 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing 3D Scenes in Native High Dynamic Range
Nov 17, 2025High Dynamic Range (HDR) imaging is essential for professional digital media creation, e.g., filmmaking, virtual production, and photorealistic rendering. However, 3D scene reconstruction has primarily focused on Low Dynamic Range (LDR) data, limiting its applicability to professional workflows. Existing approaches that reconstruct HDR scenes from LDR observations rely on multi-exposure fusion or inverse tone-mapping, which increase capture complexity and depend on synthetic supervision. With the recent emergence of cameras that directly capture native HDR data in a single exposure, we present the first method for 3D scene reconstruction that directly models native HDR observations. We propose {\bf Native High dynamic range 3D Gaussian Splatting (NH-3DGS)}, which preserves the full dynamic range throughout the reconstruction pipeline. Our key technical contribution is a novel luminance-chromaticity decomposition of the color representation that enables direct optimization from native HDR camera data. We demonstrate on both synthetic and real multi-view HDR datasets that NH-3DGS significantly outperforms existing methods in reconstruction quality and dynamic range preservation, enabling professional-grade 3D reconstruction directly from native HDR captures. Code and datasets will be made available.
High Dynamic Range Novel View Synthesis with Single Exposure
May 02, 2025
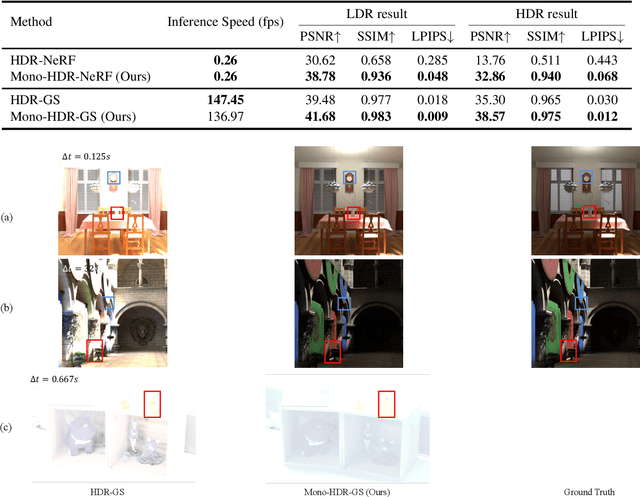
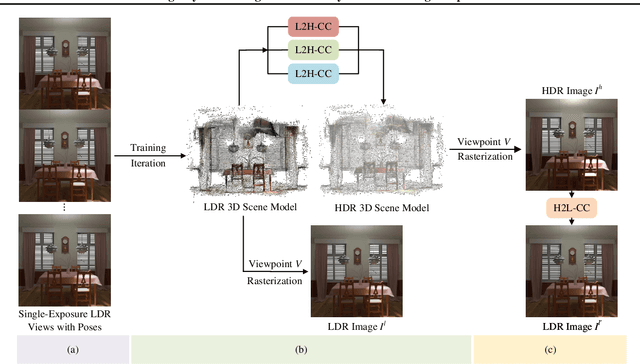
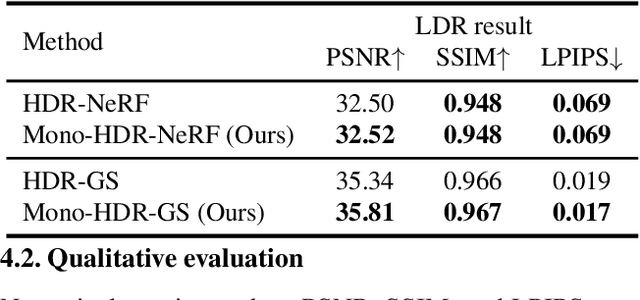
High Dynamic Range Novel View Synthesis (HDR-NVS) aims to establish a 3D scene HDR model from Low Dynamic Range (LDR) imagery. Typically, multiple-exposure LDR images are employed to capture a wider range of brightness levels in a scene, as a single LDR image cannot represent both the brightest and darkest regions simultaneously. While effective, this multiple-exposure HDR-NVS approach has significant limitations, including susceptibility to motion artifacts (e.g., ghosting and blurring), high capture and storage costs. To overcome these challenges, we introduce, for the first time, the single-exposure HDR-NVS problem, where only single exposure LDR images are available during training. We further introduce a novel approach, Mono-HDR-3D, featuring two dedicated modules formulated by the LDR image formation principles, one for converting LDR colors to HDR counterparts, and the other for transforming HDR images to LDR format so that unsupervised learning is enabled in a closed loop. Designed as a meta-algorithm, our approach can be seamlessly integrated with existing NVS models. Extensive experiments show that Mono-HDR-3D significantly outperforms previous methods. Source code will be released.
Operator Learning with Domain Decomposition for Geometry Generalization in PDE Solving
Apr 01, 2025Neural operators have become increasingly popular in solving \textit{partial differential equations} (PDEs) due to their superior capability to capture intricate mappings between function spaces over complex domains. However, the data-hungry nature of operator learning inevitably poses a bottleneck for their widespread applications. At the core of the challenge lies the absence of transferability of neural operators to new geometries. To tackle this issue, we propose operator learning with domain decomposition, a local-to-global framework to solve PDEs on arbitrary geometries. Under this framework, we devise an iterative scheme \textit{Schwarz Neural Inference} (SNI). This scheme allows for partitioning of the problem domain into smaller subdomains, on which local problems can be solved with neural operators, and stitching local solutions to construct a global solution. Additionally, we provide a theoretical analysis of the convergence rate and error bound. We conduct extensive experiments on several representative PDEs with diverse boundary conditions and achieve remarkable geometry generalization compared to alternative methods. These analysis and experiments demonstrate the proposed framework's potential in addressing challenges related to geometry generalization and data efficiency.
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023



Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.
A Large Dataset of Historical Japanese Documents with Complex Layouts
Apr 18, 2020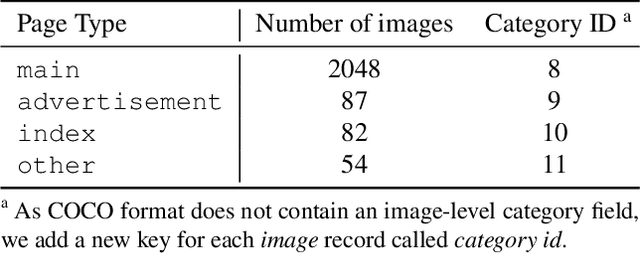
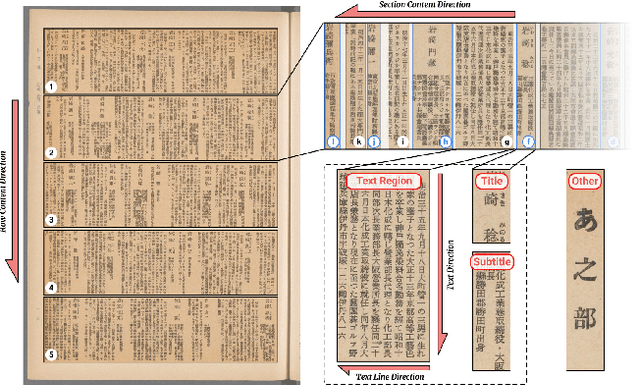
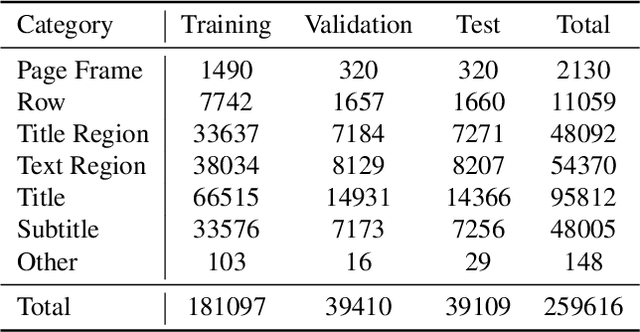
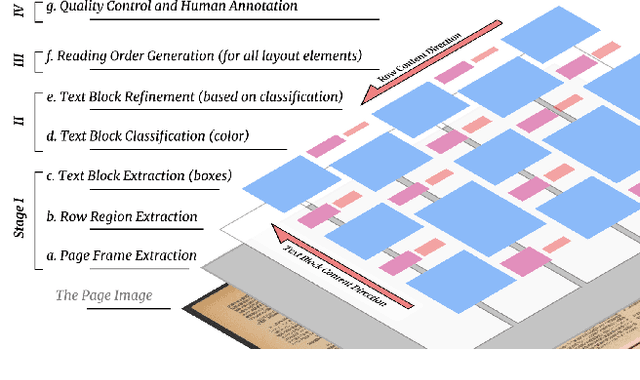
Deep learning-based approaches for automatic document layout analysis and content extraction have the potential to unlock rich information trapped in historical documents on a large scale. One major hurdle is the lack of large datasets for training robust models. In particular, little training data exist for Asian languages. To this end, we present HJDataset, a Large Dataset of Historical Japanese Documents with Complex Layouts. It contains over 250,000 layout element annotations of seven types. In addition to bounding boxes and masks of the content regions, it also includes the hierarchical structures and reading orders for layout elements. The dataset is constructed using a combination of human and machine efforts. A semi-rule based method is developed to extract the layout elements, and the results are checked by human inspectors. The resulting large-scale dataset is used to provide baseline performance analyses for text region detection using state-of-the-art deep learning models. And we demonstrate the usefulness of the dataset on real-world document digitization tasks. The dataset is available at https://dell-research-harvard.github.io/HJDataset/.
Connecting First and Second Order Recurrent Networks with Deterministic Finite Automata
Nov 12, 2019

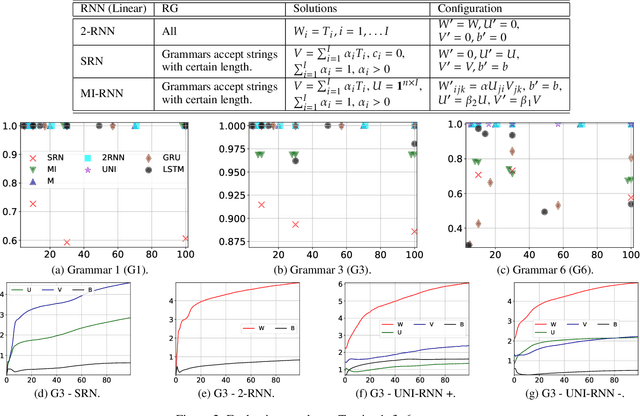
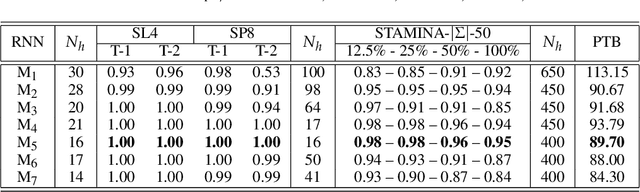
We propose an approach that connects recurrent networks with different orders of hidden interaction with regular grammars of different levels of complexity. We argue that the correspondence between recurrent networks and formal computational models gives understanding to the analysis of the complicated behaviors of recurrent networks. We introduce an entropy value that categorizes all regular grammars into three classes with different levels of complexity, and show that several existing recurrent networks match grammars from either all or partial classes. As such, the differences between regular grammars reveal the different properties of these models. We also provide a unification of all investigated recurrent networks. Our evaluation shows that the unified recurrent network has improved performance in learning grammars, and demonstrates comparable performance on a real-world dataset with more complicated models.
Shapley Homology: Topological Analysis of Sample Influence for Neural Networks
Oct 15, 2019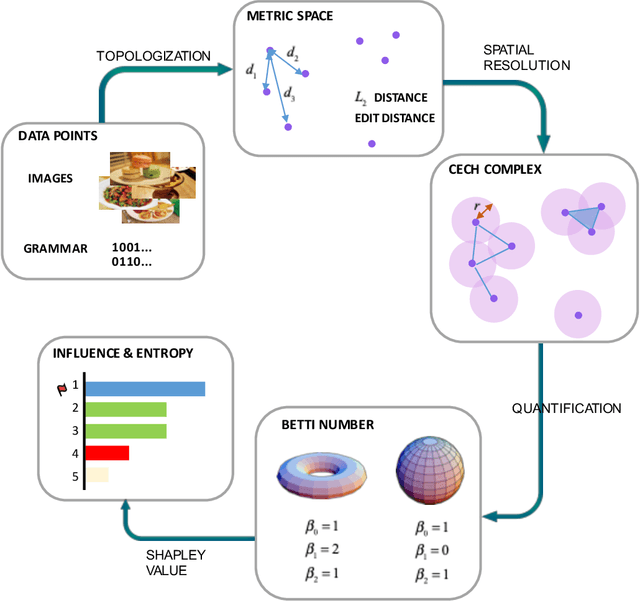

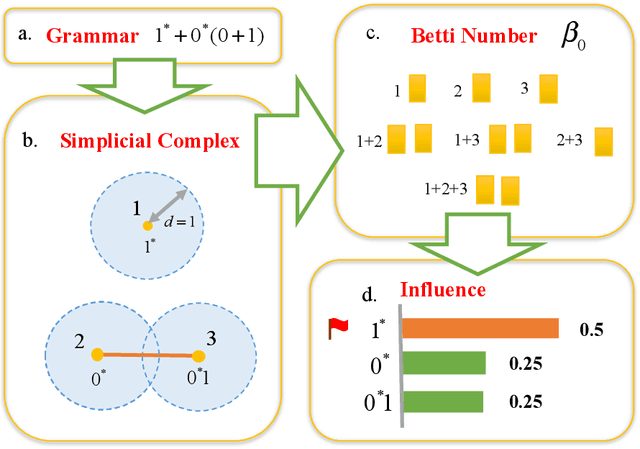
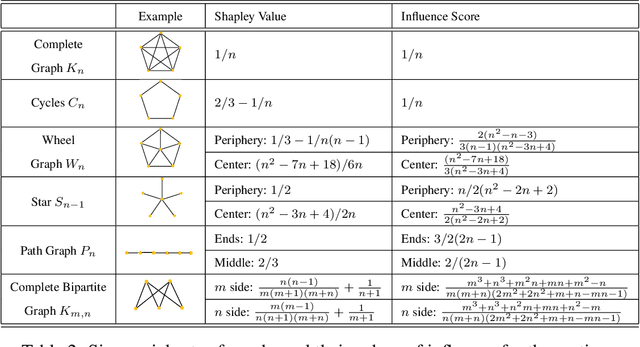
Data samples collected for training machine learning models are typically assumed to be independent and identically distributed (iid). Recent research has demonstrated that this assumption can be problematic as it simplifies the manifold of structured data. This has motivated different research areas such as data poisoning, model improvement, and explanation of machine learning models. In this work, we study the influence of a sample on determining the intrinsic topological features of its underlying manifold. We propose the Shapley Homology framework, which provides a quantitative metric for the influence of a sample of the homology of a simplicial complex. By interpreting the influence as a probability measure, we further define an entropy which reflects the complexity of the data manifold. Our empirical studies show that when using the 0-dimensional homology, on neighboring graphs, samples with higher influence scores have more impact on the accuracy of neural networks for determining the graph connectivity and on several regular grammars whose higher entropy values imply more difficulty in being learned.
Verification of Recurrent Neural Networks Through Rule Extraction
Nov 14, 2018
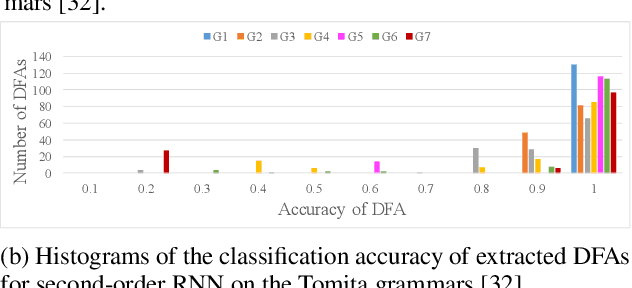
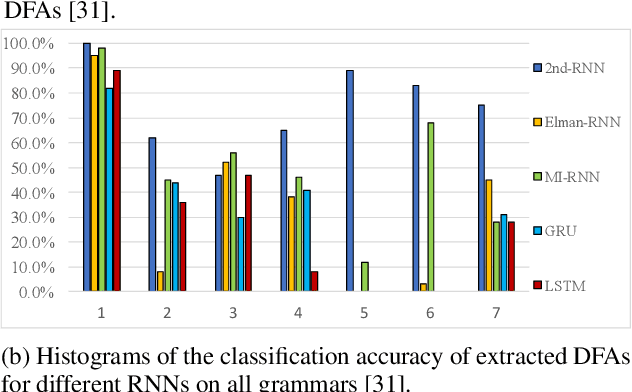
The verification problem for neural networks is verifying whether a neural network will suffer from adversarial samples, or approximating the maximal allowed scale of adversarial perturbation that can be endured. While most prior work contributes to verifying feed-forward networks, little has been explored for verifying recurrent networks. This is due to the existence of a more rigorous constraint on the perturbation space for sequential data, and the lack of a proper metric for measuring the perturbation. In this work, we address these challenges by proposing a metric which measures the distance between strings, and use deterministic finite automata (DFA) to represent a rigorous oracle which examines if the generated adversarial samples violate certain constraints on a perturbation. More specifically, we empirically show that certain recurrent networks allow relatively stable DFA extraction. As such, DFAs extracted from these recurrent networks can serve as a surrogate oracle for when the ground truth DFA is unknown. We apply our verification mechanism to several widely used recurrent networks on a set of the Tomita grammars. The results demonstrate that only a few models remain robust against adversarial samples. In addition, we show that for grammars with different levels of complexity, there is also a difference in the difficulty of robust learning of these grammars.
A Comparison of Rule Extraction for Different Recurrent Neural Network Models and Grammatical Complexity
Jan 16, 2018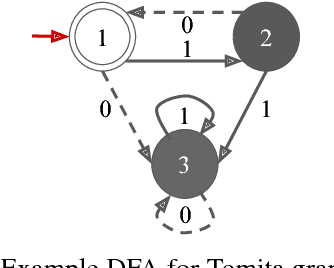
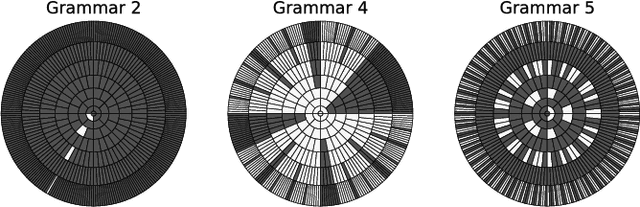
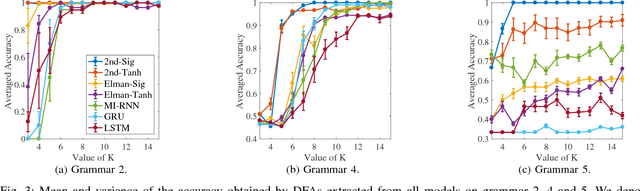
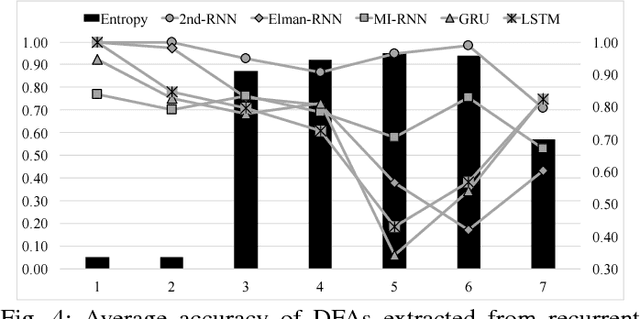
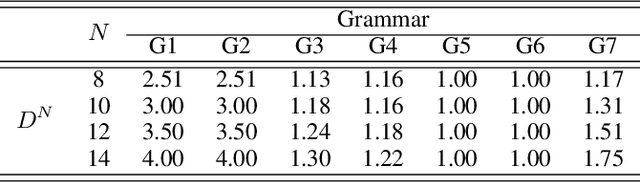
It has been shown that rules can be extracted from highly non-linear, recursive models such as recurrent neural networks (RNNs). The RNN models mostly investigated include both Elman networks and second-order recurrent networks. Recently, new types of RNNs have demonstrated superior power in handling many machine learning tasks, especially when structural data is involved such as language modeling. Here, we empirically evaluate different recurrent models on the task of learning deterministic finite automata (DFA), the seven Tomita grammars. We are interested in the capability of recurrent models with different architectures in learning and expressing regular grammars, which can be the building blocks for many applications dealing with structural data. Our experiments show that a second-order RNN provides the best and stablest performance of extracting DFA over all Tomita grammars and that other RNN models are greatly influenced by different Tomita grammars. To better understand these results, we provide a theoretical analysis of the "complexity" of different grammars, by introducing the entropy and the averaged edit distance of regular grammars defined in this paper. Through our analysis, we categorize all Tomita grammars into different classes, which explains the inconsistency in the performance of extraction observed across all RNN models.
An Empirical Evaluation of Rule Extraction from Recurrent Neural Networks
Nov 28, 2017Rule extraction from black-box models is critical in domains that require model validation before implementation, as can be the case in credit scoring and medical diagnosis. Though already a challenging problem in statistical learning in general, the difficulty is even greater when highly non-linear, recursive models, such as recurrent neural networks (RNNs), are fit to data. Here, we study the extraction of rules from second order recurrent neural networks trained to recognize the Tomita grammars. We show that production rules can be stably extracted from trained RNNs and that in certain cases the rules outperform the trained RNNs.