 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating PDE-Constrained Optimization by the Derivative of Neural Operators
Jun 16, 2025PDE-Constrained Optimization (PDECO) problems can be accelerated significantly by employing gradient-based methods with surrogate models like neural operators compared to traditional numerical solvers. However, this approach faces two key challenges: (1) **Data inefficiency**: Lack of efficient data sampling and effective training for neural operators, particularly for optimization purpose. (2) **Instability**: High risk of optimization derailment due to inaccurate neural operator predictions and gradients. To address these challenges, we propose a novel framework: (1) **Optimization-oriented training**: we leverage data from full steps of traditional optimization algorithms and employ a specialized training method for neural operators. (2) **Enhanced derivative learning**: We introduce a *Virtual-Fourier* layer to enhance derivative learning within the neural operator, a crucial aspect for gradient-based optimization. (3) **Hybrid optimization**: We implement a hybrid approach that integrates neural operators with numerical solvers, providing robust regularization for the optimization process. Our extensive experimental results demonstrate the effectiveness of our model in accurately learning operators and their derivatives. Furthermore, our hybrid optimization approach exhibits robust convergence.
System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts
May 25, 2025Chain-of-thought (CoT) reasoning enables large language models (LLMs) to move beyond fast System-1 responses and engage in deliberative System-2 reasoning. However, this comes at the cost of significant inefficiency due to verbose intermediate output. Recent latent-space reasoning methods improve efficiency by operating on hidden states without decoding into language, yet they treat all steps uniformly, failing to distinguish critical deductions from auxiliary steps and resulting in suboptimal use of computational resources. In this paper, we propose System-1.5 Reasoning, an adaptive reasoning framework that dynamically allocates computation across reasoning steps through shortcut paths in latent space.Specifically, System-1.5 Reasoning introduces two types of dynamic shortcuts. The model depth shortcut (DS) adaptively reasons along the vertical depth by early exiting non-critical tokens through lightweight adapter branches, while allowing critical tokens to continue through deeper Transformer layers. The step shortcut (SS) reuses hidden states across the decoding steps to skip trivial steps and reason horizontally in latent space. Training System-1.5 Reasoning involves a two-stage self-distillation process: first distilling natural language CoT into latent-space continuous thought, and then distilling full-path System-2 latent reasoning into adaptive shortcut paths (System-1.5 Reasoning).Experiments on reasoning tasks demonstrate the superior performance of our method. For example, on GSM8K, System-1.5 Reasoning achieves reasoning performance comparable to traditional CoT fine-tuning methods while accelerating inference by over 20x and reducing token generation by 92.31% on average.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
R$^3$Mem: Bridging Memory Retention and Retrieval via Reversible Compression
Feb 21, 2025Memory plays a key role in enhancing LLMs' performance when deployed to real-world applications. Existing solutions face trade-offs: explicit memory designs based on external storage require complex management and incur storage overhead, while implicit memory designs that store information via parameters struggle with reliable retrieval. In this paper, we propose R$^3$Mem, a memory network that optimizes both information Retention and Retrieval through Reversible context compression. Specifically, R$^3$Mem employs virtual memory tokens to compress and encode infinitely long histories, further enhanced by a hierarchical compression strategy that refines information from document- to entity-level for improved assimilation across granularities. For retrieval, R$^3$Mem employs a reversible architecture, reconstructing raw data by invoking the model backward with compressed information. Implemented via parameter-efficient fine-tuning, it can integrate seamlessly with any Transformer-based model. Experiments demonstrate that our memory design achieves state-of-the-art performance in long-context language modeling and retrieval-augmented generation tasks. It also significantly outperforms conventional memory modules in long-horizon interaction tasks like conversational agents, showcasing its potential for next-generation retrieval systems.
AverageLinear: Enhance Long-Term Time series forcasting with simple averaging
Dec 30, 2024



Long-term time series analysis aims to forecast long-term trends by examining changes over past and future periods. The intricacy of time series data poses significant challenges for modeling. Models based on the Transformer architecture, through the application of attention mechanisms to channels and sequences, have demonstrated notable performance advantages. In contrast, methods based on convolutional neural networks or linear models often struggle to effectively handle scenarios with large number of channels. However, our research reveals that the attention mechanism is not the core component responsible for performance enhancement. We have designed an exceedingly simple linear structure AverageLinear. By employing straightforward channel embedding and averaging operations, this model can effectively capture correlations between channels while maintaining a lightweight architecture. Experimentss on real-world datasets shows that AverageLinear matches or even surpasses state-of-the-art Transformer-based structures in performance. This indicates that using purely linear structures can also endow models with robust predictive power.
OSCAR: Operating System Control via State-Aware Reasoning and Re-Planning
Oct 24, 2024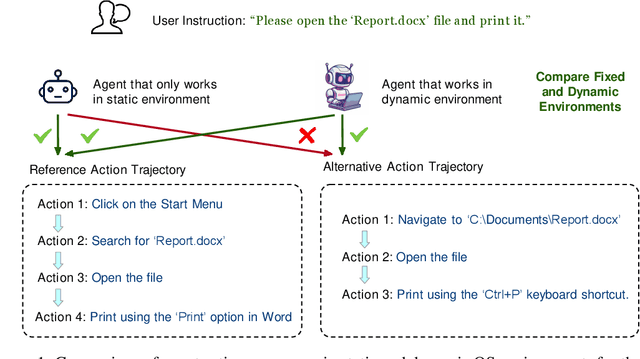
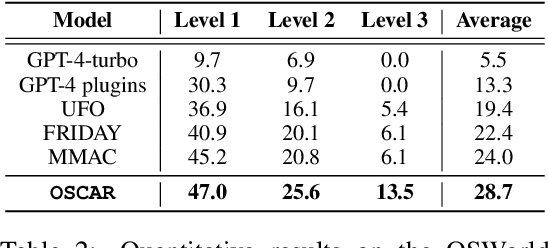
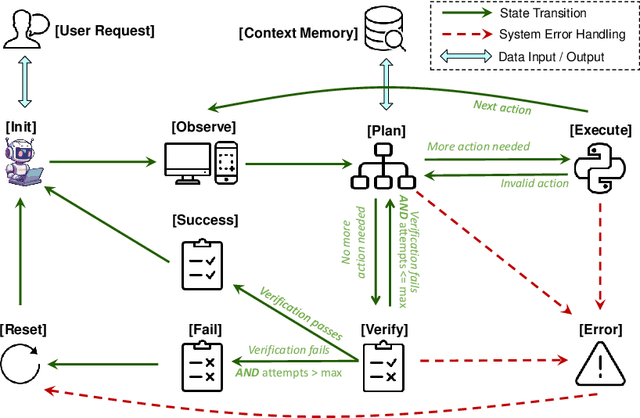
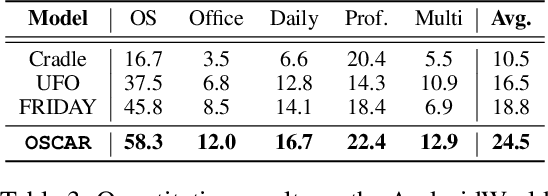
Large language models (LLMs) and large multimodal models (LMMs) have shown great potential in automating complex tasks like web browsing and gaming. However, their ability to generalize across diverse applications remains limited, hindering broader utility. To address this challenge, we present OSCAR: Operating System Control via state-Aware reasoning and Re-planning. OSCAR is a generalist agent designed to autonomously navigate and interact with various desktop and mobile applications through standardized controls, such as mouse and keyboard inputs, while processing screen images to fulfill user commands. OSCAR translates human instructions into executable Python code, enabling precise control over graphical user interfaces (GUIs). To enhance stability and adaptability, OSCAR operates as a state machine, equipped with error-handling mechanisms and dynamic task re-planning, allowing it to efficiently adjust to real-time feedback and exceptions. We demonstrate OSCAR's effectiveness through extensive experiments on diverse benchmarks across desktop and mobile platforms, where it transforms complex workflows into simple natural language commands, significantly boosting user productivity. Our code will be open-source upon publication.
A Mallows-like Criterion for Anomaly Detection with Random Forest Implementation
May 29, 2024The effectiveness of anomaly signal detection can be significantly undermined by the inherent uncertainty of relying on one specified model. Under the framework of model average methods, this paper proposes a novel criterion to select the weights on aggregation of multiple models, wherein the focal loss function accounts for the classification of extremely imbalanced data. This strategy is further integrated into Random Forest algorithm by replacing the conventional voting method. We have evaluated the proposed method on benchmark datasets across various domains, including network intrusion. The findings indicate that our proposed method not only surpasses the model averaging with typical loss functions but also outstrips common anomaly detection algorithms in terms of accuracy and robustness.
Reference Neural Operators: Learning the Smooth Dependence of Solutions of PDEs on Geometric Deformations
May 27, 2024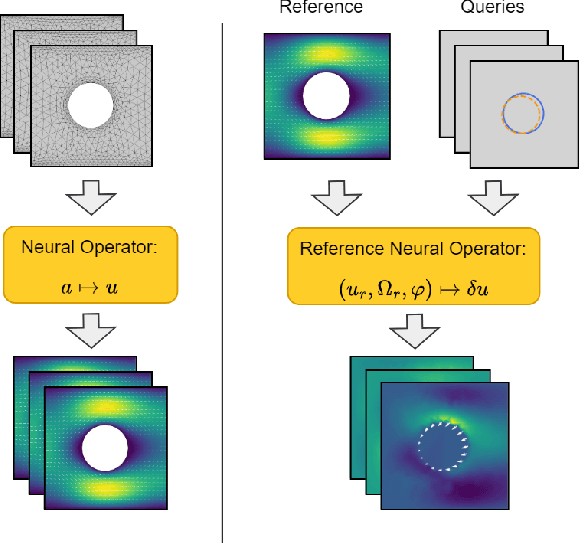
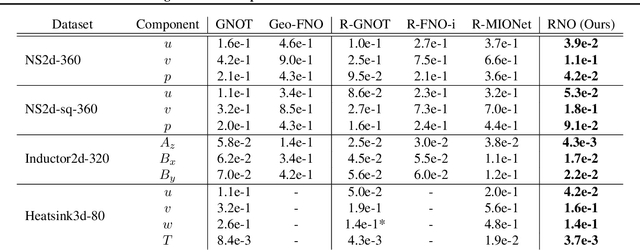
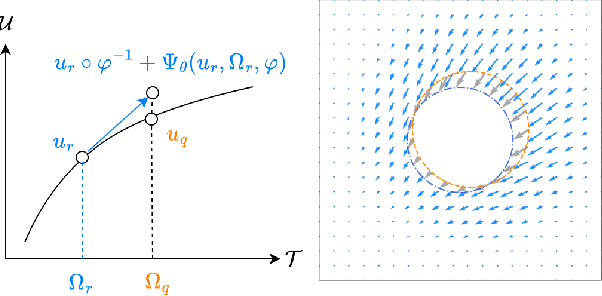

For partial differential equations on domains of arbitrary shapes, existing works of neural operators attempt to learn a mapping from geometries to solutions. It often requires a large dataset of geometry-solution pairs in order to obtain a sufficiently accurate neural operator. However, for many industrial applications, e.g., engineering design optimization, it can be prohibitive to satisfy the requirement since even a single simulation may take hours or days of computation. To address this issue, we propose reference neural operators (RNO), a novel way of implementing neural operators, i.e., to learn the smooth dependence of solutions on geometric deformations. Specifically, given a reference solution, RNO can predict solutions corresponding to arbitrary deformations of the referred geometry. This approach turns out to be much more data efficient. Through extensive experiments, we show that RNO can learn the dependence across various types and different numbers of geometry objects with relatively small datasets. RNO outperforms baseline models in accuracy by a large lead and achieves up to 80% error reduction.
FAC$^2$E: Better Understanding Large Language Model Capabilities by Dissociating Language and Cognition
Feb 29, 2024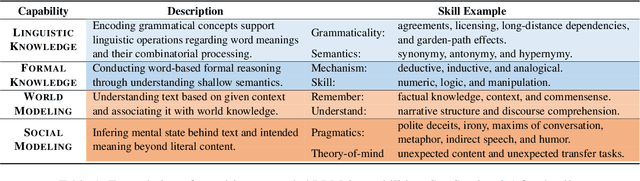

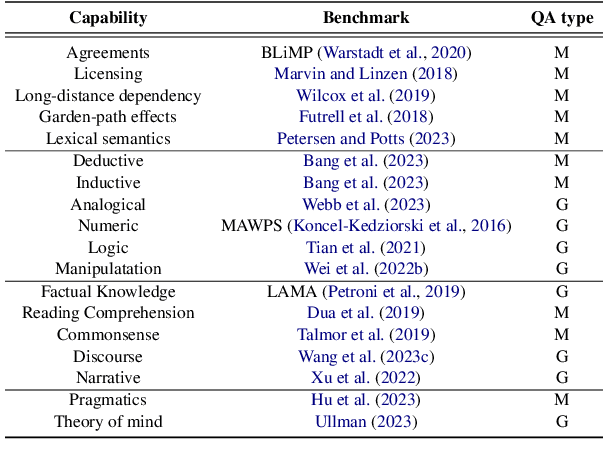
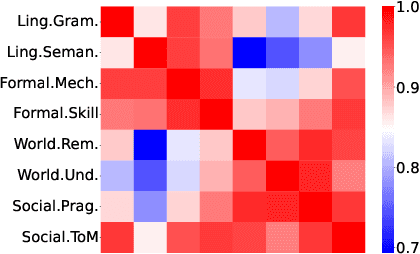
Large language models (LLMs) are primarily evaluated by overall performance on various text understanding and generation tasks. However, such a paradigm fails to comprehensively differentiate the fine-grained language and cognitive skills, rendering the lack of sufficient interpretation to LLMs' capabilities. In this paper, we present FAC$^2$E, a framework for Fine-grAined and Cognition-grounded LLMs' Capability Evaluation. Specifically, we formulate LLMs' evaluation in a multi-dimensional and explainable manner by dissociating the language-related capabilities and the cognition-related ones. Besides, through extracting the intermediate reasoning from LLMs, we further break down the process of applying a specific capability into three sub-steps: recalling relevant knowledge, utilizing knowledge, and solving problems. Finally, FAC$^2$E evaluates each sub-step of each fine-grained capability, providing a two-faceted diagnosis for LLMs. Utilizing FAC$^2$E, we identify a common shortfall in knowledge utilization among models and propose a straightforward, knowledge-enhanced method to mitigate this issue. Our results not only showcase promising performance enhancements but also highlight a direction for future LLM advancements.
SkillQG: Learning to Generate Question for Reading Comprehension Assessment
May 08, 2023We present $\textbf{$\texttt{SkillQG}$}$: a question generation framework with controllable comprehension types for assessing and improving machine reading comprehension models. Existing question generation systems widely differentiate questions by $\textit{literal}$ information such as question words and answer types to generate semantically relevant questions for a given context. However, they rarely consider the $\textit{comprehension}$ nature of questions, i.e. the different comprehension capabilities embodied by different questions. In comparison, our $\texttt{SkillQG}$ is able to tailor a fine-grained assessment and improvement to the capabilities of question answering models built on it. Specifically, we first frame the comprehension type of questions based on a hierarchical skill-based schema, then formulate $\texttt{SkillQG}$ as a skill-conditioned question generator. Furthermore, to improve the controllability of generation, we augment the input text with question focus and skill-specific knowledge, which are constructed by iteratively prompting the pre-trained language models. Empirical results demonstrate that $\texttt{SkillQG}$ outperforms baselines in terms of quality, relevance, and skill-controllability while showing a promising performance boost in downstream question answering task.