 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlow-Fast Inference: Training-Free Inference Acceleration via Within-Sentence Support Stability
Mar 12, 2026Long-context autoregressive decoding remains expensive because each decoding step must repeatedly process a growing history. We observe a consistent pattern during decoding: within a sentence, and more generally within a short semantically coherent span, the dominant attention support often remains largely stable. Motivated by this observation, we propose Slow-Fast Inference (SFI), a training-free decoding framework that decouples generation into frequent low-cost fast steps and occasional dense-attention slow steps. Fast steps reuse a compact sparse memory for efficient decoding. Slow steps are triggered near semantic boundaries. At slow steps, the model revisits the broader context and uses the Selector to refresh the selected memory for subsequent fast steps. Across the evaluated context lengths, SFI delivers approximately $1.6\times$--$14.4\times$ higher decoding throughput while generally maintaining quality on par with the full-KV baseline across long-context and long-CoT settings. Because SFI is training-free and applies directly to existing checkpoints, it offers a practical path to reducing inference cost for contemporary autoregressive reasoning models in long-context, long-horizon, and agentic workloads.
Towards Understanding Why Data Augmentation Improves Generalization
Feb 13, 2025
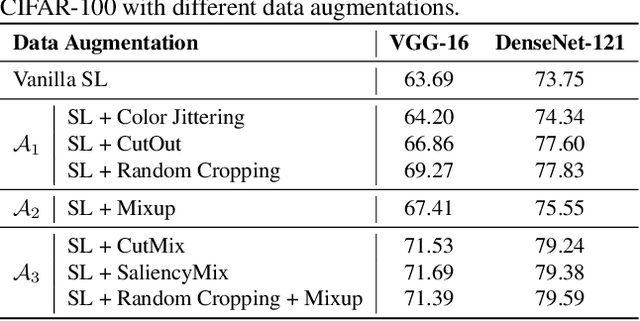


Data augmentation is a cornerstone technique in deep learning, widely used to improve model generalization. Traditional methods like random cropping and color jittering, as well as advanced techniques such as CutOut, Mixup, and CutMix, have achieved notable success across various domains. However, the mechanisms by which data augmentation improves generalization remain poorly understood, and existing theoretical analyses typically focus on individual techniques without a unified explanation. In this work, we present a unified theoretical framework that elucidates how data augmentation enhances generalization through two key effects: partial semantic feature removal and feature mixing. Partial semantic feature removal reduces the model's reliance on individual feature, promoting diverse feature learning and better generalization. Feature mixing, by scaling down original semantic features and introducing noise, increases training complexity, driving the model to develop more robust features. Advanced methods like CutMix integrate both effects, achieving complementary benefits. Our theoretical insights are further supported by experimental results, validating the effectiveness of this unified perspective.
Memory-Efficient 4-bit Preconditioned Stochastic Optimization
Dec 14, 2024Preconditioned stochastic optimization algorithms, exemplified by Shampoo, have demonstrated superior performance over first-order optimizers, providing both theoretical advantages in convergence rates and practical improvements in large-scale neural network training. However, they incur substantial memory overhead due to the storage demands of non-diagonal preconditioning matrices. To address this, we introduce 4-bit quantization for Shampoo's preconditioners. We introduced two key methods: First, we apply Cholesky decomposition followed by quantization of the Cholesky factors, reducing memory usage by leveraging their lower triangular structure while preserving symmetry and positive definiteness to minimize information loss. To our knowledge, this is the first quantization approach applied to Cholesky factors of preconditioners. Second, we incorporate error feedback in the quantization process, efficiently storing Cholesky factors and error states in the lower and upper triangular parts of the same matrix. Through extensive experiments, we demonstrate that combining Cholesky quantization with error feedback enhances memory efficiency and algorithm performance in large-scale deep-learning tasks. Theoretically, we also provide convergence proofs for quantized Shampoo under both smooth and non-smooth stochastic optimization settings.
Towards Understanding Why FixMatch Generalizes Better Than Supervised Learning
Oct 15, 2024



Semi-supervised learning (SSL), exemplified by FixMatch (Sohn et al., 2020), has shown significant generalization advantages over supervised learning (SL), particularly in the context of deep neural networks (DNNs). However, it is still unclear, from a theoretical standpoint, why FixMatch-like SSL algorithms generalize better than SL on DNNs. In this work, we present the first theoretical justification for the enhanced test accuracy observed in FixMatch-like SSL applied to DNNs by taking convolutional neural networks (CNNs) on classification tasks as an example. Our theoretical analysis reveals that the semantic feature learning processes in FixMatch and SL are rather different. In particular, FixMatch learns all the discriminative features of each semantic class, while SL only randomly captures a subset of features due to the well-known lottery ticket hypothesis. Furthermore, we show that our analysis framework can be applied to other FixMatch-like SSL methods, e.g., FlexMatch, FreeMatch, Dash, and SoftMatch. Inspired by our theoretical analysis, we develop an improved variant of FixMatch, termed Semantic-Aware FixMatch (SA-FixMatch). Experimental results corroborate our theoretical findings and the enhanced generalization capability of SA-FixMatch.
Optimization Hyper-parameter Laws for Large Language Models
Sep 07, 2024



Large Language Models have driven significant AI advancements, yet their training is resource-intensive and highly sensitive to hyper-parameter selection. While scaling laws provide valuable guidance on model size and data requirements, they fall short in choosing dynamic hyper-parameters, such as learning-rate (LR) schedules, that evolve during training. To bridge this gap, we present Optimization Hyper-parameter Laws (Opt-Laws), a framework that effectively captures the relationship between hyper-parameters and training outcomes, enabling the pre-selection of potential optimal schedules. Grounded in stochastic differential equations, Opt-Laws introduce novel mathematical interpretability and offer a robust theoretical foundation for some popular LR schedules. Our extensive validation across diverse model sizes and data scales demonstrates Opt-Laws' ability to accurately predict training loss and identify optimal LR schedule candidates in pre-training, continual training, and fine-tuning scenarios. This approach significantly reduces computational costs while enhancing overall model performance.
LoCo: Low-Bit Communication Adaptor for Large-scale Model Training
Jul 05, 2024To efficiently train large-scale models, low-bit gradient communication compresses full-precision gradients on local GPU nodes into low-precision ones for higher gradient synchronization efficiency among GPU nodes. However, it often degrades training quality due to compression information loss. To address this, we propose the Low-bit Communication Adaptor (LoCo), which compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality. Specifically, LoCo designs a moving average of historical compensation errors to stably estimate concurrent compression error and then adopts it to compensate for the concurrent gradient compression, yielding a less lossless compression. This mechanism allows it to be compatible with general optimizers like Adam and sharding strategies like FSDP. Theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results show that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, e.g., improving Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
Vertex Exchange Method for a Class of Quadratic Programming Problems
Jul 03, 2024A vertex exchange method is proposed for solving the strongly convex quadratic program subject to the generalized simplex constraint. We conduct rigorous convergence analysis for the proposed algorithm and demonstrate its essential roles in solving some important classes of constrained convex optimization. To get a feasible initial point to execute the algorithm, we also present and analyze a highly efficient semismooth Newton method for computing the projection onto the generalized simplex. The excellent practical performance of the proposed algorithms is demonstrated by a set of extensive numerical experiments. Our theoretical and numerical results further motivate the potential applications of the considered model and the proposed algorithms.
Developing Lagrangian-based Methods for Nonsmooth Nonconvex Optimization
Apr 15, 2024In this paper, we consider the minimization of a nonsmooth nonconvex objective function $f(x)$ over a closed convex subset $\mathcal{X}$ of $\mathbb{R}^n$, with additional nonsmooth nonconvex constraints $c(x) = 0$. We develop a unified framework for developing Lagrangian-based methods, which takes a single-step update to the primal variables by some subgradient methods in each iteration. These subgradient methods are ``embedded'' into our framework, in the sense that they are incorporated as black-box updates to the primal variables. We prove that our proposed framework inherits the global convergence guarantees from these embedded subgradient methods under mild conditions. In addition, we show that our framework can be extended to solve constrained optimization problems with expectation constraints. Based on the proposed framework, we show that a wide range of existing stochastic subgradient methods, including the proximal SGD, proximal momentum SGD, and proximal ADAM, can be embedded into Lagrangian-based methods. Preliminary numerical experiments on deep learning tasks illustrate that our proposed framework yields efficient variants of Lagrangian-based methods with convergence guarantees for nonconvex nonsmooth constrained optimization problems.
An Inexact Halpern Iteration with Application to Distributionally Robust Optimization
Feb 12, 2024The Halpern iteration for solving monotone inclusion problems has gained increasing interests in recent years due to its simple form and appealing convergence properties. In this paper, we investigate the inexact variants of the scheme in both deterministic and stochastic settings. We conduct extensive convergence analysis and show that by choosing the inexactness tolerances appropriately, the inexact schemes admit an $O(k^{-1})$ convergence rate in terms of the (expected) residue norm. Our results relax the state-of-the-art inexactness conditions employed in the literature while sharing the same competitive convergence properties. We then demonstrate how the proposed methods can be applied for solving two classes of data-driven Wasserstein distributionally robust optimization problems that admit convex-concave min-max optimization reformulations. We highlight its capability of performing inexact computations for distributionally robust learning with stochastic first-order methods.
On Partial Optimal Transport: Revising the Infeasibility of Sinkhorn and Efficient Gradient Methods
Dec 22, 2023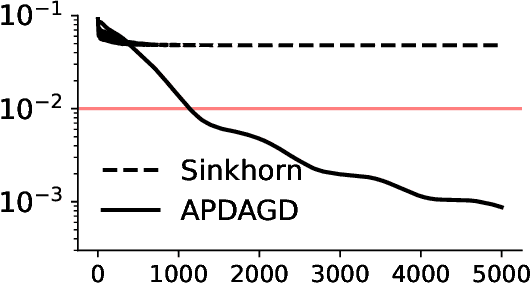

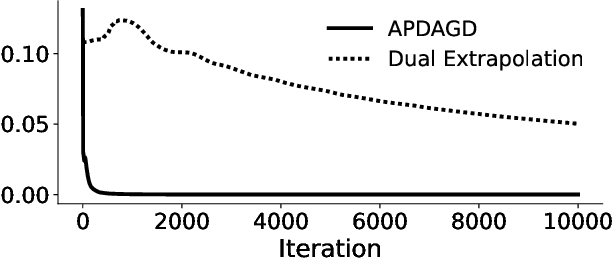
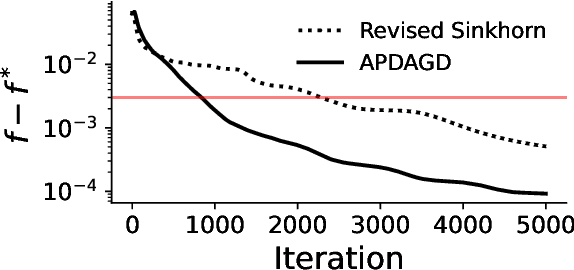
This paper studies the Partial Optimal Transport (POT) problem between two unbalanced measures with at most $n$ supports and its applications in various AI tasks such as color transfer or domain adaptation. There is hence the need for fast approximations of POT with increasingly large problem sizes in arising applications. We first theoretically and experimentally investigate the infeasibility of the state-of-the-art Sinkhorn algorithm for POT due to its incompatible rounding procedure, which consequently degrades its qualitative performance in real world applications like point-cloud registration. To this end, we propose a novel rounding algorithm for POT, and then provide a feasible Sinkhorn procedure with a revised computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon^4)$. Our rounding algorithm also permits the development of two first-order methods to approximate the POT problem. The first algorithm, Adaptive Primal-Dual Accelerated Gradient Descent (APDAGD), finds an $\varepsilon$-approximate solution to the POT problem in $\mathcal{\widetilde O}(n^{2.5}/\varepsilon)$, which is better in $\varepsilon$ than revised Sinkhorn. The second method, Dual Extrapolation, achieves the computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon)$, thereby being the best in the literature. We further demonstrate the flexibility of POT compared to standard OT as well as the practicality of our algorithms on real applications where two marginal distributions are unbalanced.