 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Truth-Aligned Uncertainty Estimation in Large Language Models
Apr 01, 2026Uncertainty estimation (UE) aims to detect hallucinated outputs of large language models (LLMs) to improve their reliability. However, UE metrics often exhibit unstable performance across configurations, which significantly limits their applicability. In this work, we formalise this phenomenon as proxy failure, since most UE metrics originate from model behaviour, rather than being explicitly grounded in the factual correctness of LLM outputs. With this, we show that UE metrics become non-discriminative precisely in low-information regimes. To alleviate this, we propose Truth AnChoring (TAC), a post-hoc calibration method to remedy UE metrics, by mapping the raw scores to truth-aligned scores. Even with noisy and few-shot supervision, our TAC can support the learning of well-calibrated uncertainty estimates, and presents a practical calibration protocol. Our findings highlight the limitations of treating heuristic UE metrics as direct indicators of truth uncertainty, and position our TAC as a necessary step toward more reliable uncertainty estimation for LLMs. The code repository is available at https://github.com/ponhvoan/TruthAnchor/.
Analysing LLM Persona Generation and Fairness Interpretation in Polarised Geopolitical Contexts
Mar 24, 2026Large language models (LLMs) are increasingly utilised for social simulation and persona generation, necessitating an understanding of how they represent geopolitical identities. In this paper, we analyse personas generated for Palestinian and Israeli identities by five popular LLMs across 640 experimental conditions, varying context (war vs non-war) and assigned roles. We observe significant distributional patterns in the generated attributes: Palestinian profiles in war contexts are frequently associated with lower socioeconomic status and survival-oriented roles, whereas Israeli profiles predominantly retain middle-class status and specialised professional attributes. When prompted with explicit instructions to avoid harmful assumptions, models exhibit diverse distributional changes, e.g., marked increases in non-binary gender inferences or a convergence toward generic occupational roles (e.g., "student"), while the underlying socioeconomic distinctions often remain. Furthermore, analysis of reasoning traces reveals an interesting dynamics between model reasoning and generation: while rationales consistently mention fairness-related concepts, the final generated personas follow the aforementioned diverse distributional changes. These findings illustrate a picture of how models interpret geopolitical contexts, while suggesting that they process fairness and adjust in varied ways; there is no consistent, direct translation of fairness concepts into representative outcomes.
Is External Information Useful for Stance Detection with LLMs?
Jul 02, 2025In the stance detection task, a text is classified as either favorable, opposing, or neutral towards a target. Prior work suggests that the use of external information, e.g., excerpts from Wikipedia, improves stance detection performance. However, whether or not such information can benefit large language models (LLMs) remains an unanswered question, despite their wide adoption in many reasoning tasks. In this study, we conduct a systematic evaluation on how Wikipedia and web search external information can affect stance detection across eight LLMs and in three datasets with 12 targets. Surprisingly, we find that such information degrades performance in most cases, with macro F1 scores dropping by up to 27.9\%. We explain this through experiments showing LLMs' tendency to align their predictions with the stance and sentiment of the provided information rather than the ground truth stance of the given text. We also find that performance degradation persists with chain-of-thought prompting, while fine-tuning mitigates but does not fully eliminate it. Our findings, in contrast to previous literature on BERT-based systems which suggests that external information enhances performance, highlight the risks of information biases in LLM-based stance classifiers. Code is available at https://github.com/ngqm/acl2025-stance-detection.
On Partial Optimal Transport: Revising the Infeasibility of Sinkhorn and Efficient Gradient Methods
Dec 22, 2023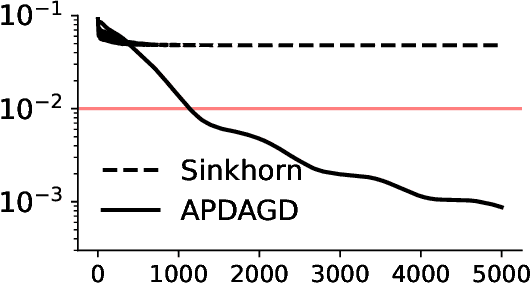

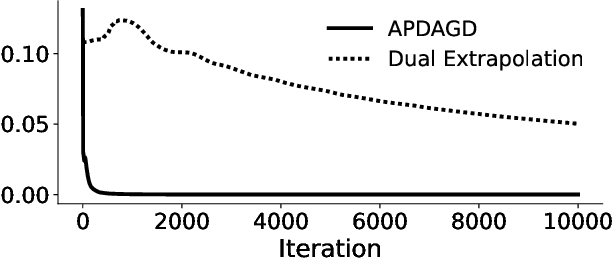
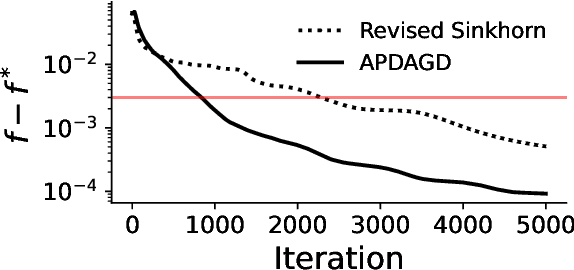
This paper studies the Partial Optimal Transport (POT) problem between two unbalanced measures with at most $n$ supports and its applications in various AI tasks such as color transfer or domain adaptation. There is hence the need for fast approximations of POT with increasingly large problem sizes in arising applications. We first theoretically and experimentally investigate the infeasibility of the state-of-the-art Sinkhorn algorithm for POT due to its incompatible rounding procedure, which consequently degrades its qualitative performance in real world applications like point-cloud registration. To this end, we propose a novel rounding algorithm for POT, and then provide a feasible Sinkhorn procedure with a revised computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon^4)$. Our rounding algorithm also permits the development of two first-order methods to approximate the POT problem. The first algorithm, Adaptive Primal-Dual Accelerated Gradient Descent (APDAGD), finds an $\varepsilon$-approximate solution to the POT problem in $\mathcal{\widetilde O}(n^{2.5}/\varepsilon)$, which is better in $\varepsilon$ than revised Sinkhorn. The second method, Dual Extrapolation, achieves the computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon)$, thereby being the best in the literature. We further demonstrate the flexibility of POT compared to standard OT as well as the practicality of our algorithms on real applications where two marginal distributions are unbalanced.
Correlated Attention in Transformers for Multivariate Time Series
Nov 20, 2023

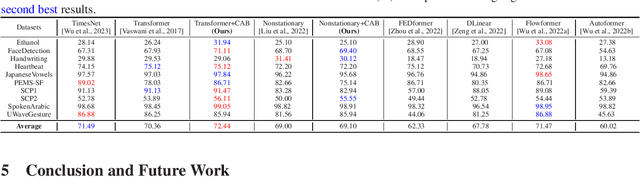
Multivariate time series (MTS) analysis prevails in real-world applications such as finance, climate science and healthcare. The various self-attention mechanisms, the backbone of the state-of-the-art Transformer-based models, efficiently discover the temporal dependencies, yet cannot well capture the intricate cross-correlation between different features of MTS data, which inherently stems from complex dynamical systems in practice. To this end, we propose a novel correlated attention mechanism, which not only efficiently captures feature-wise dependencies, but can also be seamlessly integrated within the encoder blocks of existing well-known Transformers to gain efficiency improvement. In particular, correlated attention operates across feature channels to compute cross-covariance matrices between queries and keys with different lag values, and selectively aggregate representations at the sub-series level. This architecture facilitates automated discovery and representation learning of not only instantaneous but also lagged cross-correlations, while inherently capturing time series auto-correlation. When combined with prevalent Transformer baselines, correlated attention mechanism constitutes a better alternative for encoder-only architectures, which are suitable for a wide range of tasks including imputation, anomaly detection and classification. Extensive experiments on the aforementioned tasks consistently underscore the advantages of correlated attention mechanism in enhancing base Transformer models, and demonstrate our state-of-the-art results in imputation, anomaly detection and classification.
Learning to Schedule in Non-Stationary Wireless Networks With Unknown Statistics
Aug 04, 2023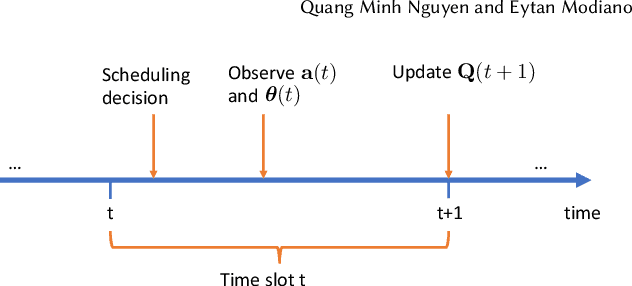
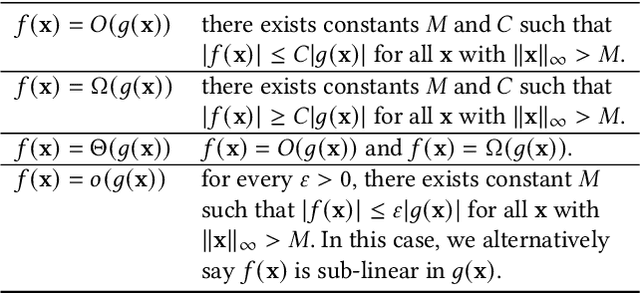
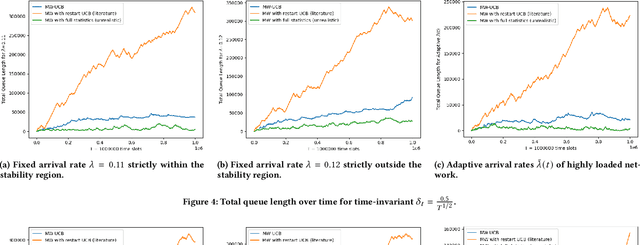
The emergence of large-scale wireless networks with partially-observable and time-varying dynamics has imposed new challenges on the design of optimal control policies. This paper studies efficient scheduling algorithms for wireless networks subject to generalized interference constraint, where mean arrival and mean service rates are unknown and non-stationary. This model exemplifies realistic edge devices' characteristics of wireless communication in modern networks. We propose a novel algorithm termed MW-UCB for generalized wireless network scheduling, which is based on the Max-Weight policy and leverages the Sliding-Window Upper-Confidence Bound to learn the channels' statistics under non-stationarity. MW-UCB is provably throughput-optimal under mild assumptions on the variability of mean service rates. Specifically, as long as the total variation in mean service rates over any time period grows sub-linearly in time, we show that MW-UCB can achieve the stability region arbitrarily close to the stability region of the class of policies with full knowledge of the channel statistics. Extensive simulations validate our theoretical results and demonstrate the favorable performance of MW-UCB.
On the Convergence of Gradient Extrapolation Methods for Unbalanced Optimal Transport
Feb 08, 2022
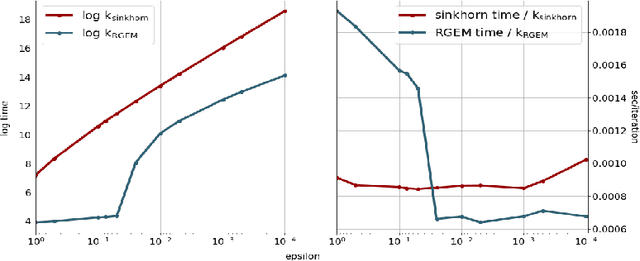
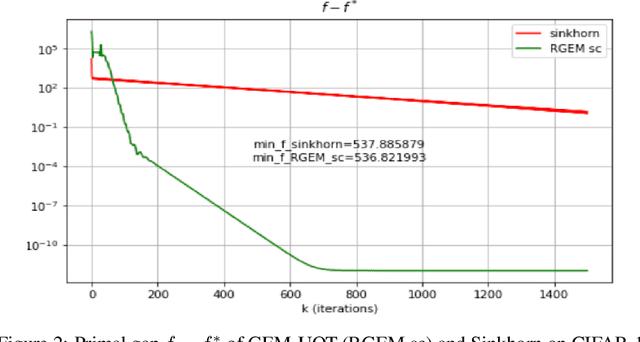
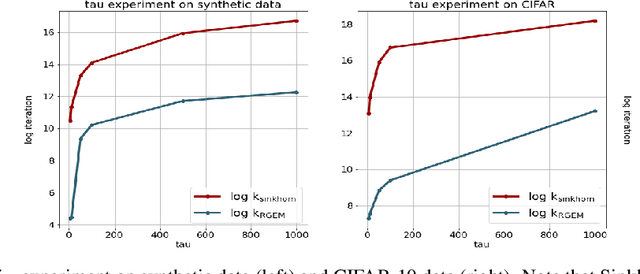
We study the Unbalanced Optimal Transport (UOT) between two measures of possibly different masses with at most $n$ components, where marginal constraints of the standard Optimal Transport (OT) are relaxed via Kullback-Leibler divergence with regularization factor $\tau$. We propose a novel algorithm based on Gradient Extrapolation Method (GEM-UOT) to find an $\varepsilon$-approximate solution to the UOT problem in $O\big( \kappa n^2 \log\big(\frac{\tau n}{\varepsilon}\big) \big)$, where $\kappa$ is the condition number depending on only the two input measures. Compared to the only known complexity ${O}\big(\tfrac{\tau n^2 \log(n)}{\varepsilon} \log\big(\tfrac{\log(n)}{{\varepsilon}}\big)\big)$ for solving the UOT problem via the Sinkhorn algorithm, ours is better in $\varepsilon$ and lifts Sinkhorn's linear dependence on $\tau$, which hindered its practicality to approximate the standard OT via UOT. Our proof technique is based on a novel dual formulation of the squared $\ell_2$-norm regularized UOT objective, which is of independent interest and also leads to a new characterization of approximation error between UOT and OT in terms of both the transportation plan and transport distance. To this end, we further present an algorithm, based on GEM-UOT with fine tuned $\tau$ and a post-process projection step, to find an $\varepsilon$-approximate solution to the standard OT problem in $O\big( \kappa n^2 \log\big(\frac{ n}{\varepsilon}\big) \big)$, which is a new complexity in the literature of OT. Extensive experiments on synthetic and real datasets validate our theories and demonstrate the favorable performance of our methods in practice.
FedXGBoost: Privacy-Preserving XGBoost for Federated Learning
Jun 22, 2021
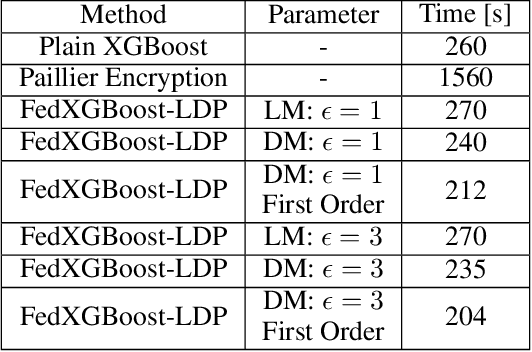


Federated learning is the distributed machine learning framework that enables collaborative training across multiple parties while ensuring data privacy. Practical adaptation of XGBoost, the state-of-the-art tree boosting framework, to federated learning remains limited due to high cost incurred by conventional privacy-preserving methods. To address the problem, we propose two variants of federated XGBoost with privacy guarantee: FedXGBoost-SMM and FedXGBoost-LDP. Our first protocol FedXGBoost-SMM deploys enhanced secure matrix multiplication method to preserve privacy with lossless accuracy and lower overhead than encryption-based techniques. Developed independently, the second protocol FedXGBoost-LDP is heuristically designed with noise perturbation for local differential privacy, and empirically evaluated on real-world and synthetic datasets.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020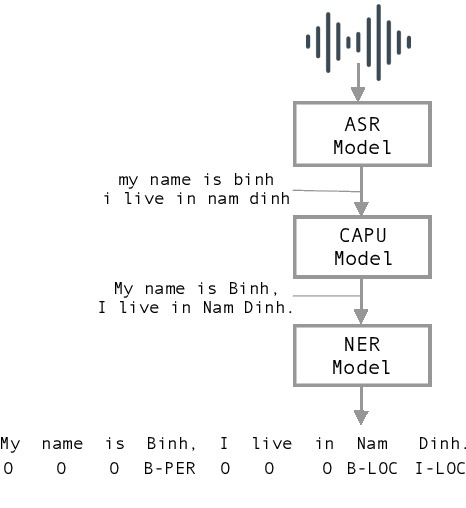

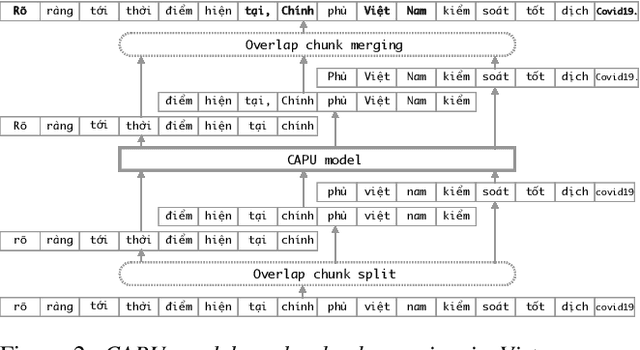
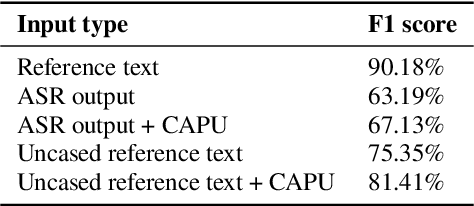
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.
VAIS Hate Speech Detection System: A Deep Learning based Approach for System Combination
Oct 12, 2019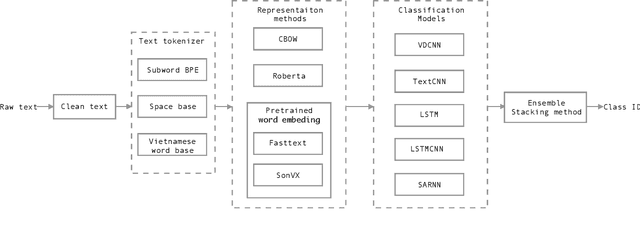
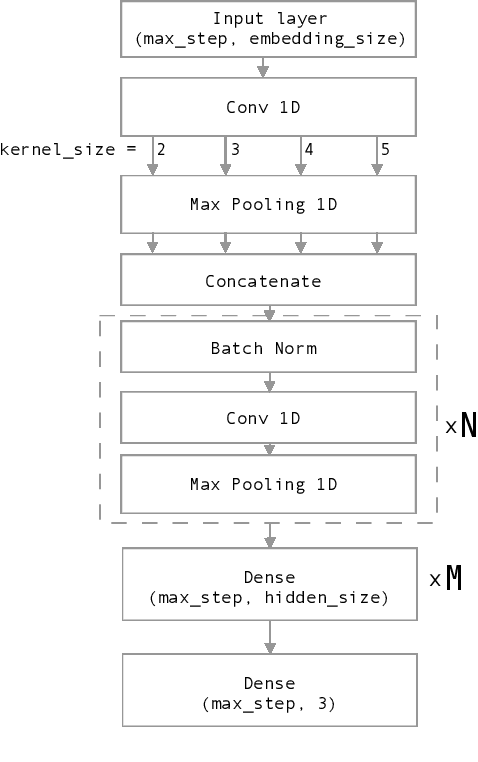
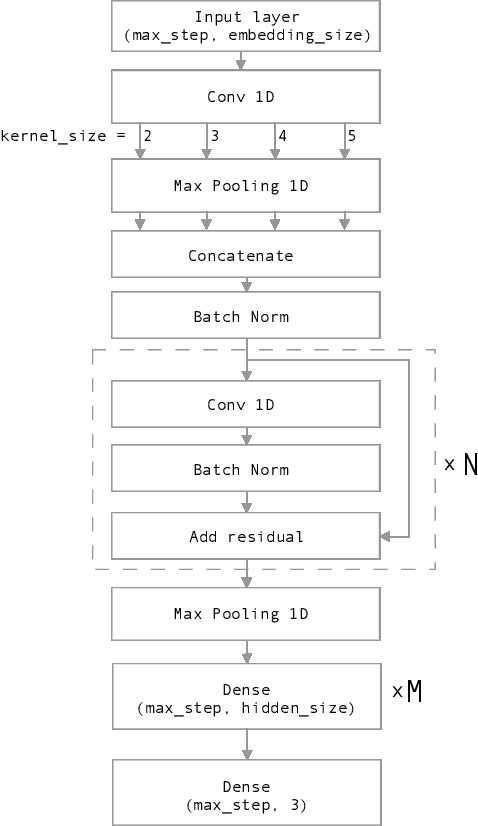
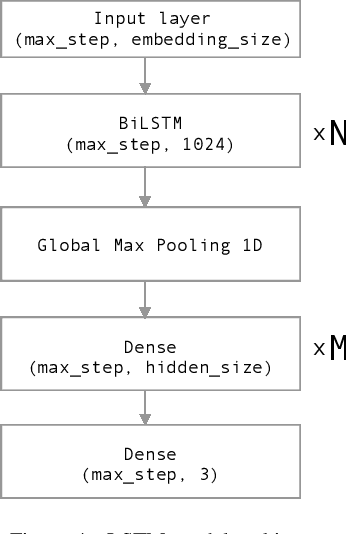
Nowadays, Social network sites (SNSs) such as Facebook, Twitter are common places where people show their opinions, sentiments and share information with others. However, some people use SNSs to post abuse and harassment threats in order to prevent other SNSs users from expressing themselves as well as seeking different opinions. To deal with this problem, SNSs have to use a lot of resources including people to clean the aforementioned content. In this paper, we propose a supervised learning model based on the ensemble method to solve the problem of detecting hate content on SNSs in order to make conversations on SNSs more effective. Our proposed model got the first place for public dashboard with 0.730 F1 macro-score and the third place with 0.584 F1 macro-score for private dashboard at the sixth international workshop on Vietnamese Language and Speech Processing 2019.