 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Switch-Type Policy Network for Resource Allocation Problems: Technical Report
Jan 19, 2025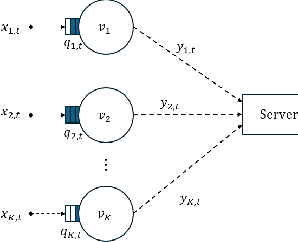
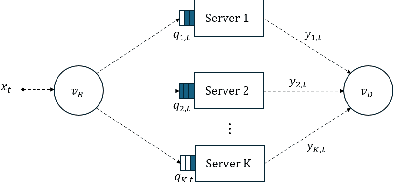
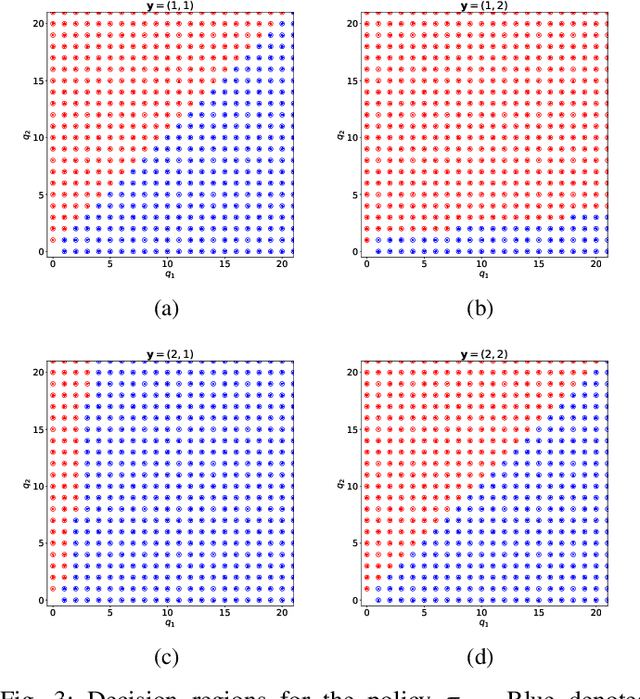
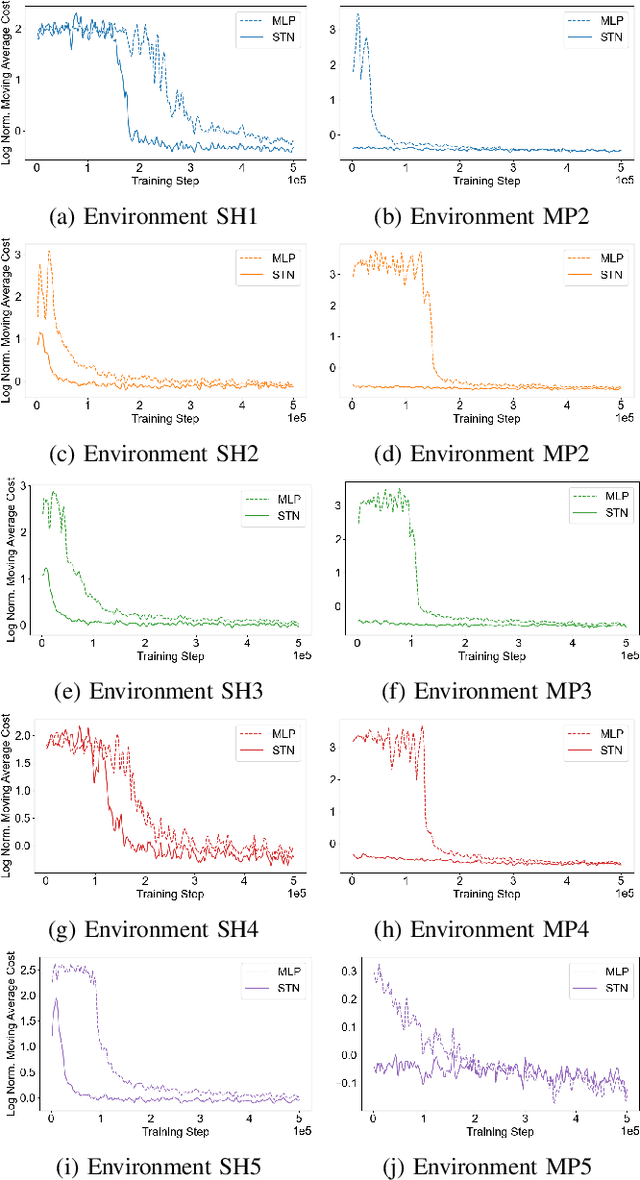
Deep Reinforcement Learning (DRL) has become a powerful tool for developing control policies in queueing networks, but the common use of Multi-layer Perceptron (MLP) neural networks in these applications has significant drawbacks. MLP architectures, while versatile, often suffer from poor sample efficiency and a tendency to overfit training environments, leading to suboptimal performance on new, unseen networks. In response to these issues, we introduce a switch-type neural network (STN) architecture designed to improve the efficiency and generalization of DRL policies in queueing networks. The STN leverages structural patterns from traditional non-learning policies, ensuring consistent action choices across similar states. This design not only streamlines the learning process but also fosters better generalization by reducing the tendency to overfit. Our works presents three key contributions: first, the development of the STN as a more effective alternative to MLPs; second, empirical evidence showing that STNs achieve superior sample efficiency in various training scenarios; and third, experimental results demonstrating that STNs match MLP performance in familiar environments and significantly outperform them in new settings. By embedding domain-specific knowledge, the STN enhances the Proximal Policy Optimization (PPO) algorithm's effectiveness without compromising performance, suggesting its suitability for a wide range of queueing network control problems.
Power Failure Cascade Prediction using Graph Neural Networks
Apr 24, 2024We consider the problem of predicting power failure cascades due to branch failures. We propose a flow-free model based on graph neural networks that predicts grid states at every generation of a cascade process given an initial contingency and power injection values. We train the proposed model using a cascade sequence data pool generated from simulations. We then evaluate our model at various levels of granularity. We present several error metrics that gauge the model's ability to predict the failure size, the final grid state, and the failure time steps of each branch within the cascade. We benchmark the graph neural network model against influence models. We show that, in addition to being generic over randomly scaled power injection values, the graph neural network model outperforms multiple influence models that are built specifically for their corresponding loading profiles. Finally, we show that the proposed model reduces the computational time by almost two orders of magnitude.
Intervention-Assisted Policy Gradient Methods for Online Stochastic Queuing Network Optimization: Technical Report
Apr 05, 2024



Deep Reinforcement Learning (DRL) offers a powerful approach to training neural network control policies for stochastic queuing networks (SQN). However, traditional DRL methods rely on offline simulations or static datasets, limiting their real-world application in SQN control. This work proposes Online Deep Reinforcement Learning-based Controls (ODRLC) as an alternative, where an intelligent agent interacts directly with a real environment and learns an optimal control policy from these online interactions. SQNs present a challenge for ODRLC due to the unbounded nature of the queues within the network resulting in an unbounded state-space. An unbounded state-space is particularly challenging for neural network policies as neural networks are notoriously poor at extrapolating to unseen states. To address this challenge, we propose an intervention-assisted framework that leverages strategic interventions from known stable policies to ensure the queue sizes remain bounded. This framework combines the learning power of neural networks with the guaranteed stability of classical control policies for SQNs. We introduce a method to design these intervention-assisted policies to ensure strong stability of the network. Furthermore, we extend foundational DRL theorems for intervention-assisted policies and develop two practical algorithms specifically for ODRLC of SQNs. Finally, we demonstrate through experiments that our proposed algorithms outperform both classical control approaches and prior ODRLC algorithms.
Learning to Schedule in Non-Stationary Wireless Networks With Unknown Statistics
Aug 04, 2023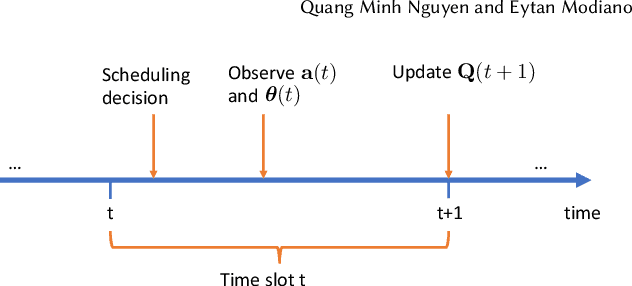
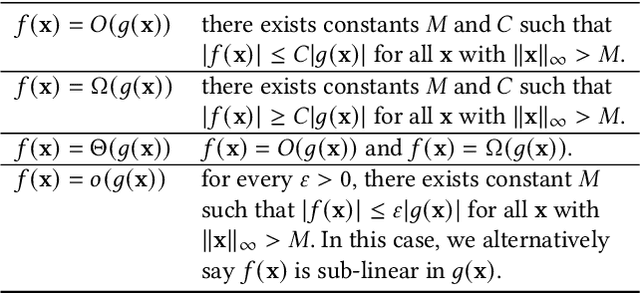
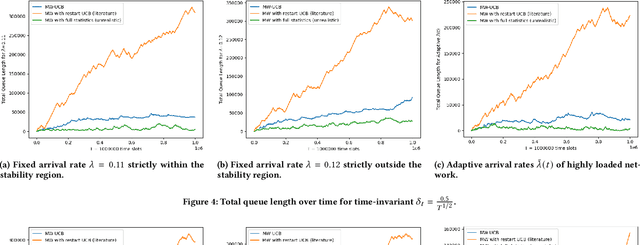
The emergence of large-scale wireless networks with partially-observable and time-varying dynamics has imposed new challenges on the design of optimal control policies. This paper studies efficient scheduling algorithms for wireless networks subject to generalized interference constraint, where mean arrival and mean service rates are unknown and non-stationary. This model exemplifies realistic edge devices' characteristics of wireless communication in modern networks. We propose a novel algorithm termed MW-UCB for generalized wireless network scheduling, which is based on the Max-Weight policy and leverages the Sliding-Window Upper-Confidence Bound to learn the channels' statistics under non-stationarity. MW-UCB is provably throughput-optimal under mild assumptions on the variability of mean service rates. Specifically, as long as the total variation in mean service rates over any time period grows sub-linearly in time, we show that MW-UCB can achieve the stability region arbitrarily close to the stability region of the class of policies with full knowledge of the channel statistics. Extensive simulations validate our theoretical results and demonstrate the favorable performance of MW-UCB.
WiSwarm: Age-of-Information-based Wireless Networking for Collaborative Teams of UAVs
Dec 06, 2022



The Age-of-Information (AoI) metric has been widely studied in the theoretical communication networks and queuing systems literature. However, experimental evaluation of its applicability to complex real-world time-sensitive systems is largely lacking. In this work, we develop, implement, and evaluate an AoI-based application layer middleware that enables the customization of WiFi networks to the needs of time-sensitive applications. By controlling the storage and flow of information in the underlying WiFi network, our middleware can: (i) prevent packet collisions; (ii) discard stale packets that are no longer useful; and (iii) dynamically prioritize the transmission of the most relevant information. To demonstrate the benefits of our middleware, we implement a mobility tracking application using a swarm of UAVs communicating with a central controller via WiFi. Our experimental results show that, when compared to WiFi-UDP/WiFi-TCP, the middleware can improve information freshness by a factor of 109x/48x and tracking accuracy by a factor of 4x/6x, respectively. Most importantly, our results also show that the performance gains of our approach increase as the system scales and/or the traffic load increases.
Computation and Communication Co-Design for Real-Time Monitoring and Control in Multi-Agent Systems
Aug 09, 2021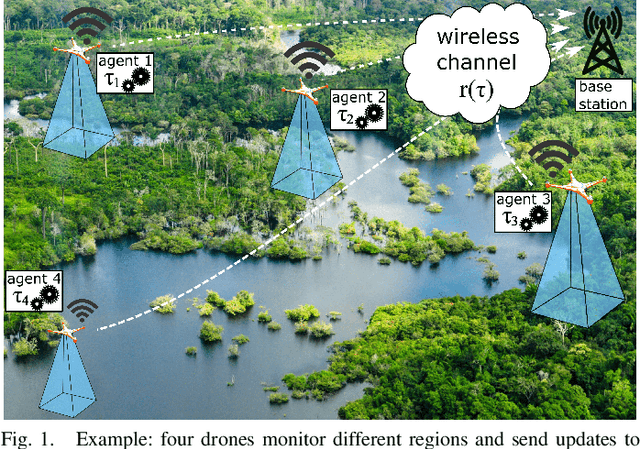
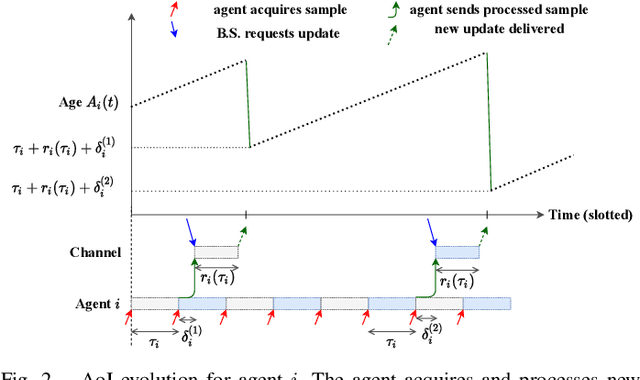
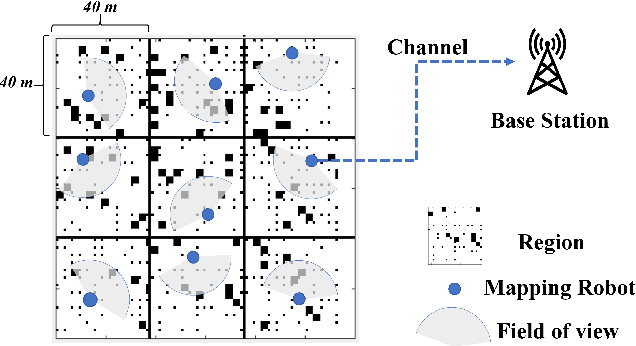
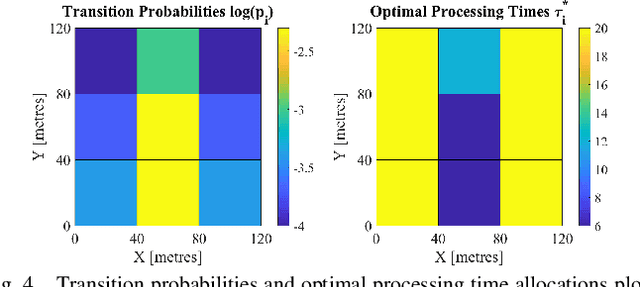
We investigate the problem of co-designing computation and communication in a multi-agent system (e.g. a sensor network or a multi-robot team). We consider the realistic setting where each agent acquires sensor data and is capable of local processing before sending updates to a base station, which is in charge of making decisions or monitoring phenomena of interest in real time. Longer processing at an agent leads to more informative updates but also larger delays, giving rise to a delay-accuracy-tradeoff in choosing the right amount of local processing at each agent. We assume that the available communication resources are limited due to interference, bandwidth, and power constraints. Thus, a scheduling policy needs to be designed to suitably share the communication channel among the agents. To that end, we develop a general formulation to jointly optimize the local processing at the agents and the scheduling of transmissions. Our novel formulation leverages the notion of Age of Information to quantify the freshness of data and capture the delays caused by computation and communication. We develop efficient resource allocation algorithms using the Whittle index approach and demonstrate our proposed algorithms in two practical applications: multi-agent occupancy grid mapping in time-varying environments, and ride sharing in autonomous vehicle networks. Our experiments show that the proposed co-design approach leads to a substantial performance improvement (18-82% in our tests).
An Online Learning Approach to Optimizing Time-Varying Costs of AoI
May 27, 2021
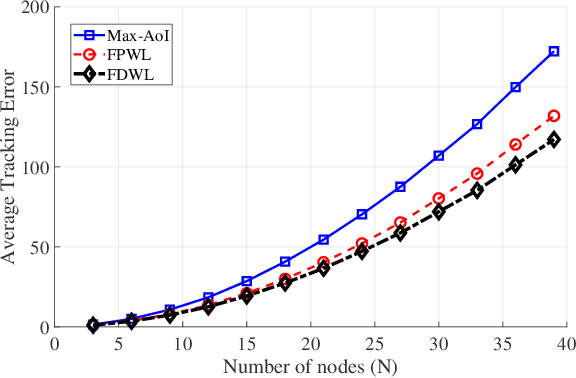
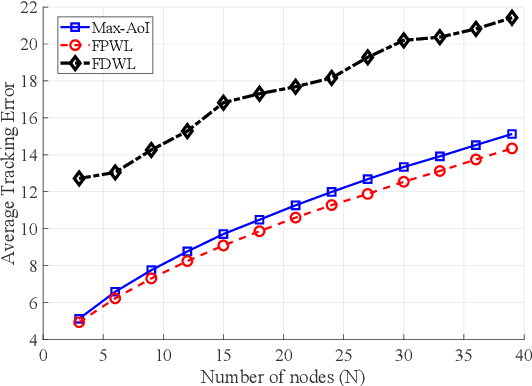
We consider systems that require timely monitoring of sources over a communication network, where the cost of delayed information is unknown, time-varying and possibly adversarial. For the single source monitoring problem, we design algorithms that achieve sublinear regret compared to the best fixed policy in hindsight. For the multiple source scheduling problem, we design a new online learning algorithm called Follow-the-Perturbed-Whittle-Leader and show that it has low regret compared to the best fixed scheduling policy in hindsight, while remaining computationally feasible. The algorithm and its regret analysis are novel and of independent interest to the study of online restless multi-armed bandit problems. We further design algorithms that achieve sublinear regret compared to the best dynamic policy when the environment is slowly varying. Finally, we apply our algorithms to a mobility tracking problem. We consider non-stationary and adversarial mobility models and illustrate the performance benefit of using our online learning algorithms compared to an oblivious scheduling policy.
Aging Bandits: Regret Analysis and Order-Optimal Learning Algorithm for Wireless Networks with Stochastic Arrivals
Dec 21, 2020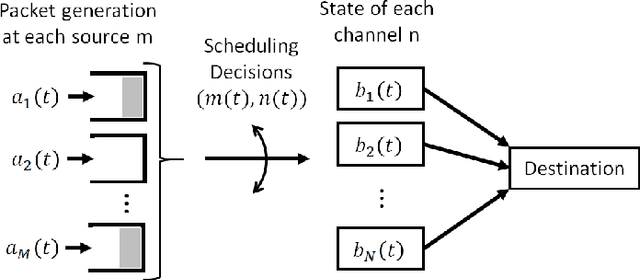
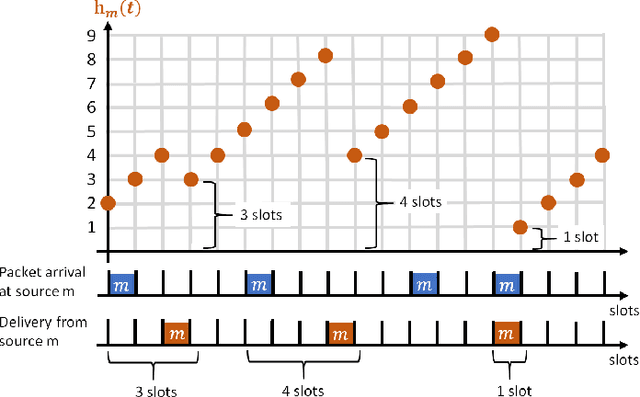
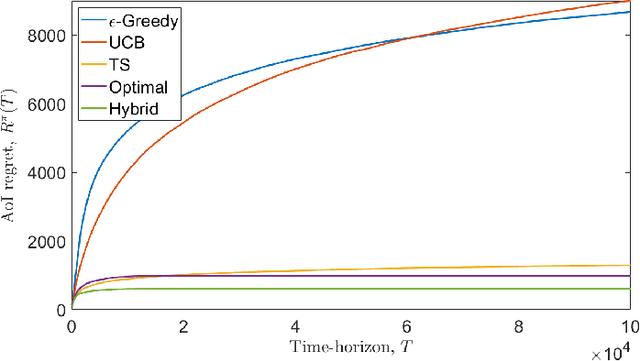
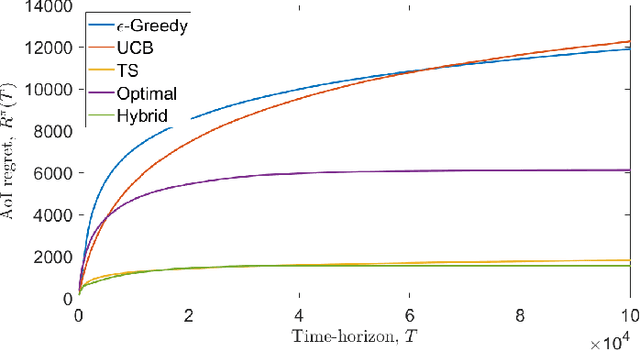
We consider a single-hop wireless network with sources transmitting time-sensitive information to the destination over multiple unreliable channels. Packets from each source are generated according to a stochastic process with known statistics and the state of each wireless channel (ON/OFF) varies according to a stochastic process with unknown statistics. The reliability of the wireless channels is to be learned through observation. At every time slot, the learning algorithm selects a single pair (source, channel) and the selected source attempts to transmit its packet via the selected channel. The probability of a successful transmission to the destination depends on the reliability of the selected channel. The goal of the learning algorithm is to minimize the Age-of-Information (AoI) in the network over $T$ time slots. To analyze the performance of the learning algorithm, we introduce the notion of AoI regret, which is the difference between the expected cumulative AoI of the learning algorithm under consideration and the expected cumulative AoI of a genie algorithm that knows the reliability of the channels a priori. The AoI regret captures the penalty incurred by having to learn the statistics of the channels over the $T$ time slots. The results are two-fold: first, we consider learning algorithms that employ well-known solutions to the stochastic multi-armed bandit problem (such as $\epsilon$-Greedy, Upper Confidence Bound, and Thompson Sampling) and show that their AoI regret scales as $\Theta(\log T)$; second, we develop a novel learning algorithm and show that it has $O(1)$ regret. To the best of our knowledge, this is the first learning algorithm with bounded AoI regret.
Learning-NUM: Network Utility Maximization with Unknown Utility Functions and Queueing Delay
Dec 16, 2020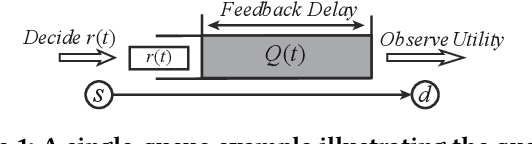
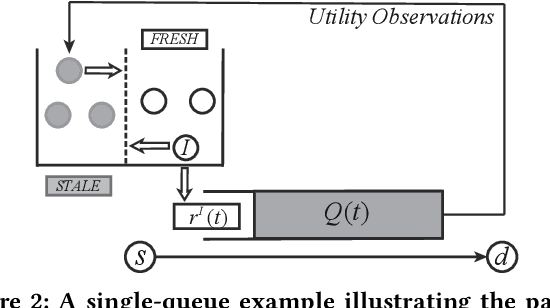
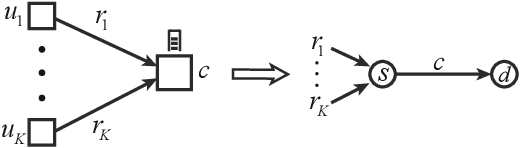

Network Utility Maximization (NUM) studies the problems of allocating traffic rates to network users in order to maximize the users' total utility subject to network resource constraints. In this paper, we propose a new NUM framework, Learning-NUM, where the users' utility functions are unknown apriori and the utility function values of the traffic rates can be observed only after the corresponding traffic is delivered to the destination, which means that the utility feedback experiences \textit{queueing delay}. The goal is to design a policy that gradually learns the utility functions and makes rate allocation and network scheduling/routing decisions so as to maximize the total utility obtained over a finite time horizon $T$. In addition to unknown utility functions and stochastic constraints, a central challenge of our problem lies in the queueing delay of the observations, which may be unbounded and depends on the decisions of the policy. We first show that the expected total utility obtained by the best dynamic policy is upper bounded by the solution to a static optimization problem. Without the presence of feedback delay, we design an algorithm based on the ideas of gradient estimation and Max-Weight scheduling. To handle the feedback delay, we embed the algorithm in a parallel-instance paradigm to form a policy that achieves $\tilde{O}(T^{3/4})$-regret, i.e., the difference between the expected utility obtained by the best dynamic policy and our policy is in $\tilde{O}(T^{3/4})$. Finally, to demonstrate the practical applicability of the Learning-NUM framework, we apply it to three application scenarios including database query, job scheduling and video streaming. We further conduct simulations on the job scheduling application to evaluate the empirical performance of our policy.
RL-QN: A Reinforcement Learning Framework for Optimal Control of Queueing Systems
Nov 14, 2020

With the rapid advance of information technology, network systems have become increasingly complex and hence the underlying system dynamics are often unknown or difficult to characterize. Finding a good network control policy is of significant importance to achieve desirable network performance (e.g., high throughput or low delay). In this work, we consider using model-based reinforcement learning (RL) to learn the optimal control policy for queueing networks so that the average job delay (or equivalently the average queue backlog) is minimized. Traditional approaches in RL, however, cannot handle the unbounded state spaces of the network control problem. To overcome this difficulty, we propose a new algorithm, called Reinforcement Learning for Queueing Networks (RL-QN), which applies model-based RL methods over a finite subset of the state space, while applying a known stabilizing policy for the rest of the states. We establish that the average queue backlog under RL-QN with an appropriately constructed subset can be arbitrarily close to the optimal result. We evaluate RL-QN in dynamic server allocation, routing and switching problems. Simulation results show that RL-QN minimizes the average queue backlog effectively.