 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Shuffle: Block Reshuffling and Reversal Schemes for Stochastic Optimization
Mar 31, 2026Shuffling strategies for stochastic gradient descent (SGD), including incremental gradient, shuffle-once, and random reshuffling, are supported by rigorous convergence analyses for arbitrary within-epoch permutations. In particular, random reshuffling is known to improve optimization constants relative to cyclic and shuffle-once schemes. However, existing theory offers limited guidance on how to design new data-ordering schemes that further improve optimization constants or stability beyond random reshuffling. In this paper, we design a pipeline using a large language model (LLM)-guided program evolution framework to discover an effective shuffling rule for without-replacement SGD. Abstracting from this instance, we identify two fundamental structural components: block reshuffling and paired reversal. We analyze these components separately and show that block reshuffling strictly reduces prefix-gradient variance constants within the unified shuffling framework, yielding provable improvements over random reshuffling under mild conditions. Separately, we show that paired reversal symmetrizes the epoch map and cancels the leading order-dependent second-order term, reducing order sensitivity from quadratic to cubic in the step size. Numerical experiments with the discovered algorithm validate the theory and demonstrate consistent gains over standard shuffling schemes across convex and nonconvex benchmarks.
Revisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
Feb 06, 2026The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.
Graph Concept Bottleneck Models
Aug 19, 2025Concept Bottleneck Models (CBMs) provide explicit interpretations for deep neural networks through concepts and allow intervention with concepts to adjust final predictions. Existing CBMs assume concepts are conditionally independent given labels and isolated from each other, ignoring the hidden relationships among concepts. However, the set of concepts in CBMs often has an intrinsic structure where concepts are generally correlated: changing one concept will inherently impact its related concepts. To mitigate this limitation, we propose GraphCBMs: a new variant of CBM that facilitates concept relationships by constructing latent concept graphs, which can be combined with CBMs to enhance model performance while retaining their interpretability. Our experiment results on real-world image classification tasks demonstrate Graph CBMs offer the following benefits: (1) superior in image classification tasks while providing more concept structure information for interpretability; (2) able to utilize latent concept graphs for more effective interventions; and (3) robust in performance across different training and architecture settings.
Adjusted Shuffling SARAH: Advancing Complexity Analysis via Dynamic Gradient Weighting
Jun 14, 2025In this paper, we propose Adjusted Shuffling SARAH, a novel algorithm that integrates shuffling techniques with the well-known variance-reduced algorithm SARAH while dynamically adjusting the stochastic gradient weights in each update to enhance exploration. Our method achieves the best-known gradient complexity for shuffling variance reduction methods in a strongly convex setting. This result applies to any shuffling technique, which narrows the gap in the complexity analysis of variance reduction methods between uniform sampling and shuffling data. Furthermore, we introduce Inexact Adjusted Reshuffling SARAH, an inexact variant of Adjusted Shuffling SARAH that eliminates the need for full-batch gradient computations. This algorithm retains the same linear convergence rate as Adjusted Shuffling SARAH while showing an advantage in total complexity when the sample size is very large.
Probabilistic Federated Prompt-Tuning with Non-IID and Imbalanced Data
Feb 27, 2025Fine-tuning pre-trained models is a popular approach in machine learning for solving complex tasks with moderate data. However, fine-tuning the entire pre-trained model is ineffective in federated data scenarios where local data distributions are diversely skewed. To address this, we explore integrating federated learning with a more effective prompt-tuning method, optimizing for a small set of input prefixes to reprogram the pre-trained model's behavior. Our approach transforms federated learning into a distributed set modeling task, aggregating diverse sets of prompts to globally fine-tune the pre-trained model. We benchmark various baselines based on direct adaptations of existing federated model aggregation techniques and introduce a new probabilistic prompt aggregation method that substantially outperforms these baselines. Our reported results on a variety of computer vision datasets confirm that the proposed method is most effective to combat extreme data heterogeneity in federated learning.
Abstracted Shapes as Tokens -- A Generalizable and Interpretable Model for Time-series Classification
Nov 01, 2024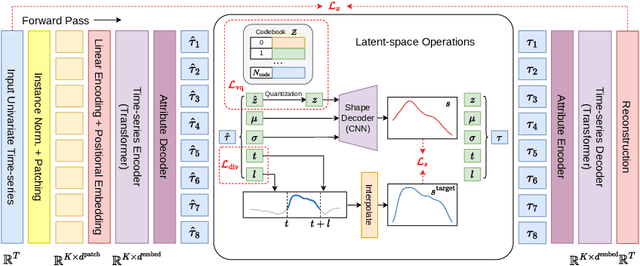
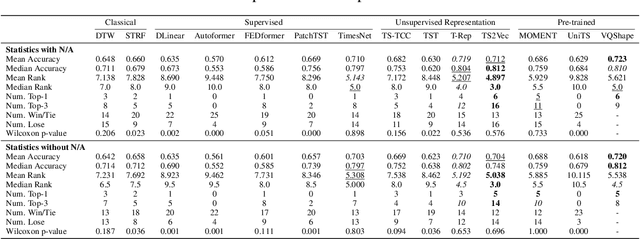
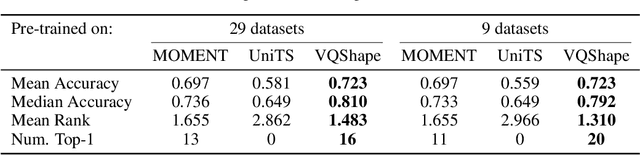
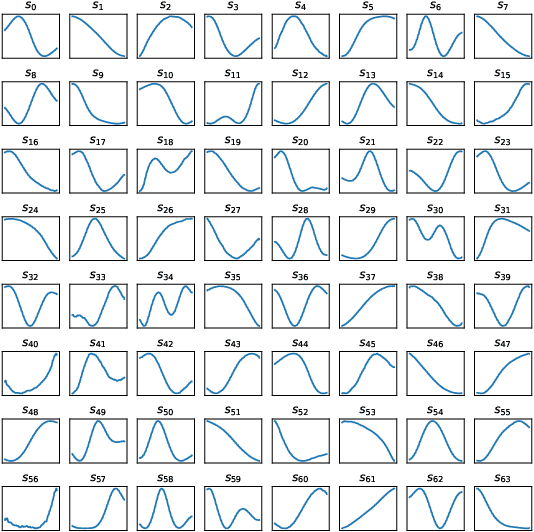
In time-series analysis, many recent works seek to provide a unified view and representation for time-series across multiple domains, leading to the development of foundation models for time-series data. Despite diverse modeling techniques, existing models are black boxes and fail to provide insights and explanations about their representations. In this paper, we present VQShape, a pre-trained, generalizable, and interpretable model for time-series representation learning and classification. By introducing a novel representation for time-series data, we forge a connection between the latent space of VQShape and shape-level features. Using vector quantization, we show that time-series from different domains can be described using a unified set of low-dimensional codes, where each code can be represented as an abstracted shape in the time domain. On classification tasks, we show that the representations of VQShape can be utilized to build interpretable classifiers, achieving comparable performance to specialist models. Additionally, in zero-shot learning, VQShape and its codebook can generalize to previously unseen datasets and domains that are not included in the pre-training process. The code and pre-trained weights are available at https://github.com/YunshiWen/VQShape.
Shuffling Gradient-Based Methods for Nonconvex-Concave Minimax Optimization
Oct 29, 2024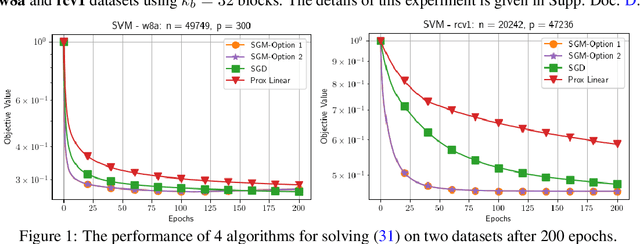



This paper aims at developing novel shuffling gradient-based methods for tackling two classes of minimax problems: nonconvex-linear and nonconvex-strongly concave settings. The first algorithm addresses the nonconvex-linear minimax model and achieves the state-of-the-art oracle complexity typically observed in nonconvex optimization. It also employs a new shuffling estimator for the "hyper-gradient", departing from standard shuffling techniques in optimization. The second method consists of two variants: semi-shuffling and full-shuffling schemes. These variants tackle the nonconvex-strongly concave minimax setting. We establish their oracle complexity bounds under standard assumptions, which, to our best knowledge, are the best-known for this specific setting. Numerical examples demonstrate the performance of our algorithms and compare them with two other methods. Our results show that the new methods achieve comparable performance with SGD, supporting the potential of incorporating shuffling strategies into minimax algorithms.
* 45 pages, 5 figures (38th Conference on Neural Information Processing Systems (NeurIPS 2024))
Guaranteeing Conservation Laws with Projection in Physics-Informed Neural Networks
Oct 22, 2024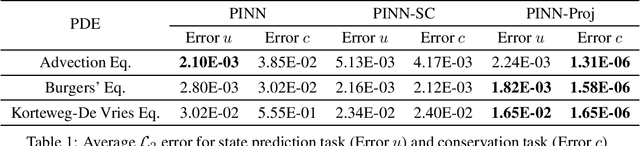
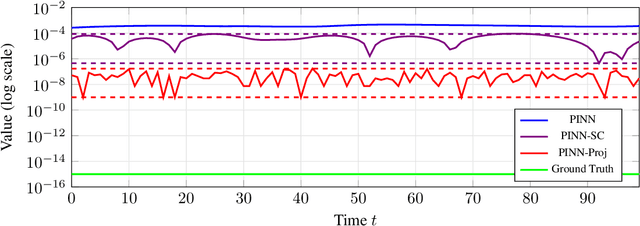
Physics-informed neural networks (PINNs) incorporate physical laws into their training to efficiently solve partial differential equations (PDEs) with minimal data. However, PINNs fail to guarantee adherence to conservation laws, which are also important to consider in modeling physical systems. To address this, we proposed PINN-Proj, a PINN-based model that uses a novel projection method to enforce conservation laws. We found that PINN-Proj substantially outperformed PINN in conserving momentum and lowered prediction error by three to four orders of magnitude from the best benchmark tested. PINN-Proj also performed marginally better in the separate task of state prediction on three PDE datasets.
TabularFM: An Open Framework For Tabular Foundational Models
Jun 18, 2024Foundational models (FMs), pretrained on extensive datasets using self-supervised techniques, are capable of learning generalized patterns from large amounts of data. This reduces the need for extensive labeled datasets for each new task, saving both time and resources by leveraging the broad knowledge base established during pretraining. Most research on FMs has primarily focused on unstructured data, such as text and images, or semi-structured data, like time-series. However, there has been limited attention to structured data, such as tabular data, which, despite its prevalence, remains under-studied due to a lack of clean datasets and insufficient research on the transferability of FMs for various tabular data tasks. In response to this gap, we introduce a framework called TabularFM, which incorporates state-of-the-art methods for developing FMs specifically for tabular data. This includes variations of neural architectures such as GANs, VAEs, and Transformers. We have curated a million of tabular datasets and released cleaned versions to facilitate the development of tabular FMs. We pretrained FMs on this curated data, benchmarked various learning methods on these datasets, and released the pretrained models along with leaderboards for future comparative studies. Our fully open-sourced system provides a comprehensive analysis of the transferability of tabular FMs. By releasing these datasets, pretrained models, and leaderboards, we aim to enhance the validity and usability of tabular FMs in the near future.
Shuffling Momentum Gradient Algorithm for Convex Optimization
Mar 05, 2024The Stochastic Gradient Descent method (SGD) and its stochastic variants have become methods of choice for solving finite-sum optimization problems arising from machine learning and data science thanks to their ability to handle large-scale applications and big datasets. In the last decades, researchers have made substantial effort to study the theoretical performance of SGD and its shuffling variants. However, only limited work has investigated its shuffling momentum variants, including shuffling heavy-ball momentum schemes for non-convex problems and Nesterov's momentum for convex settings. In this work, we extend the analysis of the shuffling momentum gradient method developed in [Tran et al (2021)] to both finite-sum convex and strongly convex optimization problems. We provide the first analysis of shuffling momentum-based methods for the strongly convex setting, attaining a convergence rate of $O(1/nT^2)$, where $n$ is the number of samples and $T$ is the number of training epochs. Our analysis is a state-of-the-art, matching the best rates of existing shuffling stochastic gradient algorithms in the literature.