 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4GEN: Leveraging Semantic Representation of LLMs for Text-to-Image Generation
Jun 30, 2024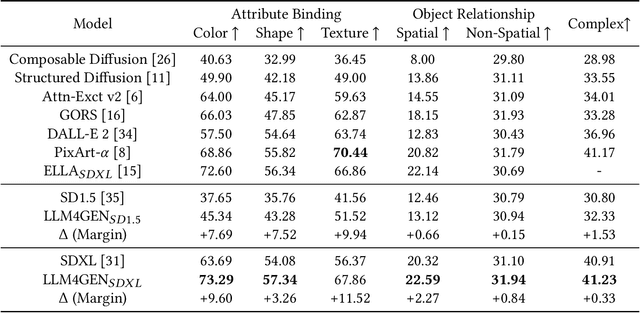
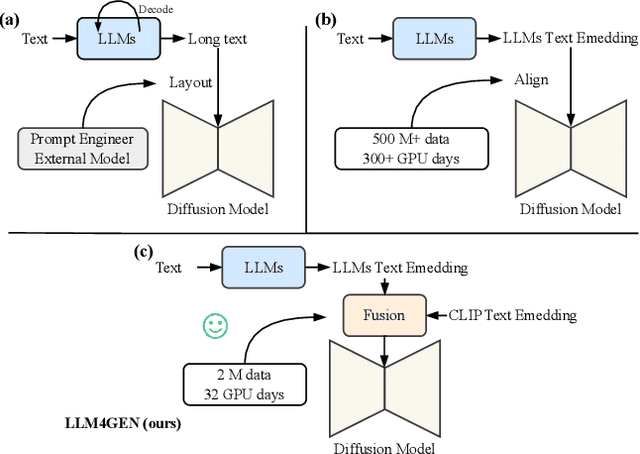


Diffusion Models have exhibited substantial success in text-to-image generation. However, they often encounter challenges when dealing with complex and dense prompts that involve multiple objects, attribute binding, and long descriptions. This paper proposes a framework called \textbf{LLM4GEN}, which enhances the semantic understanding ability of text-to-image diffusion models by leveraging the semantic representation of Large Language Models (LLMs). Through a specially designed Cross-Adapter Module (CAM) that combines the original text features of text-to-image models with LLM features, LLM4GEN can be easily incorporated into various diffusion models as a plug-and-play component and enhances text-to-image generation. Additionally, to facilitate the complex and dense prompts semantic understanding, we develop a LAION-refined dataset, consisting of 1 million (M) text-image pairs with improved image descriptions. We also introduce DensePrompts which contains 7,000 dense prompts to provide a comprehensive evaluation for the text-to-image generation task. With just 10\% of the training data required by recent ELLA, LLM4GEN significantly improves the semantic alignment of SD1.5 and SDXL, demonstrating increases of 7.69\% and 9.60\% in color on T2I-CompBench, respectively. The extensive experiments on DensePrompts also demonstrate that LLM4GEN surpasses existing state-of-the-art models in terms of sample quality, image-text alignment, and human evaluation. The project website is at: \textcolor{magenta}{\url{https://xiaobul.github.io/LLM4GEN/}}
Easy and Efficient Transformer : Scalable Inference Solution For large NLP mode
Apr 26, 2021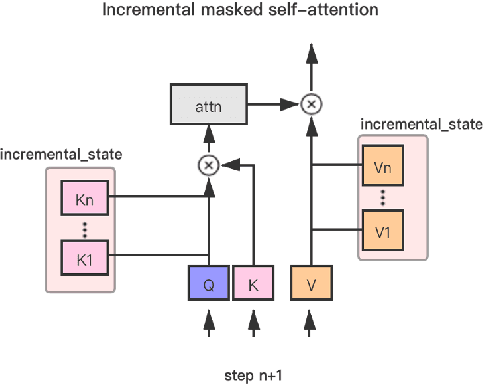
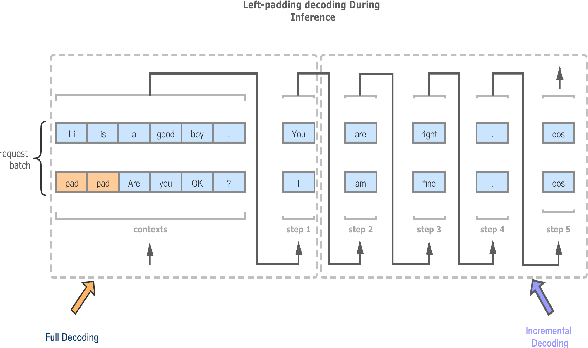

The ultra-large-scale pre-training model can effectively improve the effect of a variety of tasks, and it also brings a heavy computational burden to inference. This paper introduces a series of ultra-large-scale pre-training model optimization methods that combine algorithm characteristics and GPU processor hardware characteristics, and on this basis, propose an inference engine -- Easy and Efficient Transformer (EET), Which has a significant performance improvement over the existing schemes. We firstly introduce a pre-padding decoding mechanism that improves token parallelism for generation tasks. Then we design high optimized kernels to remove sequence masks and achieve cost-free calculation for padding tokens, as well as support long sequence and long embedding sizes. Thirdly a user-friendly inference system with an easy service pipeline was introduced which greatly reduces the difficulty of engineering deployment with high throughput. Compared to Faster Transformer's implementation for GPT-2 on A100, EET achieves a 1.5-15x state-of-art speedup varying with context length.EET is available https://github.com/NetEase-FuXi/EET.
RL-QN: A Reinforcement Learning Framework for Optimal Control of Queueing Systems
Nov 14, 2020
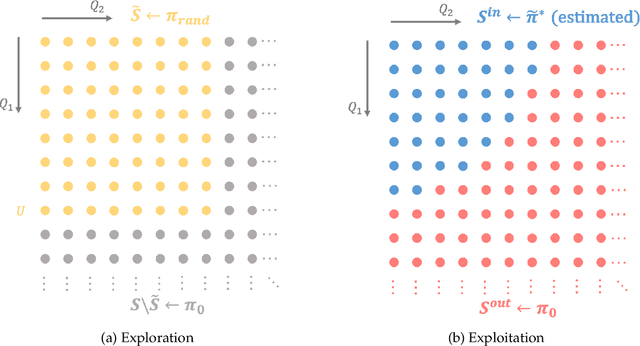

With the rapid advance of information technology, network systems have become increasingly complex and hence the underlying system dynamics are often unknown or difficult to characterize. Finding a good network control policy is of significant importance to achieve desirable network performance (e.g., high throughput or low delay). In this work, we consider using model-based reinforcement learning (RL) to learn the optimal control policy for queueing networks so that the average job delay (or equivalently the average queue backlog) is minimized. Traditional approaches in RL, however, cannot handle the unbounded state spaces of the network control problem. To overcome this difficulty, we propose a new algorithm, called Reinforcement Learning for Queueing Networks (RL-QN), which applies model-based RL methods over a finite subset of the state space, while applying a known stabilizing policy for the rest of the states. We establish that the average queue backlog under RL-QN with an appropriately constructed subset can be arbitrarily close to the optimal result. We evaluate RL-QN in dynamic server allocation, routing and switching problems. Simulation results show that RL-QN minimizes the average queue backlog effectively.