learning based person re-identification (re-id) require a large amount of manual labeled data, which is not applicable in practical re-id deployment. In this work, we propose a Support Pair Active Learning (SPAL) framework to lower the manual labeling cost for large-scale person reidentification. The support pairs can provide the most informative relationships and support the discriminative feature learning. Specifically, we firstly design a dual uncertainty selection strategy to iteratively discover support pairs and require human annotations. Afterwards, we introduce a constrained clustering algorithm to propagate the relationships of labeled support pairs to other unlabeled samples. Moreover, a hybrid learning strategy consisting of an unsupervised contrastive loss and a supervised support pair loss is proposed to learn the discriminative re-id feature representation. The proposed overall framework can effectively lower the labeling cost by mining and leveraging the critical support pairs. Extensive experiments demonstrate the superiority of the proposed method over state-of-the-art active learning methods on large-scale person re-id benchmarks.
Unsupervised Clustering Active Learning for Person Re-identification
Dec 26, 2021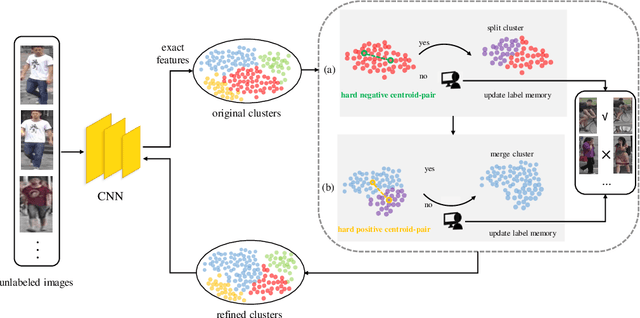
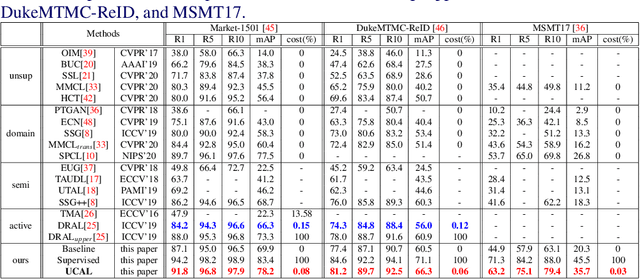
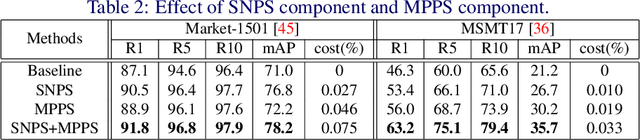
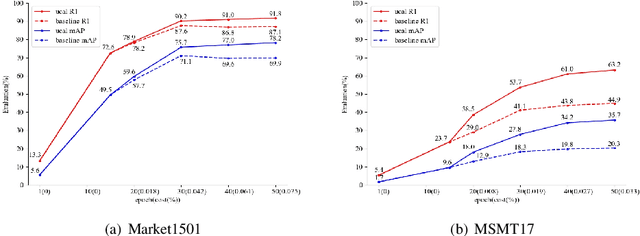
Supervised person re-identification (re-id) approaches require a large amount of pairwise manual labeled data, which is not applicable in most real-world scenarios for re-id deployment. On the other hand, unsupervised re-id methods rely on unlabeled data to train models but performs poorly compared with supervised re-id methods. In this work, we aim to combine unsupervised re-id learning with a small number of human annotations to achieve a competitive performance. Towards this goal, we present a Unsupervised Clustering Active Learning (UCAL) re-id deep learning approach. It is capable of incrementally discovering the representative centroid-pairs and requiring human annotate them. These few labeled representative pairwise data can improve the unsupervised representation learning model with other large amounts of unlabeled data. More importantly, because the representative centroid-pairs are selected for annotation, UCAL can work with very low-cost human effort. Extensive experiments demonstrate the superiority of the proposed model over state-of-the-art active learning methods on three re-id benchmark datasets.
Unsupervised Noisy Tracklet Person Re-identification
Jan 16, 2021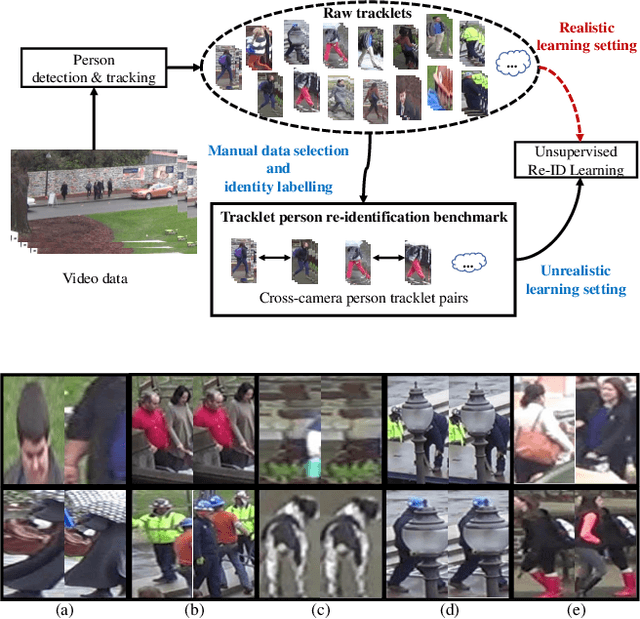

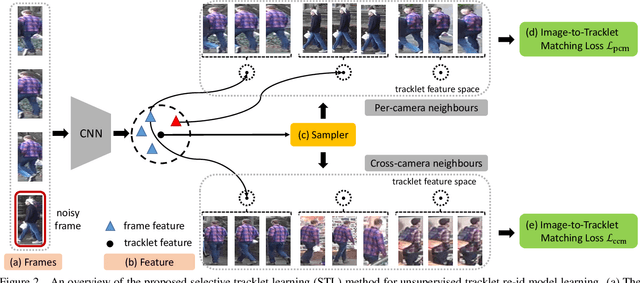
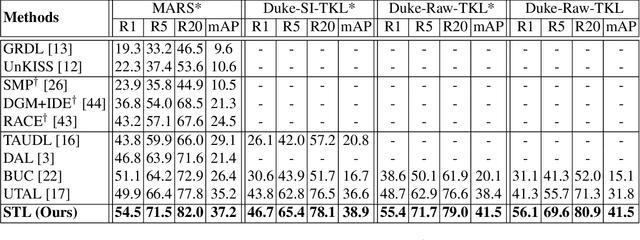
Existing person re-identification (re-id) methods mostly rely on supervised model learning from a large set of person identity labelled training data per domain. This limits their scalability and usability in large scale deployments. In this work, we present a novel selective tracklet learning (STL) approach that can train discriminative person re-id models from unlabelled tracklet data in an unsupervised manner. This avoids the tedious and costly process of exhaustively labelling person image/tracklet true matching pairs across camera views. Importantly, our method is particularly more robust against arbitrary noisy data of raw tracklets therefore scalable to learning discriminative models from unconstrained tracking data. This differs from a handful of existing alternative methods that often assume the existence of true matches and balanced tracklet samples per identity class. This is achieved by formulating a data adaptive image-to-tracklet selective matching loss function explored in a multi-camera multi-task deep learning model structure. Extensive comparative experiments demonstrate that the proposed STL model surpasses significantly the state-of-the-art unsupervised learning and one-shot learning re-id methods on three large tracklet person re-id benchmarks.
Intra-Camera Supervised Person Re-Identification
Feb 12, 2020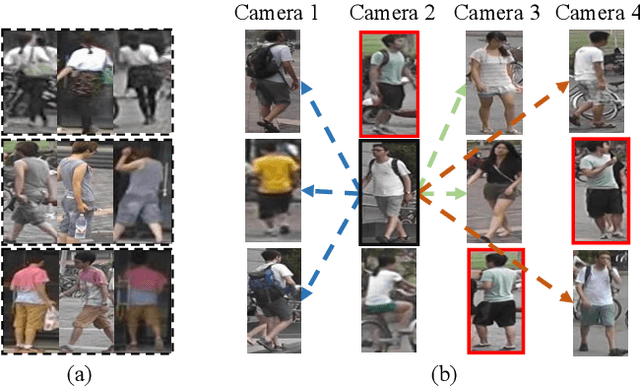
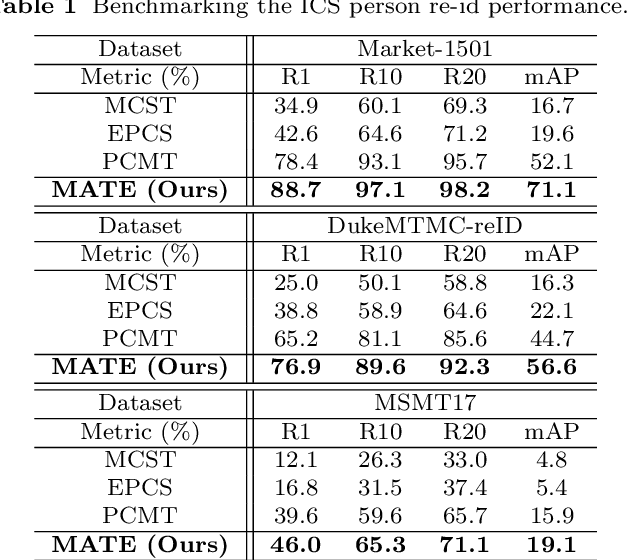
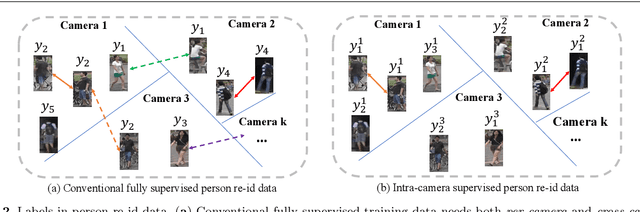
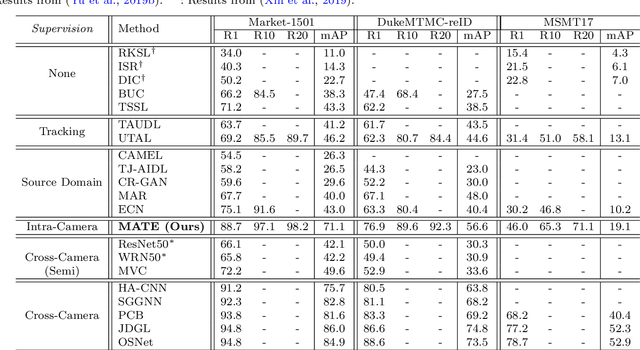
Existing person re-identification (re-id) methods mostly exploit a large set of cross-camera identity labelled training data. This requires a tedious data collection and annotation process, leading to poor scalability in practical re-id applications. On the other hand unsupervised re-id methods do not need identity label information, but they usually suffer from much inferior and insufficient model performance. To overcome these fundamental limitations, we propose a novel person re-identification paradigm based on an idea of independent per-camera identity annotation. This eliminates the most time-consuming and tedious inter-camera identity labelling process, significantly reducing the amount of human annotation efforts. Consequently, it gives rise to a more scalable and more feasible setting, which we call Intra-Camera Supervised (ICS) person re-id, for which we formulate a Multi-tAsk mulTi-labEl (MATE) deep learning method. Specifically, MATE is designed for self-discovering the cross-camera identity correspondence in a per-camera multi-task inference framework. Extensive experiments demonstrate the cost-effectiveness superiority of our method over the alternative approaches on three large person re-id datasets. For example, MATE yields 88.7% rank-1 score on Market-1501 in the proposed ICS person re-id setting, significantly outperforming unsupervised learning models and closely approaching conventional fully supervised learning competitors.
Part-based Multi-stream Model for Vehicle Searching
Nov 11, 2019
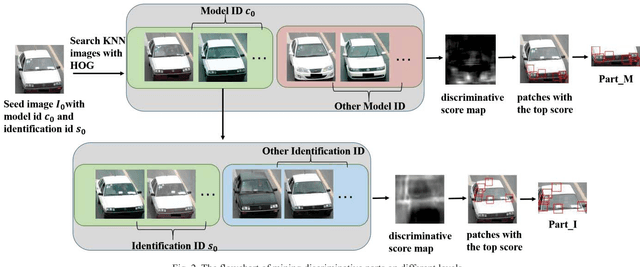
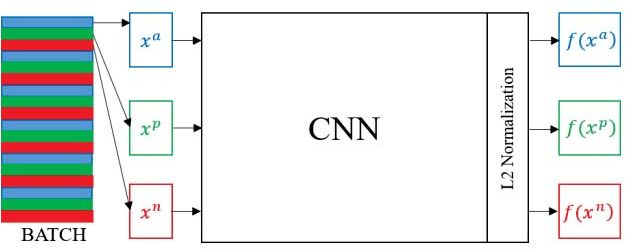
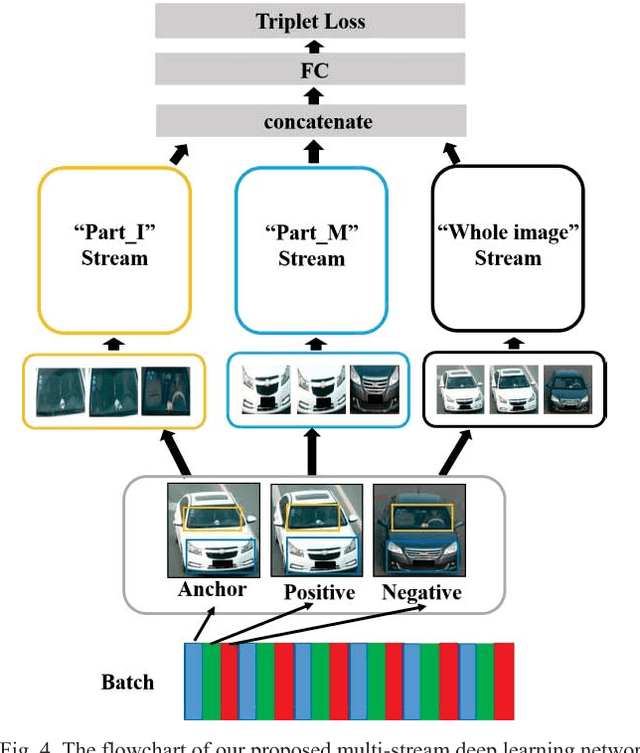
Due to the enormous requirement in public security and intelligent transportation system, searching an identical vehicle has become more and more important. Current studies usually treat vehicle as an integral object and then train a distance metric to measure the similarity among vehicles. However, these raw images may be exactly similar to ones with different identification and include some pixels in background that may disturb the distance metric learning. In this paper, we propose a novel and useful method to segment an original vehicle image into several discriminative foreground parts, and these parts consist of some fine grained regions that are named discriminative patches. After that, these parts combined with the raw image are fed into the proposed deep learning network. We can easily measure the similarity of two vehicle images by computing the Euclidean distance of the features from FC layer. Two main contributions of this paper are as follows. Firstly, a method is proposed to estimate if a patch in a raw vehicle image is discriminative or not. Secondly, a new Part-based Multi-Stream Model (PMSM) is designed and optimized for vehicle retrieval and re-identification tasks. We evaluate the proposed method on the VehicleID dataset, and the experimental results show that our method can outperform the baseline.
Intra-Camera Supervised Person Re-Identification: A New Benchmark
Aug 27, 2019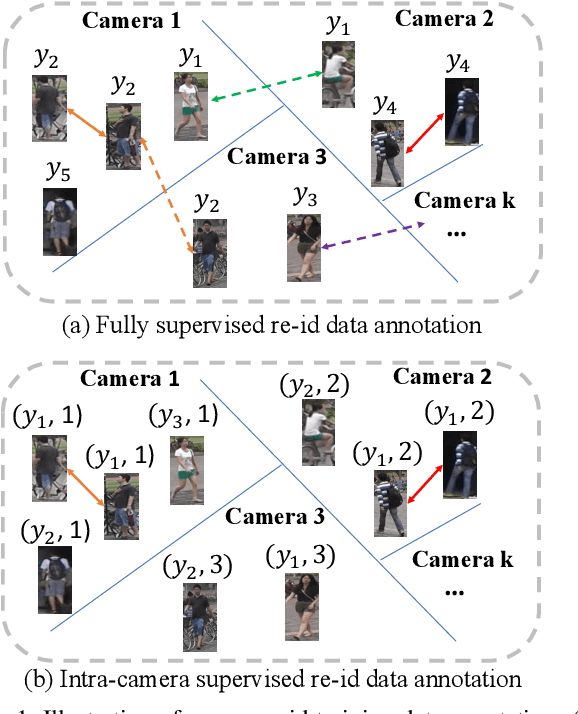
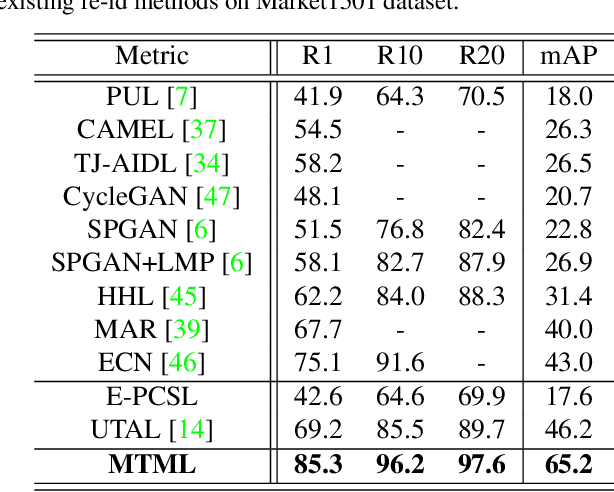
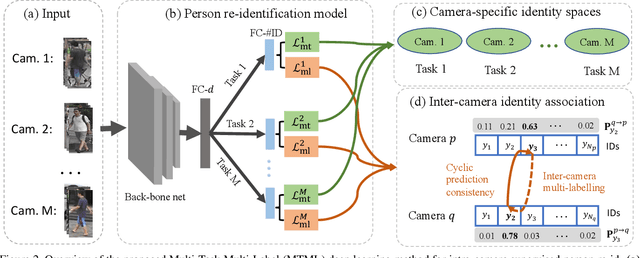
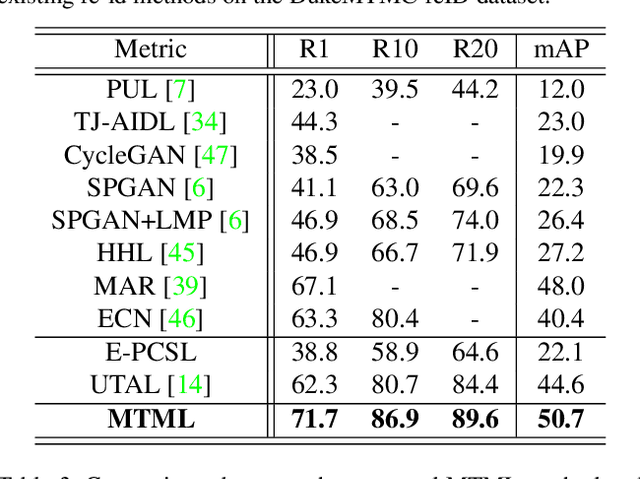
Existing person re-identification (re-id) methods rely mostly on a large set of inter-camera identity labelled training data, requiring a tedious data collection and annotation process therefore leading to poor scalability in practical re-id applications. To overcome this fundamental limitation, we consider person re-identification without inter-camera identity association but only with identity labels independently annotated within each individual camera-view. This eliminates the most time-consuming and tedious inter-camera identity labelling process in order to significantly reduce the amount of human efforts required during annotation. It hence gives rise to a more scalable and more feasible learning scenario, which we call Intra-Camera Supervised (ICS) person re-id. Under this ICS setting with weaker label supervision, we formulate a Multi-Task Multi-Label (MTML) deep learning method. Given no inter-camera association, MTML is specially designed for self-discovering the inter-camera identity correspondence. This is achieved by inter-camera multi-label learning under a joint multi-task inference framework. In addition, MTML can also efficiently learn the discriminative re-id feature representations by fully using the available identity labels within each camera-view. Extensive experiments demonstrate the performance superiority of our MTML model over the state-of-the-art alternative methods on three large-scale person re-id datasets in the proposed intra-camera supervised learning setting.