 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom "Thinking" to "Justifying": Aligning High-Stakes Explainability with Professional Communication Standards
Jan 12, 2026Explainable AI (XAI) in high-stakes domains should help stakeholders trust and verify system outputs. Yet Chain-of-Thought methods reason before concluding, and logical gaps or hallucinations can yield conclusions that do not reliably align with their rationale. Thus, we propose "Result -> Justify", which constrains the output communication to present a conclusion before its structured justification. We introduce SEF (Structured Explainability Framework), operationalizing professional conventions (e.g., CREAC, BLUF) via six metrics for structure and grounding. Experiments across four tasks in three domains validate this approach: all six metrics correlate with correctness (r=0.20-0.42; p<0.001), and SEF achieves 83.9% accuracy (+5.3 over CoT). These results suggest structured justification can improve verifiability and may also improve reliability.
Hidden Division of Labor in Scientific Teams Revealed Through 1.6 Million LaTeX Files
Feb 11, 2025Recognition of individual contributions is fundamental to the scientific reward system, yet coauthored papers obscure who did what. Traditional proxies-author order and career stage-reinforce biases, while contribution statements remain self-reported and limited to select journals. We construct the first large-scale dataset on writing contributions by analyzing author-specific macros in LaTeX files from 1.6 million papers (1991-2023) by 2 million scientists. Validation against self-reported statements (precision = 0.87), author order patterns, field-specific norms, and Overleaf records (Spearman's rho = 0.6, p < 0.05) confirms the reliability of the created data. Using explicit section information, we reveal a hidden division of labor within scientific teams: some authors primarily contribute to conceptual sections (e.g., Introduction and Discussion), while others focus on technical sections (e.g., Methods and Experiments). These findings provide the first large-scale evidence of implicit labor division in scientific teams, challenging conventional authorship practices and informing institutional policies on credit allocation.
Ask Questions with Double Hints: Visual Question Generation with Answer-awareness and Region-reference
Jul 06, 2024



The visual question generation (VQG) task aims to generate human-like questions from an image and potentially other side information (e.g. answer type). Previous works on VQG fall in two aspects: i) They suffer from one image to many questions mapping problem, which leads to the failure of generating referential and meaningful questions from an image. ii) They fail to model complex implicit relations among the visual objects in an image and also overlook potential interactions between the side information and image. To address these limitations, we first propose a novel learning paradigm to generate visual questions with answer-awareness and region-reference. Concretely, we aim to ask the right visual questions with Double Hints - textual answers and visual regions of interests, which could effectively mitigate the existing one-to-many mapping issue. Particularly, we develop a simple methodology to self-learn the visual hints without introducing any additional human annotations. Furthermore, to capture these sophisticated relationships, we propose a new double-hints guided Graph-to-Sequence learning framework, which first models them as a dynamic graph and learns the implicit topology end-to-end, and then utilizes a graph-to-sequence model to generate the questions with double hints. Experimental results demonstrate the priority of our proposed method.
Iterative or Innovative? A Problem-Oriented Perspective for Code Optimization
Jun 17, 2024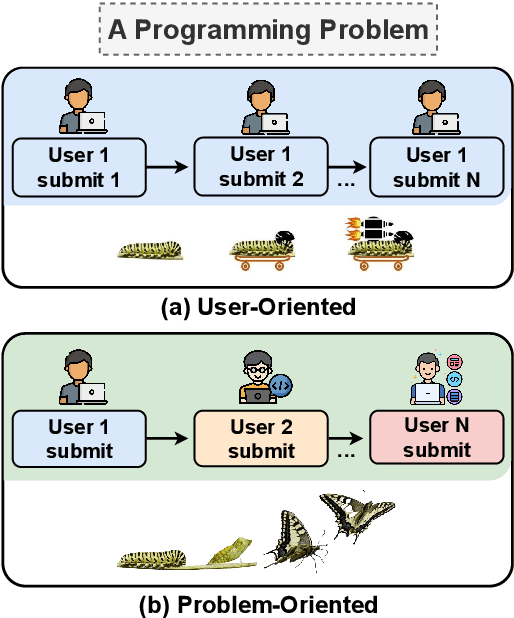



Large language models (LLMs) have demonstrated strong capabilities in solving a wide range of programming tasks. However, LLMs have rarely been explored for code optimization. In this paper, we explore code optimization with a focus on performance enhancement, specifically aiming to optimize code for minimal execution time. The recently proposed first PIE dataset for performance optimization constructs program optimization pairs based on iterative submissions from the same programmer for the same problem. However, this approach restricts LLMs to local performance improvements, neglecting global algorithmic innovation. Therefore, we adopt a completely different perspective by reconstructing the optimization pairs into a problem-oriented approach. This allows for the integration of various ingenious ideas from different programmers tackling the same problem. Experimental results demonstrate that adapting LLMs to problem-oriented optimization pairs significantly enhances their optimization capabilities. Meanwhile, we identified performance bottlenecks within the problem-oriented perspective. By employing model merge, we further overcame bottlenecks and ultimately elevated the program optimization ratio ($51.76\%\rightarrow76.65\%$) and speedup ($2.65\times\rightarrow5.09\times$) to new levels.
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
May 30, 2024



Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive "low-entropy" tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
Mar 06, 2024



Treatment effect estimation (TEE) is the task of determining the impact of various treatments on patient outcomes. Current TEE methods fall short due to reliance on limited labeled data and challenges posed by sparse and high-dimensional observational patient data. To address the challenges, we introduce a novel pre-training and fine-tuning framework, KG-TREAT, which synergizes large-scale observational patient data with biomedical knowledge graphs (KGs) to enhance TEE. Unlike previous approaches, KG-TREAT constructs dual-focus KGs and integrates a deep bi-level attention synergy method for in-depth information fusion, enabling distinct encoding of treatment-covariate and outcome-covariate relationships. KG-TREAT also incorporates two pre-training tasks to ensure a thorough grounding and contextualization of patient data and KGs. Evaluation on four downstream TEE tasks shows KG-TREAT's superiority over existing methods, with an average improvement of 7% in Area under the ROC Curve (AUC) and 9% in Influence Function-based Precision of Estimating Heterogeneous Effects (IF-PEHE). The effectiveness of our estimated treatment effects is further affirmed by alignment with established randomized clinical trial findings.
FAC$^2$E: Better Understanding Large Language Model Capabilities by Dissociating Language and Cognition
Feb 29, 2024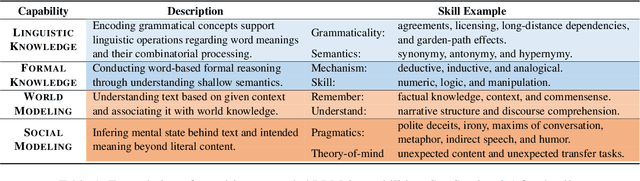

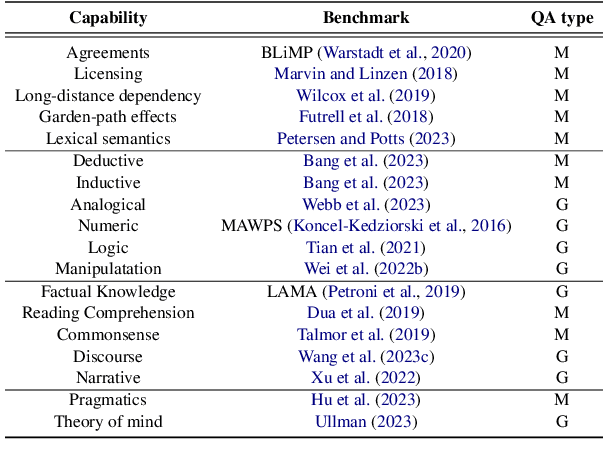
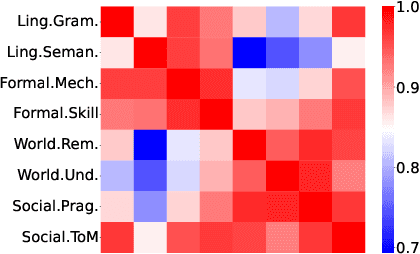
Large language models (LLMs) are primarily evaluated by overall performance on various text understanding and generation tasks. However, such a paradigm fails to comprehensively differentiate the fine-grained language and cognitive skills, rendering the lack of sufficient interpretation to LLMs' capabilities. In this paper, we present FAC$^2$E, a framework for Fine-grAined and Cognition-grounded LLMs' Capability Evaluation. Specifically, we formulate LLMs' evaluation in a multi-dimensional and explainable manner by dissociating the language-related capabilities and the cognition-related ones. Besides, through extracting the intermediate reasoning from LLMs, we further break down the process of applying a specific capability into three sub-steps: recalling relevant knowledge, utilizing knowledge, and solving problems. Finally, FAC$^2$E evaluates each sub-step of each fine-grained capability, providing a two-faceted diagnosis for LLMs. Utilizing FAC$^2$E, we identify a common shortfall in knowledge utilization among models and propose a straightforward, knowledge-enhanced method to mitigate this issue. Our results not only showcase promising performance enhancements but also highlight a direction for future LLM advancements.
AdaCCD: Adaptive Semantic Contrasts Discovery based Cross Lingual Adaptation for Code Clone Detection
Nov 13, 2023



Code Clone Detection, which aims to retrieve functionally similar programs from large code bases, has been attracting increasing attention. Modern software often involves a diverse range of programming languages. However, current code clone detection methods are generally limited to only a few popular programming languages due to insufficient annotated data as well as their own model design constraints. To address these issues, we present AdaCCD, a novel cross-lingual adaptation method that can detect cloned codes in a new language without any annotations in that language. AdaCCD leverages language-agnostic code representations from pre-trained programming language models and propose an Adaptively Refined Contrastive Learning framework to transfer knowledge from resource-rich languages to resource-poor languages. We evaluate the cross-lingual adaptation results of AdaCCD by constructing a multilingual code clone detection benchmark consisting of 5 programming languages. AdaCCD achieves significant improvements over other baselines, and it is even comparable to supervised fine-tuning.
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023



Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.