 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
May 13, 2026Voice agents, artificial intelligence systems that conduct spoken conversations to complete tasks, are increasingly deployed across enterprise applications. However, no existing benchmark jointly addresses two core evaluation challenges: generating realistic simulated conversations, and measuring quality across the full scope of voice-specific failure modes. We present EVA-Bench, an end-to-end evaluation framework that addresses both. On the simulation side, EVA-Bench orchestrates bot-to-bot audio conversations over dynamic multi-turn dialogues, with automatic simulation validation that detects user simulator error and appropriately regenerates conversations before scoring. On the measurement side, EVA-Bench introduces two composite metrics: EVA-A (Accuracy), capturing task completion, faithfulness, and audio-level speech fidelity; and EVA-X (Experience), capturing conversation progression, spoken conciseness, and turn-taking timing. Both metrics apply to different agent architectures, enabling direct cross-architecture comparison. EVA-Bench includes 213 scenarios across three enterprise domains, a controlled perturbation suite for accent and noise robustness, and pass@1, pass@k, pass^k measurements that distinguish peak from reliable capability. Across 12 systems spanning all three architectures, we find: (1) no system simultaneously exceeds 0.5 on both EVA-A pass@1 and EVA-X pass@1; (2) peak and reliable performance diverge substantially (median pass@k - pass^k gap of 0.44 on EVA-A); and (3) accent and noise perturbations expose substantial robustness gaps, with effects varying across architectures, systems, and metrics (mean up to 0.314). We release the full framework, evaluation suite, and benchmark data under an open-source license.
Pedestrian Crossing Intent Prediction via Psychological Features and Transformer Fusion
Mar 20, 2026Pedestrian intention prediction needs to be accurate for autonomous vehicles to navigate safely in urban environments. We present a lightweight, socially informed architecture for pedestrian intention prediction. It fuses four behavioral streams (attention, position, situation, and interaction) using highway encoders, a compact 4-token Transformer, and global self-attention pooling. To quantify uncertainty, we incorporate two complementary heads: a variational bottleneck whose KL divergence captures epistemic uncertainty, and a Mahalanobis distance detector that identifies distributional shift. Together, these components yield calibrated probabilities and actionable risk scores without compromising efficiency. On the PSI 1.0 benchmark, our model outperforms recent vision language models by achieving 0.9 F1, 0.94 AUC-ROC, and 0.78 MCC by using only structured, interpretable features. On the more diverse PSI 2.0 dataset, where, to the best of our knowledge, no prior results exist, we establish a strong initial baseline of 0.78 F1 and 0.79 AUC-ROC. Selective prediction based on Mahalanobis scores increases test accuracy by up to 0.4 percentage points at 80% coverage. Qualitative attention heatmaps further show how the model shifts its cross-stream focus under ambiguity. The proposed approach is modality-agnostic, easy to integrate with vision language pipelines, and suitable for risk-aware intent prediction on resource-constrained platforms.
Graph-DPEP: Decomposed Plug and Ensemble Play for Few-Shot Document Relation Extraction with Graph-of-Thoughts Reasoning
Nov 05, 2024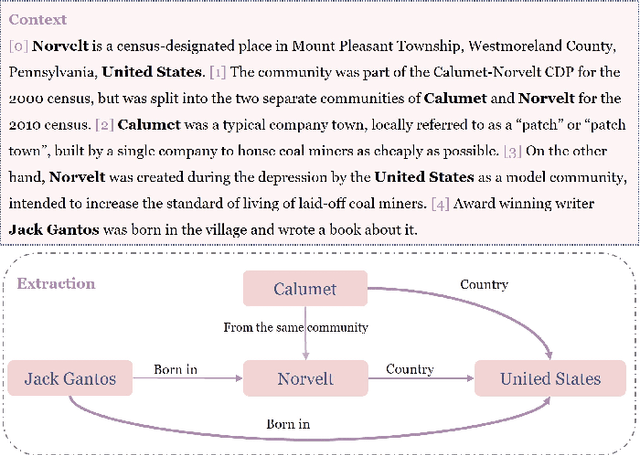

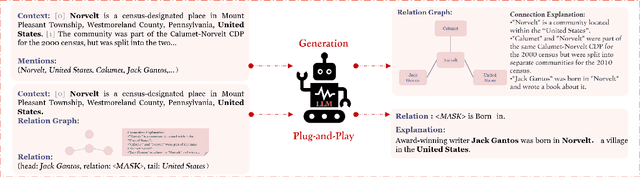
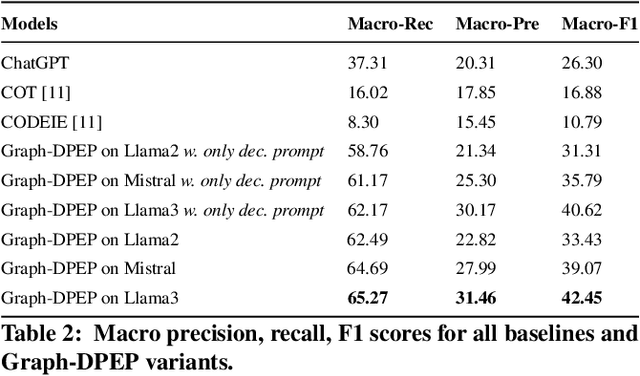
Large language models (LLMs) pre-trained on massive corpora have demonstrated impressive few-shot learning capability on many NLP tasks. Recasting an NLP task into a text-to-text generation task is a common practice so that generative LLMs can be prompted to resolve it. However, performing document-level relation extraction (DocRE) tasks with generative LLM models is still challenging due to the structured output format of DocRE, which complicates the conversion to plain text. Limited information available in few-shot samples and prompt instructions induce further difficulties and challenges in relation extraction for mentioned entities in a document. In this paper, we represent the structured output as a graph-style triplet rather than natural language expressions and leverage generative LLMs for the DocRE task. Our approach, the Graph-DPEP framework is grounded in the reasoning behind triplet explanation thoughts presented in natural language. In this framework, we first introduce a ``decomposed-plug" method for performing the generation from LLMs over prompts with type-space decomposition to alleviate the burden of distinguishing all relation types. Second, we employ a verifier for calibrating the generation and identifying overlooked query entity pairs. Third, we develop "ensemble-play", reapplying generation on the entire type list by leveraging the reasoning thoughts embedded in a sub-graph associated with the missing query pair to address the missingness issue. Through extensive comparisons with existing prompt techniques and alternative Language Models (LLMs), our framework demonstrates superior performance on publicly available benchmarks in experiments.
CORI: CJKV Benchmark with Romanization Integration -- A step towards Cross-lingual Transfer Beyond Textual Scripts
Apr 19, 2024Naively assuming English as a source language may hinder cross-lingual transfer for many languages by failing to consider the importance of language contact. Some languages are more well-connected than others, and target languages can benefit from transferring from closely related languages; for many languages, the set of closely related languages does not include English. In this work, we study the impact of source language for cross-lingual transfer, demonstrating the importance of selecting source languages that have high contact with the target language. We also construct a novel benchmark dataset for close contact Chinese-Japanese-Korean-Vietnamese (CJKV) languages to further encourage in-depth studies of language contact. To comprehensively capture contact between these languages, we propose to integrate Romanized transcription beyond textual scripts via Contrastive Learning objectives, leading to enhanced cross-lingual representations and effective zero-shot cross-lingual transfer.
On Partial Optimal Transport: Revising the Infeasibility of Sinkhorn and Efficient Gradient Methods
Dec 22, 2023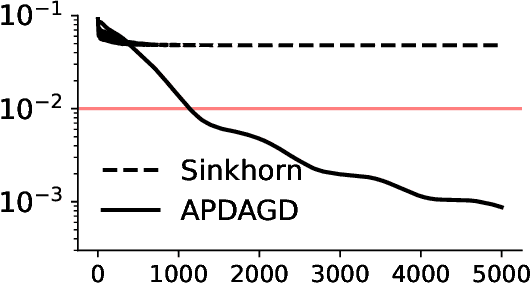

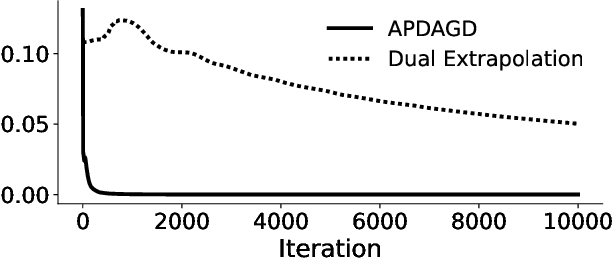
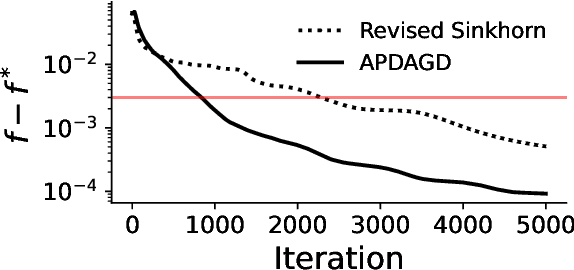
This paper studies the Partial Optimal Transport (POT) problem between two unbalanced measures with at most $n$ supports and its applications in various AI tasks such as color transfer or domain adaptation. There is hence the need for fast approximations of POT with increasingly large problem sizes in arising applications. We first theoretically and experimentally investigate the infeasibility of the state-of-the-art Sinkhorn algorithm for POT due to its incompatible rounding procedure, which consequently degrades its qualitative performance in real world applications like point-cloud registration. To this end, we propose a novel rounding algorithm for POT, and then provide a feasible Sinkhorn procedure with a revised computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon^4)$. Our rounding algorithm also permits the development of two first-order methods to approximate the POT problem. The first algorithm, Adaptive Primal-Dual Accelerated Gradient Descent (APDAGD), finds an $\varepsilon$-approximate solution to the POT problem in $\mathcal{\widetilde O}(n^{2.5}/\varepsilon)$, which is better in $\varepsilon$ than revised Sinkhorn. The second method, Dual Extrapolation, achieves the computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon)$, thereby being the best in the literature. We further demonstrate the flexibility of POT compared to standard OT as well as the practicality of our algorithms on real applications where two marginal distributions are unbalanced.
CoF-CoT: Enhancing Large Language Models with Coarse-to-Fine Chain-of-Thought Prompting for Multi-domain NLU Tasks
Oct 23, 2023

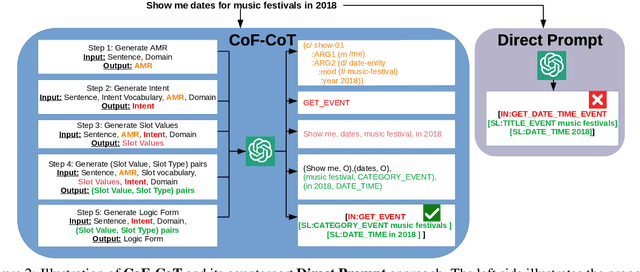
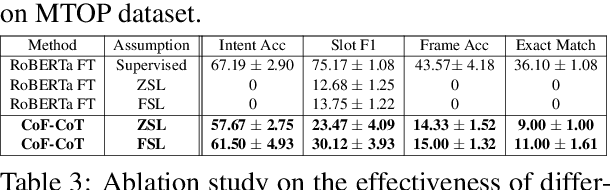
While Chain-of-Thought prompting is popular in reasoning tasks, its application to Large Language Models (LLMs) in Natural Language Understanding (NLU) is under-explored. Motivated by multi-step reasoning of LLMs, we propose Coarse-to-Fine Chain-of-Thought (CoF-CoT) approach that breaks down NLU tasks into multiple reasoning steps where LLMs can learn to acquire and leverage essential concepts to solve tasks from different granularities. Moreover, we propose leveraging semantic-based Abstract Meaning Representation (AMR) structured knowledge as an intermediate step to capture the nuances and diverse structures of utterances, and to understand connections between their varying levels of granularity. Our proposed approach is demonstrated effective in assisting the LLMs adapt to the multi-grained NLU tasks under both zero-shot and few-shot multi-domain settings.
Slot Induction via Pre-trained Language Model Probing and Multi-level Contrastive Learning
Aug 09, 2023
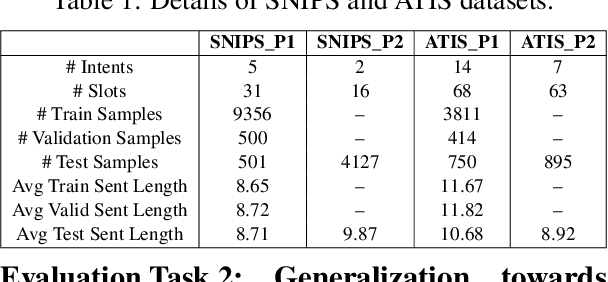


Recent advanced methods in Natural Language Understanding for Task-oriented Dialogue (TOD) Systems (e.g., intent detection and slot filling) require a large amount of annotated data to achieve competitive performance. In reality, token-level annotations (slot labels) are time-consuming and difficult to acquire. In this work, we study the Slot Induction (SI) task whose objective is to induce slot boundaries without explicit knowledge of token-level slot annotations. We propose leveraging Unsupervised Pre-trained Language Model (PLM) Probing and Contrastive Learning mechanism to exploit (1) unsupervised semantic knowledge extracted from PLM, and (2) additional sentence-level intent label signals available from TOD. Our approach is shown to be effective in SI task and capable of bridging the gaps with token-level supervised models on two NLU benchmark datasets. When generalized to emerging intents, our SI objectives also provide enhanced slot label representations, leading to improved performance on the Slot Filling tasks.
Enhancing Cross-lingual Transfer via Phonemic Transcription Integration
Jul 10, 2023Previous cross-lingual transfer methods are restricted to orthographic representation learning via textual scripts. This limitation hampers cross-lingual transfer and is biased towards languages sharing similar well-known scripts. To alleviate the gap between languages from different writing scripts, we propose PhoneXL, a framework incorporating phonemic transcriptions as an additional linguistic modality beyond the traditional orthographic transcriptions for cross-lingual transfer. Particularly, we propose unsupervised alignment objectives to capture (1) local one-to-one alignment between the two different modalities, (2) alignment via multi-modality contexts to leverage information from additional modalities, and (3) alignment via multilingual contexts where additional bilingual dictionaries are incorporated. We also release the first phonemic-orthographic alignment dataset on two token-level tasks (Named Entity Recognition and Part-of-Speech Tagging) among the understudied but interconnected Chinese-Japanese-Korean-Vietnamese (CJKV) languages. Our pilot study reveals phonemic transcription provides essential information beyond the orthography to enhance cross-lingual transfer and bridge the gap among CJKV languages, leading to consistent improvements on cross-lingual token-level tasks over orthographic-based multilingual PLMs.
MANDO: Multi-Level Heterogeneous Graph Embeddings for Fine-Grained Detection of Smart Contract Vulnerabilities
Aug 28, 2022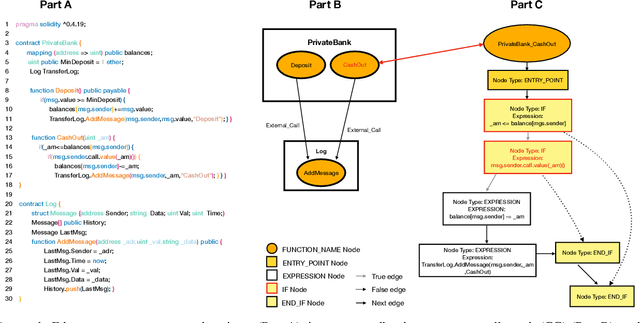
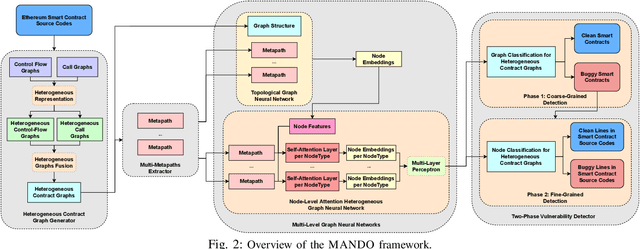
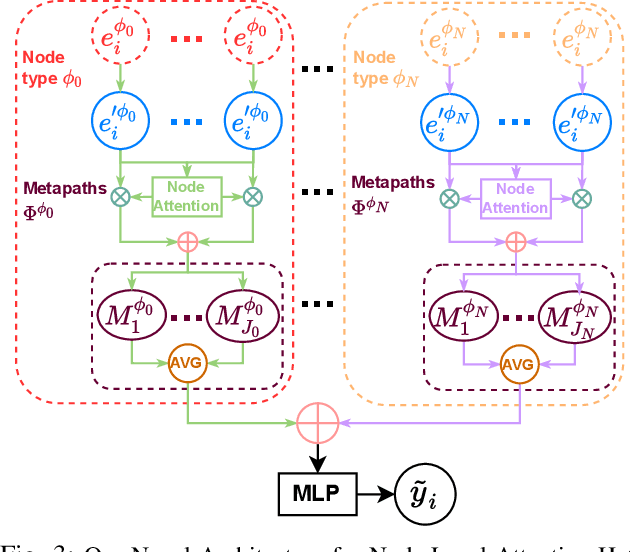

Learning heterogeneous graphs consisting of different types of nodes and edges enhances the results of homogeneous graph techniques. An interesting example of such graphs is control-flow graphs representing possible software code execution flows. As such graphs represent more semantic information of code, developing techniques and tools for such graphs can be highly beneficial for detecting vulnerabilities in software for its reliability. However, existing heterogeneous graph techniques are still insufficient in handling complex graphs where the number of different types of nodes and edges is large and variable. This paper concentrates on the Ethereum smart contracts as a sample of software codes represented by heterogeneous contract graphs built upon both control-flow graphs and call graphs containing different types of nodes and links. We propose MANDO, a new heterogeneous graph representation to learn such heterogeneous contract graphs' structures. MANDO extracts customized metapaths, which compose relational connections between different types of nodes and their neighbors. Moreover, it develops a multi-metapath heterogeneous graph attention network to learn multi-level embeddings of different types of nodes and their metapaths in the heterogeneous contract graphs, which can capture the code semantics of smart contracts more accurately and facilitate both fine-grained line-level and coarse-grained contract-level vulnerability detection. Our extensive evaluation of large smart contract datasets shows that MANDO improves the vulnerability detection results of other techniques at the coarse-grained contract level. More importantly, it is the first learning-based approach capable of identifying vulnerabilities at the fine-grained line-level, and significantly improves the traditional code analysis-based vulnerability detection approaches by 11.35% to 70.81% in terms of F1-score.
On the Convergence of Gradient Extrapolation Methods for Unbalanced Optimal Transport
Feb 08, 2022
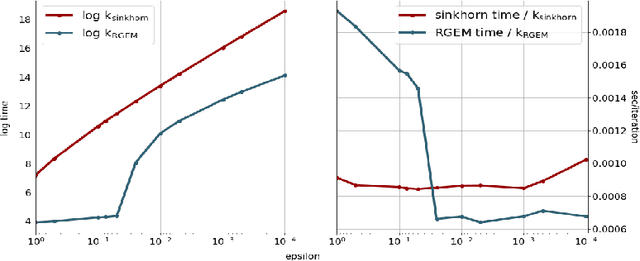
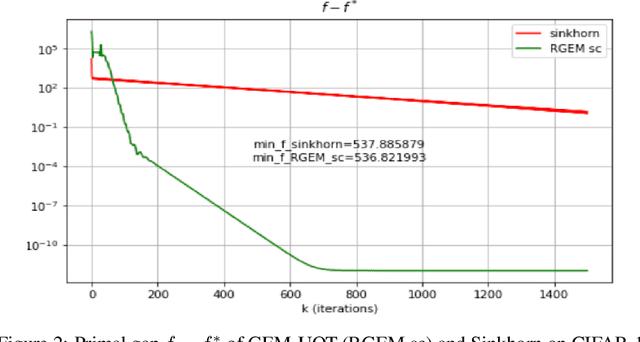
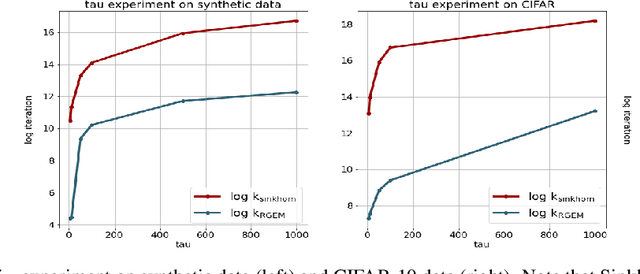
We study the Unbalanced Optimal Transport (UOT) between two measures of possibly different masses with at most $n$ components, where marginal constraints of the standard Optimal Transport (OT) are relaxed via Kullback-Leibler divergence with regularization factor $\tau$. We propose a novel algorithm based on Gradient Extrapolation Method (GEM-UOT) to find an $\varepsilon$-approximate solution to the UOT problem in $O\big( \kappa n^2 \log\big(\frac{\tau n}{\varepsilon}\big) \big)$, where $\kappa$ is the condition number depending on only the two input measures. Compared to the only known complexity ${O}\big(\tfrac{\tau n^2 \log(n)}{\varepsilon} \log\big(\tfrac{\log(n)}{{\varepsilon}}\big)\big)$ for solving the UOT problem via the Sinkhorn algorithm, ours is better in $\varepsilon$ and lifts Sinkhorn's linear dependence on $\tau$, which hindered its practicality to approximate the standard OT via UOT. Our proof technique is based on a novel dual formulation of the squared $\ell_2$-norm regularized UOT objective, which is of independent interest and also leads to a new characterization of approximation error between UOT and OT in terms of both the transportation plan and transport distance. To this end, we further present an algorithm, based on GEM-UOT with fine tuned $\tau$ and a post-process projection step, to find an $\varepsilon$-approximate solution to the standard OT problem in $O\big( \kappa n^2 \log\big(\frac{ n}{\varepsilon}\big) \big)$, which is a new complexity in the literature of OT. Extensive experiments on synthetic and real datasets validate our theories and demonstrate the favorable performance of our methods in practice.