 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating PDE-Constrained Optimization by the Derivative of Neural Operators
Jun 16, 2025PDE-Constrained Optimization (PDECO) problems can be accelerated significantly by employing gradient-based methods with surrogate models like neural operators compared to traditional numerical solvers. However, this approach faces two key challenges: (1) **Data inefficiency**: Lack of efficient data sampling and effective training for neural operators, particularly for optimization purpose. (2) **Instability**: High risk of optimization derailment due to inaccurate neural operator predictions and gradients. To address these challenges, we propose a novel framework: (1) **Optimization-oriented training**: we leverage data from full steps of traditional optimization algorithms and employ a specialized training method for neural operators. (2) **Enhanced derivative learning**: We introduce a *Virtual-Fourier* layer to enhance derivative learning within the neural operator, a crucial aspect for gradient-based optimization. (3) **Hybrid optimization**: We implement a hybrid approach that integrates neural operators with numerical solvers, providing robust regularization for the optimization process. Our extensive experimental results demonstrate the effectiveness of our model in accurately learning operators and their derivatives. Furthermore, our hybrid optimization approach exhibits robust convergence.
Operator Learning with Domain Decomposition for Geometry Generalization in PDE Solving
Apr 01, 2025Neural operators have become increasingly popular in solving \textit{partial differential equations} (PDEs) due to their superior capability to capture intricate mappings between function spaces over complex domains. However, the data-hungry nature of operator learning inevitably poses a bottleneck for their widespread applications. At the core of the challenge lies the absence of transferability of neural operators to new geometries. To tackle this issue, we propose operator learning with domain decomposition, a local-to-global framework to solve PDEs on arbitrary geometries. Under this framework, we devise an iterative scheme \textit{Schwarz Neural Inference} (SNI). This scheme allows for partitioning of the problem domain into smaller subdomains, on which local problems can be solved with neural operators, and stitching local solutions to construct a global solution. Additionally, we provide a theoretical analysis of the convergence rate and error bound. We conduct extensive experiments on several representative PDEs with diverse boundary conditions and achieve remarkable geometry generalization compared to alternative methods. These analysis and experiments demonstrate the proposed framework's potential in addressing challenges related to geometry generalization and data efficiency.
Reference Neural Operators: Learning the Smooth Dependence of Solutions of PDEs on Geometric Deformations
May 27, 2024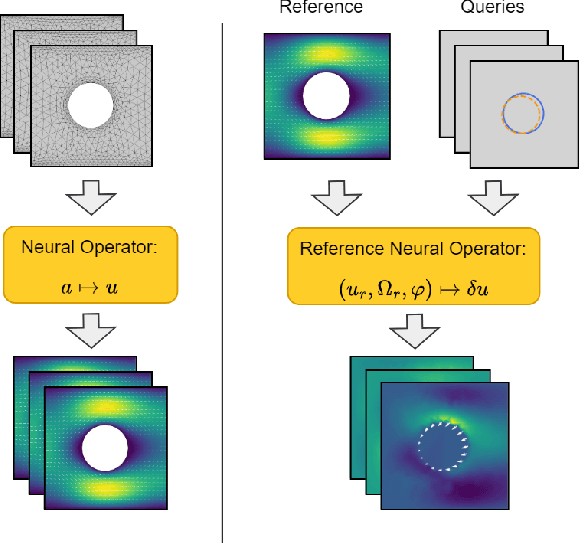
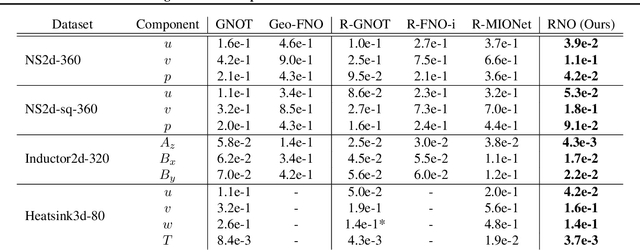
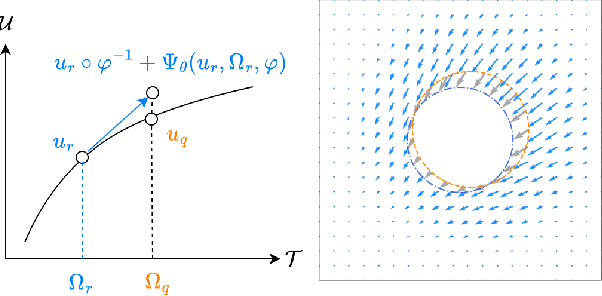

For partial differential equations on domains of arbitrary shapes, existing works of neural operators attempt to learn a mapping from geometries to solutions. It often requires a large dataset of geometry-solution pairs in order to obtain a sufficiently accurate neural operator. However, for many industrial applications, e.g., engineering design optimization, it can be prohibitive to satisfy the requirement since even a single simulation may take hours or days of computation. To address this issue, we propose reference neural operators (RNO), a novel way of implementing neural operators, i.e., to learn the smooth dependence of solutions on geometric deformations. Specifically, given a reference solution, RNO can predict solutions corresponding to arbitrary deformations of the referred geometry. This approach turns out to be much more data efficient. Through extensive experiments, we show that RNO can learn the dependence across various types and different numbers of geometry objects with relatively small datasets. RNO outperforms baseline models in accuracy by a large lead and achieves up to 80% error reduction.
NUNO: A General Framework for Learning Parametric PDEs with Non-Uniform Data
May 31, 2023



The neural operator has emerged as a powerful tool in learning mappings between function spaces in PDEs. However, when faced with real-world physical data, which are often highly non-uniformly distributed, it is challenging to use mesh-based techniques such as the FFT. To address this, we introduce the Non-Uniform Neural Operator (NUNO), a comprehensive framework designed for efficient operator learning with non-uniform data. Leveraging a K-D tree-based domain decomposition, we transform non-uniform data into uniform grids while effectively controlling interpolation error, thereby paralleling the speed and accuracy of learning from non-uniform data. We conduct extensive experiments on 2D elasticity, (2+1)D channel flow, and a 3D multi-physics heatsink, which, to our knowledge, marks a novel exploration into 3D PDE problems with complex geometries. Our framework has reduced error rates by up to 60% and enhanced training speeds by 2x to 30x. The code is now available at https://github.com/thu-ml/NUNO.
GNOT: A General Neural Operator Transformer for Operator Learning
Feb 28, 2023Learning partial differential equations' (PDEs) solution operators is an essential problem in machine learning. However, there are several challenges for learning operators in practical applications like the irregular mesh, multiple input functions, and complexity of the PDEs' solution. To address these challenges, we propose a general neural operator transformer (GNOT), a scalable and effective transformer-based framework for learning operators. By designing a novel heterogeneous normalized attention layer, our model is highly flexible to handle multiple input functions and irregular mesh. Besides, we introduce a geometric gating mechanism which could be viewed as a soft domain decomposition to solve the multi-scale problems. The large model capacity of transformer architecture grants our model the possibility to scale to large datasets and practical problems. We conduct extensive experiments on multiple challenging datasets from different domains and achieve a remarkable improvement compared with alternative methods.
A Unified Hard-Constraint Framework for Solving Geometrically Complex PDEs
Oct 10, 2022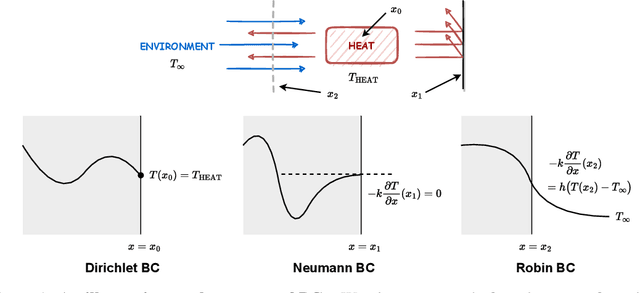
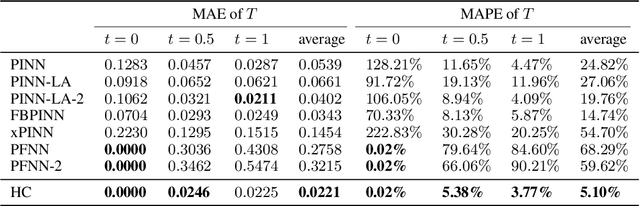
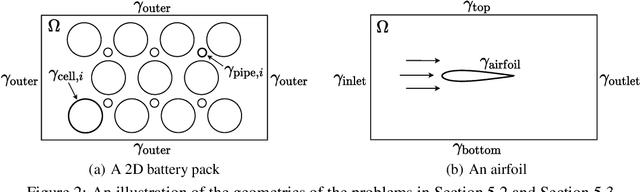
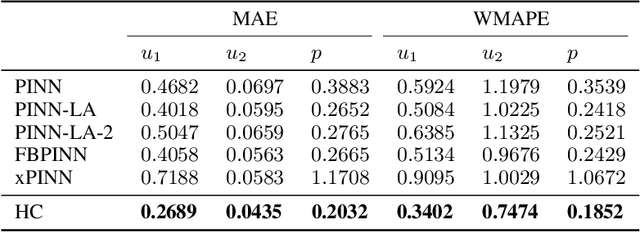
We present a unified hard-constraint framework for solving geometrically complex PDEs with neural networks, where the most commonly used Dirichlet, Neumann, and Robin boundary conditions (BCs) are considered. Specifically, we first introduce the "extra fields" from the mixed finite element method to reformulate the PDEs so as to equivalently transform the three types of BCs into linear forms. Based on the reformulation, we derive the general solutions of the BCs analytically, which are employed to construct an ansatz that automatically satisfies the BCs. With such a framework, we can train the neural networks without adding extra loss terms and thus efficiently handle geometrically complex PDEs, alleviating the unbalanced competition between the loss terms corresponding to the BCs and PDEs. We theoretically demonstrate that the "extra fields" can stabilize the training process. Experimental results on real-world geometrically complex PDEs showcase the effectiveness of our method compared with state-of-the-art baselines.
Bi-level Physics-Informed Neural Networks for PDE Constrained Optimization using Broyden's Hypergradients
Sep 15, 2022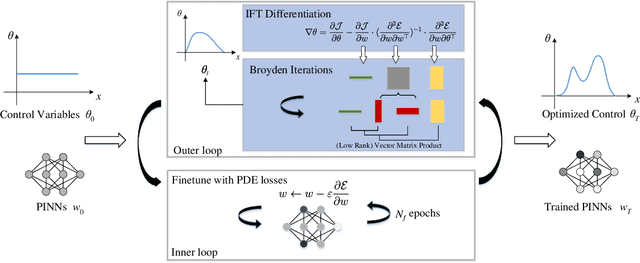
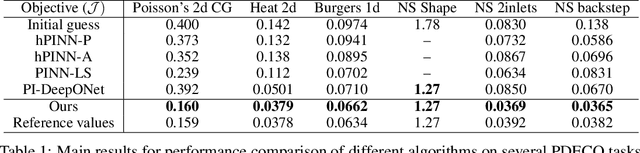


Deep learning based approaches like Physics-informed neural networks (PINNs) and DeepONets have shown promise on solving PDE constrained optimization (PDECO) problems. However, existing methods are insufficient to handle those PDE constraints that have a complicated or nonlinear dependency on optimization targets. In this paper, we present a novel bi-level optimization framework to resolve the challenge by decoupling the optimization of the targets and constraints. For the inner loop optimization, we adopt PINNs to solve the PDE constraints only. For the outer loop, we design a novel method by using Broyden's method based on the Implicit Function Theorem (IFT), which is efficient and accurate for approximating hypergradients. We further present theoretical explanations and error analysis of the hypergradients computation. Extensive experiments on multiple large-scale and nonlinear PDE constrained optimization problems demonstrate that our method achieves state-of-the-art results compared with strong baselines.
Revisiting Factorizing Aggregated Posterior in Learning Disentangled Representations
Sep 12, 2020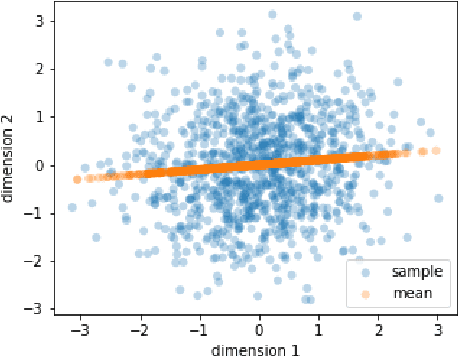



In the problem of learning disentangled representations, one of the promising methods is to factorize aggregated posterior by penalizing the total correlation of sampled latent variables. However, this well-motivated strategy has a blind spot: there is a disparity between the sampled latent representation and its corresponding mean representation. In this paper, we provide a theoretical explanation that low total correlation of sampled representation cannot guarantee low total correlation of the mean representation. Indeed, we prove that for the multivariate normal distributions, the mean representation with arbitrarily high total correlation can have a corresponding sampled representation with bounded total correlation. We also propose a method to eliminate this disparity. Experiments show that our model can learn a mean representation with much lower total correlation, hence a factorized mean representation. Moreover, we offer a detailed explanation of the limitations of factorizing aggregated posterior -- factor disintegration. Our work indicates a potential direction for future research of disentangled learning.