 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTS-JEPA: Multi-Resolution Joint-Embedding Predictive Architecture for Time-Series Anomaly Prediction
Feb 04, 2026Multivariate time series underpin modern critical infrastructure, making the prediction of anomalies a vital necessity for proactive risk mitigation. While Joint-Embedding Predictive Architectures (JEPA) offer a promising framework for modeling the latent evolution of these systems, their application is hindered by representation collapse and an inability to capture precursor signals across varying temporal scales. To address these limitations, we propose MTS-JEPA, a specialized architecture that integrates a multi-resolution predictive objective with a soft codebook bottleneck. This design explicitly decouples transient shocks from long-term trends, and utilizes the codebook to capture discrete regime transitions. Notably, we find this constraint also acts as an intrinsic regularizer to ensure optimization stability. Empirical evaluations on standard benchmarks confirm that our approach effectively prevents degenerate solutions and achieves state-of-the-art performance under the early-warning protocol.
Efficient Imputation for Patch-based Missing Single-cell Data via Cluster-regularized Optimal Transport
Jan 21, 2026Missing data in single-cell sequencing datasets poses significant challenges for extracting meaningful biological insights. However, existing imputation approaches, which often assume uniformity and data completeness, struggle to address cases with large patches of missing data. In this paper, we present CROT, an optimal transport-based imputation algorithm designed to handle patch-based missing data in tabular formats. Our approach effectively captures the underlying data structure in the presence of significant missingness. Notably, it achieves superior imputation accuracy while significantly reducing runtime, demonstrating its scalability and efficiency for large-scale datasets. This work introduces a robust solution for imputation in heterogeneous, high-dimensional datasets with structured data absence, addressing critical challenges in both biological and clinical data analysis. Our code is available at Anomalous Github.
Resting Neurons, Active Insights: Improving Input Sparsification for Large Language Models
Dec 14, 2025Large Language Models (LLMs) achieve state-of-the-art performance across a wide range of applications, but their massive scale poses significant challenges for both efficiency and interpretability. Structural pruning, which reduces model size by removing redundant computational units such as neurons, has been widely explored as a solution, and this study devotes to input sparsification, an increasingly popular technique that improves efficiency by selectively activating only a subset of entry values for each input. However, existing approaches focus primarily on computational savings, often overlooking the representational consequences of sparsification and leaving a noticeable performance gap compared to full models. In this work, we first reinterpret input sparsification as a form of dynamic structural pruning. Motivated by the spontaneous baseline firing rates observed in biological neurons, we introduce a small set of trainable spontaneous neurons that act as compensatory units to stabilize activations in sparsified LLMs. Experiments demonstrate that these auxiliary neurons substantially reduce the sparsification-induced performance gap while generalizing effectively across tasks.
DeepDR: an integrated deep-learning model web server for drug repositioning
Nov 12, 2025Background: Identifying new indications for approved drugs is a complex and time-consuming process that requires extensive knowledge of pharmacology, clinical data, and advanced computational methods. Recently, deep learning (DL) methods have shown their capability for the accurate prediction of drug repositioning. However, implementing DL-based modeling requires in-depth domain knowledge and proficient programming skills. Results: In this application, we introduce DeepDR, the first integrated platform that combines a variety of established DL-based models for disease- and target-specific drug repositioning tasks. DeepDR leverages invaluable experience to recommend candidate drugs, which covers more than 15 networks and a comprehensive knowledge graph that includes 5.9 million edges across 107 types of relationships connecting drugs, diseases, proteins/genes, pathways, and expression from six existing databases and a large scientific corpus of 24 million PubMed publications. Additionally, the recommended results include detailed descriptions of the recommended drugs and visualize key patterns with interpretability through a knowledge graph. Conclusion: DeepDR is free and open to all users without the requirement of registration. We believe it can provide an easy-to-use, systematic, highly accurate, and computationally automated platform for both experimental and computational scientists.
Dual-Pathway Fusion of EHRs and Knowledge Graphs for Predicting Unseen Drug-Drug Interactions
Nov 10, 2025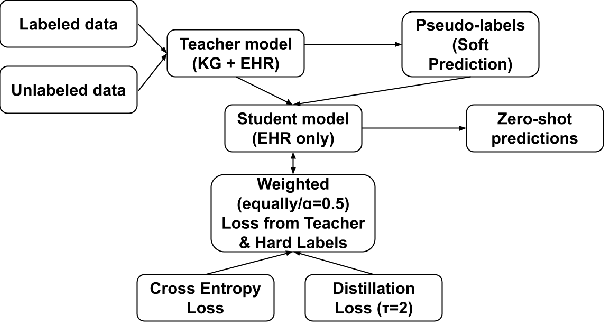
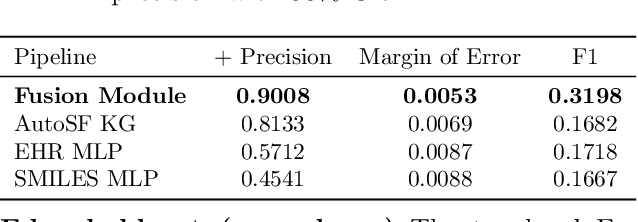


Drug-drug interactions (DDIs) remain a major source of preventable harm, and many clinically important mechanisms are still unknown. Existing models either rely on pharmacologic knowledge graphs (KGs), which fail on unseen drugs, or on electronic health records (EHRs), which are noisy, temporal, and site-dependent. We introduce, to our knowledge, the first system that conditions KG relation scoring on patient-level EHR context and distills that reasoning into an EHR-only model for zero-shot inference. A fusion "Teacher" learns mechanism-specific relations for drug pairs represented in both sources, while a distilled "Student" generalizes to new or rarely used drugs without KG access at inference. Both operate under a shared ontology (set) of pharmacologic mechanisms (drug relations) to produce interpretable, auditable alerts rather than opaque risk scores. Trained on a multi-institution EHR corpus paired with a curated DrugBank DDI graph, and evaluated using a clinically aligned, decision-focused protocol with leakage-safe negatives that avoid artificially easy pairs, the system maintains precision across multi-institutuion test data, produces mechanism-specific, clinically consistent predictions, reduces false alerts (higher precision) at comparable overall detection performance (F1), and misses fewer true interactions compared to prior methods. Case studies further show zero-shot identification of clinically recognized CYP-mediated and pharmacodynamic mechanisms for drugs absent from the KG, supporting real-world use in clinical decision support and pharmacovigilance.
MolBridge: Atom-Level Joint Graph Refinement for Robust Drug-Drug Interaction Event Prediction
Oct 23, 2025Drug combinations offer therapeutic benefits but also carry the risk of adverse drug-drug interactions (DDIs), especially under complex molecular structures. Accurate DDI event prediction requires capturing fine-grained inter-drug relationships, which are critical for modeling metabolic mechanisms such as enzyme-mediated competition. However, existing approaches typically rely on isolated drug representations and fail to explicitly model atom-level cross-molecular interactions, limiting their effectiveness across diverse molecular complexities and DDI type distributions. To address these limitations, we propose MolBridge, a novel atom-level joint graph refinement framework for robust DDI event prediction. MolBridge constructs a joint graph that integrates atomic structures of drug pairs, enabling direct modeling of inter-drug associations. A central challenge in such joint graph settings is the potential loss of information caused by over-smoothing when modeling long-range atomic dependencies. To overcome this, we introduce a structure consistency module that iteratively refines node features while preserving the global structural context. This joint design allows MolBridge to effectively learn both local and global interaction outperforms state-of-the-art baselines, achieving superior performance across long-tail and inductive scenarios. patterns, yielding robust representations across both frequent and rare DDI types. Extensive experiments on two benchmark datasets show that MolBridge consistently. These results demonstrate the advantages of fine-grained graph refinement in improving the accuracy, robustness, and mechanistic interpretability of DDI event prediction.This work contributes to Web Mining and Content Analysis by developing graph-based methods for mining and analyzing drug-drug interaction networks.
Graph Concept Bottleneck Models
Aug 19, 2025Concept Bottleneck Models (CBMs) provide explicit interpretations for deep neural networks through concepts and allow intervention with concepts to adjust final predictions. Existing CBMs assume concepts are conditionally independent given labels and isolated from each other, ignoring the hidden relationships among concepts. However, the set of concepts in CBMs often has an intrinsic structure where concepts are generally correlated: changing one concept will inherently impact its related concepts. To mitigate this limitation, we propose GraphCBMs: a new variant of CBM that facilitates concept relationships by constructing latent concept graphs, which can be combined with CBMs to enhance model performance while retaining their interpretability. Our experiment results on real-world image classification tasks demonstrate Graph CBMs offer the following benefits: (1) superior in image classification tasks while providing more concept structure information for interpretability; (2) able to utilize latent concept graphs for more effective interventions; and (3) robust in performance across different training and architecture settings.
ImageDDI: Image-enhanced Molecular Motif Sequence Representation for Drug-Drug Interaction Prediction
Aug 11, 2025To mitigate the potential adverse health effects of simultaneous multi-drug use, including unexpected side effects and interactions, accurately identifying and predicting drug-drug interactions (DDIs) is considered a crucial task in the field of deep learning. Although existing methods have demonstrated promising performance, they suffer from the bottleneck of limited functional motif-based representation learning, as DDIs are fundamentally caused by motif interactions rather than the overall drug structures. In this paper, we propose an Image-enhanced molecular motif sequence representation framework for \textbf{DDI} prediction, called ImageDDI, which represents a pair of drugs from both global and local structures. Specifically, ImageDDI tokenizes molecules into functional motifs. To effectively represent a drug pair, their motifs are combined into a single sequence and embedded using a transformer-based encoder, starting from the local structure representation. By leveraging the associations between drug pairs, ImageDDI further enhances the spatial representation of molecules using global molecular image information (e.g. texture, shadow, color, and planar spatial relationships). To integrate molecular visual information into functional motif sequence, ImageDDI employs Adaptive Feature Fusion, enhancing the generalization of ImageDDI by dynamically adapting the fusion process of feature representations. Experimental results on widely used datasets demonstrate that ImageDDI outperforms state-of-the-art methods. Moreover, extensive experiments show that ImageDDI achieved competitive performance in both 2D and 3D image-enhanced scenarios compared to other models.
The Budget AI Researcher and the Power of RAG Chains
Jun 14, 2025Navigating the vast and rapidly growing body of scientific literature is a formidable challenge for aspiring researchers. Current approaches to supporting research idea generation often rely on generic large language models (LLMs). While LLMs are effective at aiding comprehension and summarization, they often fall short in guiding users toward practical research ideas due to their limitations. In this study, we present a novel structural framework for research ideation. Our framework, The Budget AI Researcher, uses retrieval-augmented generation (RAG) chains, vector databases, and topic-guided pairing to recombine concepts from hundreds of machine learning papers. The system ingests papers from nine major AI conferences, which collectively span the vast subfields of machine learning, and organizes them into a hierarchical topic tree. It uses the tree to identify distant topic pairs, generate novel research abstracts, and refine them through iterative self-evaluation against relevant literature and peer reviews, generating and refining abstracts that are both grounded in real-world research and demonstrably interesting. Experiments using LLM-based metrics indicate that our method significantly improves the concreteness of generated research ideas relative to standard prompting approaches. Human evaluations further demonstrate a substantial enhancement in the perceived interestingness of the outputs. By bridging the gap between academic data and creative generation, the Budget AI Researcher offers a practical, free tool for accelerating scientific discovery and lowering the barrier for aspiring researchers. Beyond research ideation, this approach inspires solutions to the broader challenge of generating personalized, context-aware outputs grounded in evolving real-world knowledge.
FCOS: A Two-Stage Recoverable Model Pruning Framework for Automatic Modulation Recognition
May 27, 2025With the rapid development of wireless communications and the growing complexity of digital modulation schemes, traditional manual modulation recognition methods struggle to extract reliable signal features and meet real-time requirements in modern scenarios. Recently, deep learning based Automatic Modulation Recognition (AMR) approaches have greatly improved classification accuracy. However, their large model sizes and high computational demands hinder deployment on resource-constrained devices. Model pruning provides a general approach to reduce model complexity, but existing weight, channel, and layer pruning techniques each present a trade-off between compression rate, hardware acceleration, and accuracy preservation. To this end, in this paper, we introduce FCOS, a novel Fine-to-COarse two-Stage pruning framework that combines channel-level pruning with layer-level collapse diagnosis to achieve extreme compression, high performance and efficient inference. In the first stage of FCOS, hierarchical clustering and parameter fusion are applied to channel weights to achieve channel-level pruning. Then a Layer Collapse Diagnosis (LaCD) module uses linear probing to identify layer collapse and removes the collapsed layers due to high channel compression ratio. Experiments on multiple AMR benchmarks demonstrate that FCOS outperforms existing channel and layer pruning methods. Specifically, FCOS achieves 95.51% FLOPs reduction and 95.31% parameter reduction while still maintaining performance close to the original ResNet56, with only a 0.46% drop in accuracy on Sig2019-12. Code is available at https://github.com/yaolu-zjut/FCOS.