 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoLLMwood: Unleashing the Creativity of Large Language Models in Screenwriting via Role Playing
Jun 17, 2024



Generative AI has demonstrated unprecedented creativity in the field of computer vision, yet such phenomena have not been observed in natural language processing. In particular, large language models (LLMs) can hardly produce written works at the level of human experts due to the extremely high complexity of literature writing. In this paper, we present HoLLMwood, an automated framework for unleashing the creativity of LLMs and exploring their potential in screenwriting, which is a highly demanding task. Mimicking the human creative process, we assign LLMs to different roles involved in the real-world scenario. In addition to the common practice of treating LLMs as ${Writer}$, we also apply LLMs as ${Editor}$, who is responsible for providing feedback and revision advice to ${Writer}$. Besides, to enrich the characters and deepen the plots, we introduce a role-playing mechanism and adopt LLMs as ${Actors}$ that can communicate and interact with each other. Evaluations on automatically generated screenplays show that HoLLMwood substantially outperforms strong baselines in terms of coherence, relevance, interestingness and overall quality.
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023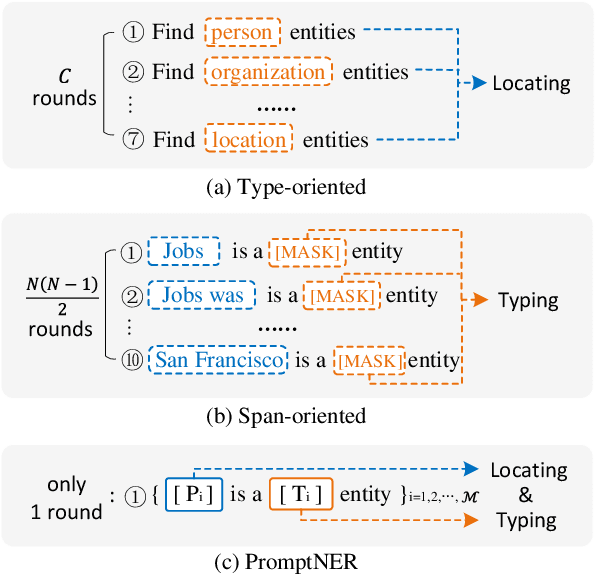
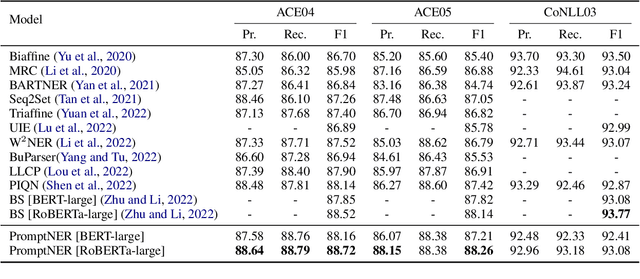
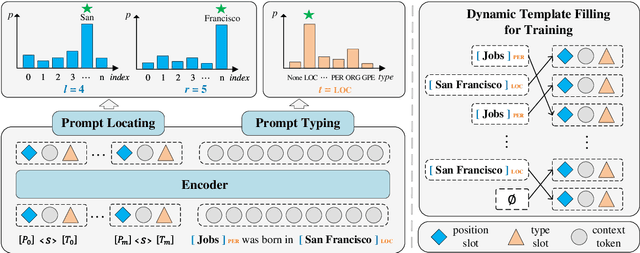
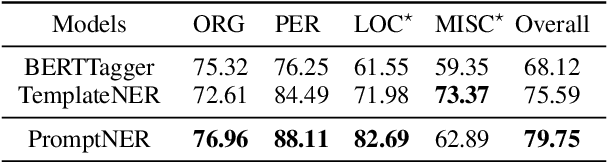
Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.
Probing Simile Knowledge from Pre-trained Language Models
Apr 27, 2022

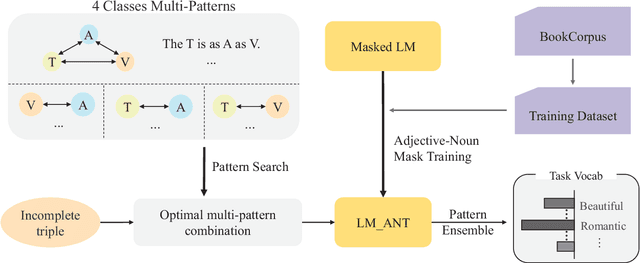
Simile interpretation (SI) and simile generation (SG) are challenging tasks for NLP because models require adequate world knowledge to produce predictions. Previous works have employed many hand-crafted resources to bring knowledge-related into models, which is time-consuming and labor-intensive. In recent years, pre-trained language models (PLMs) based approaches have become the de-facto standard in NLP since they learn generic knowledge from a large corpus. The knowledge embedded in PLMs may be useful for SI and SG tasks. Nevertheless, there are few works to explore it. In this paper, we probe simile knowledge from PLMs to solve the SI and SG tasks in the unified framework of simile triple completion for the first time. The backbone of our framework is to construct masked sentences with manual patterns and then predict the candidate words in the masked position. In this framework, we adopt a secondary training process (Adjective-Noun mask Training) with the masked language model (MLM) loss to enhance the prediction diversity of candidate words in the masked position. Moreover, pattern ensemble (PE) and pattern search (PS) are applied to improve the quality of predicted words. Finally, automatic and human evaluations demonstrate the effectiveness of our framework in both SI and SG tasks.
DecBERT: Enhancing the Language Understanding of BERT with Causal Attention Masks
Apr 19, 2022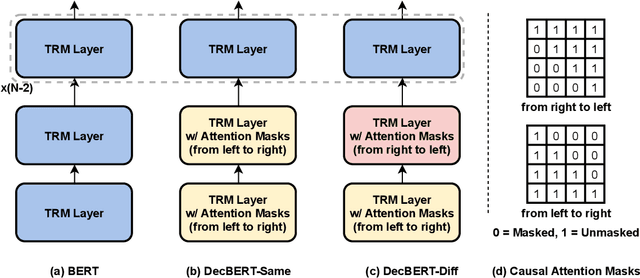


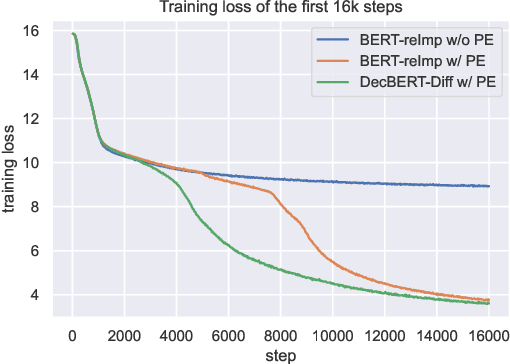
Since 2017, the Transformer-based models play critical roles in various downstream Natural Language Processing tasks. However, a common limitation of the attention mechanism utilized in Transformer Encoder is that it cannot automatically capture the information of word order, so explicit position embeddings are generally required to be fed into the target model. In contrast, Transformer Decoder with the causal attention masks is naturally sensitive to the word order. In this work, we focus on improving the position encoding ability of BERT with the causal attention masks. Furthermore, we propose a new pre-trained language model DecBERT and evaluate it on the GLUE benchmark. Experimental results show that (1) the causal attention mask is effective for BERT on the language understanding tasks; (2) our DecBERT model without position embeddings achieve comparable performance on the GLUE benchmark; and (3) our modification accelerates the pre-training process and DecBERT w/ PE achieves better overall performance than the baseline systems when pre-training with the same amount of computational resources.
I-Tuning: Tuning Language Models with Image for Caption Generation
Feb 14, 2022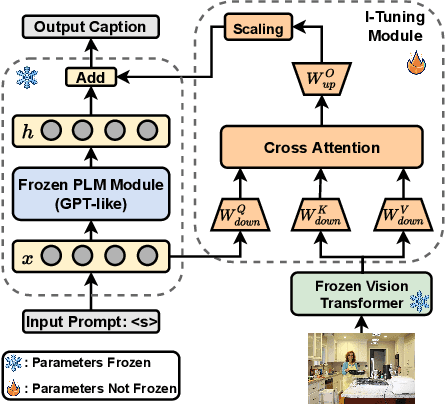
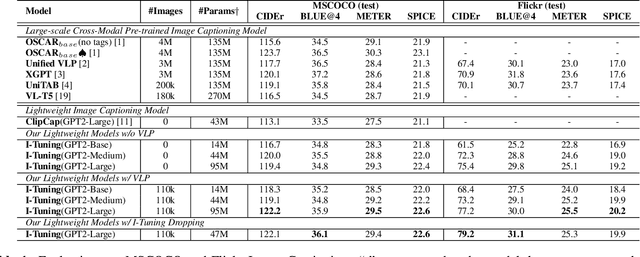
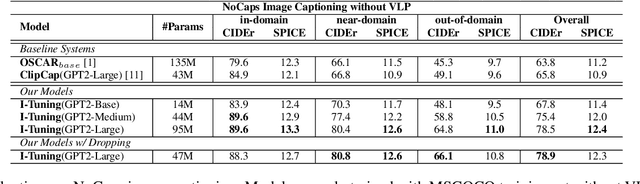

Recently, tuning the pre-trained language model (PLM) in a parameter-efficient manner becomes a popular topic in the natural language processing area. However, most of them focus on tuning the PLM with the text-only information. In this work, we propose a new perspective to tune the frozen PLM with images for caption generation. We denote our method as I-Tuning, which can automatically filter the vision information from images to adjust the output hidden states of PLM. Evaluating on the image captioning tasks (MSCOCO and Flickr30k Captioning), our method achieves comparable or even better performance than the previous models which have 2-4 times more trainable parameters and/or consume a large amount of cross-modal pre-training data.
VC-GPT: Visual Conditioned GPT for End-to-End Generative Vision-and-Language Pre-training
Feb 06, 2022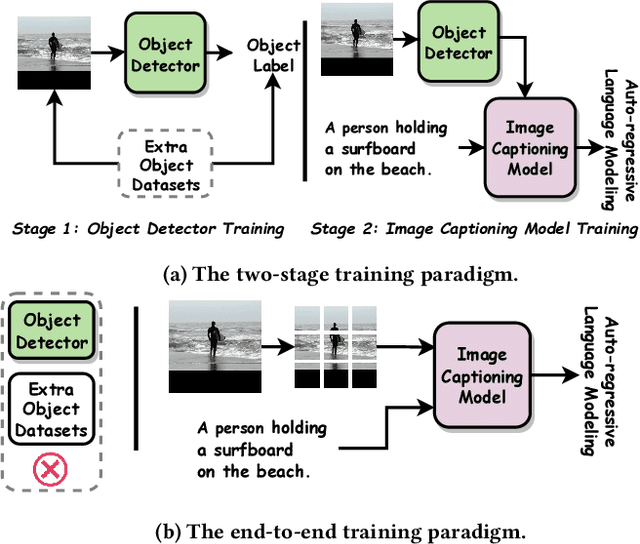
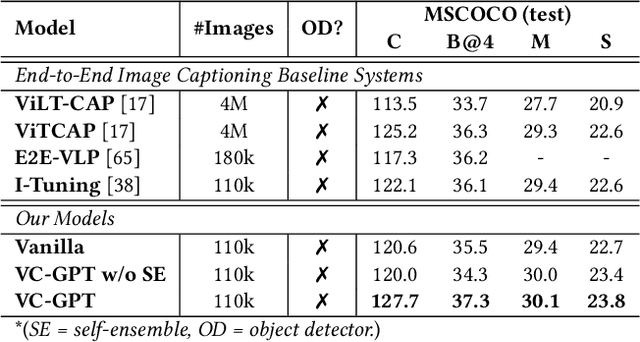
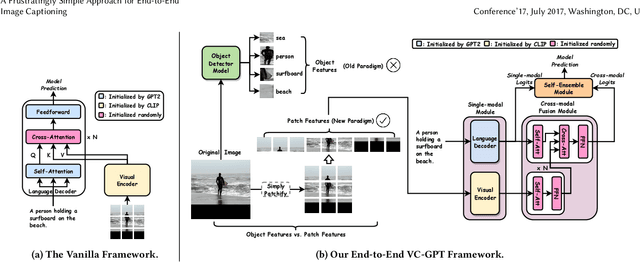
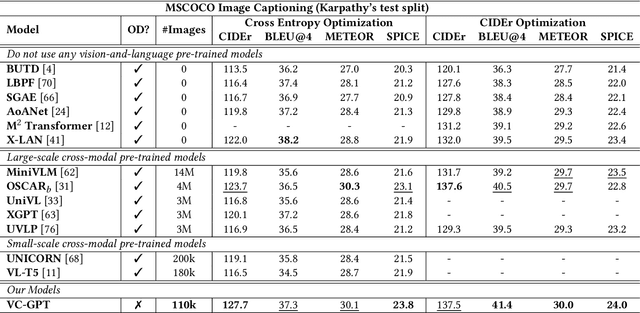
Vision-and-language pre-trained models (VLMs) have achieved tremendous success in the cross-modal area, but most of them require a large amount of parallel image-caption data for pre-training. Collating such data is expensive and labor-intensive. In this work, we focus on reducing such need for generative vision-and-language pre-training (G-VLP) by taking advantage of the visual pre-trained model (CLIP-ViT) as encoder and language pre-trained model (GPT2) as decoder. Unfortunately, GPT2 lacks a necessary cross-attention module, which hinders the direct connection of CLIP-ViT and GPT2. To remedy such defects, we conduct extensive experiments to empirically investigate how to design and pre-train our model. Based on our experimental results, we propose a novel G-VLP framework, Visual Conditioned GPT (VC-GPT), and pre-train it with a small-scale image-caption corpus (Visual Genome, only 110k distinct images). Evaluating on the image captioning downstream tasks (MSCOCO and Flickr30k Captioning), VC-GPT achieves either the best or the second-best performance across all evaluation metrics over the previous works which consume around 30 times more distinct images during cross-modal pre-training.
Youling: an AI-Assisted Lyrics Creation System
Jan 18, 2022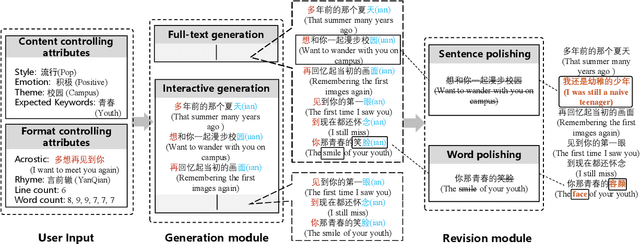
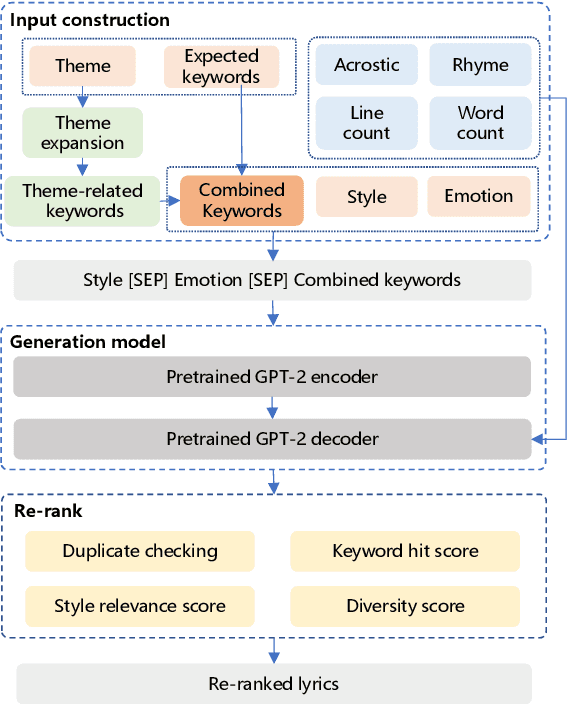
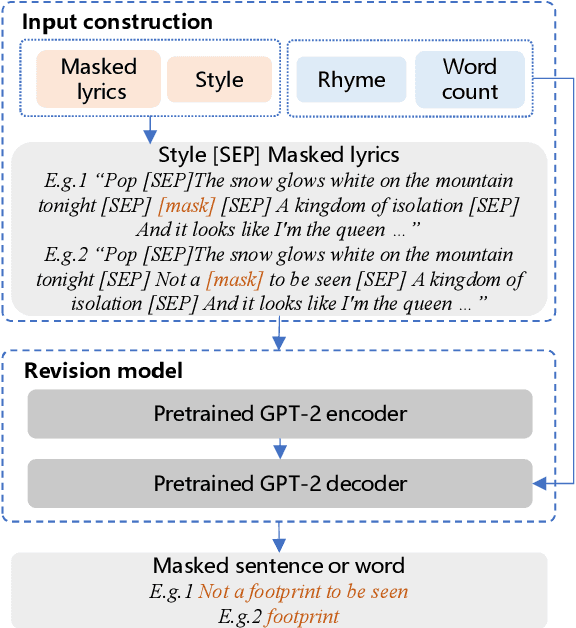
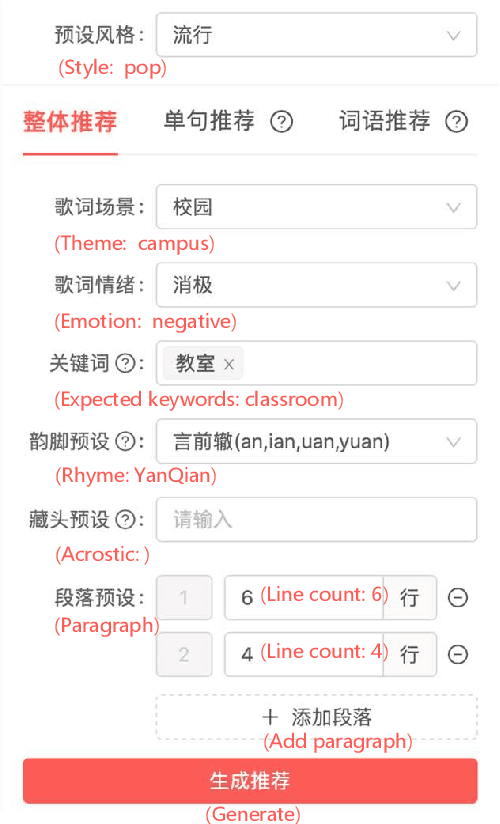
Recently, a variety of neural models have been proposed for lyrics generation. However, most previous work completes the generation process in a single pass with little human intervention. We believe that lyrics creation is a creative process with human intelligence centered. AI should play a role as an assistant in the lyrics creation process, where human interactions are crucial for high-quality creation. This paper demonstrates \textit{Youling}, an AI-assisted lyrics creation system, designed to collaborate with music creators. In the lyrics generation process, \textit{Youling} supports traditional one pass full-text generation mode as well as an interactive generation mode, which allows users to select the satisfactory sentences from generated candidates conditioned on preceding context. The system also provides a revision module which enables users to revise undesired sentences or words of lyrics repeatedly. Besides, \textit{Youling} allows users to use multifaceted attributes to control the content and format of generated lyrics. The demo video of the system is available at https://youtu.be/DFeNpHk0pm4.
Taming Repetition in Dialogue Generation
Dec 16, 2021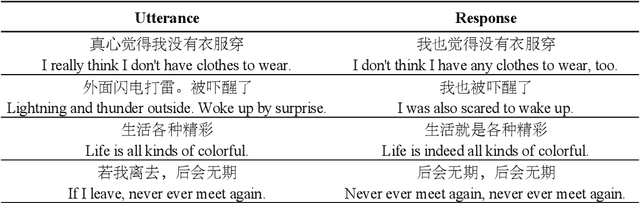
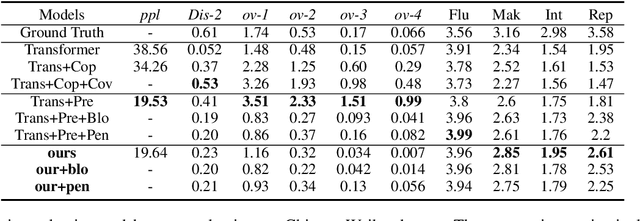
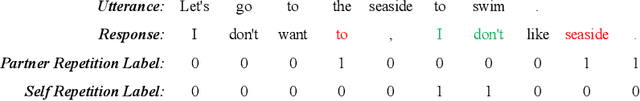
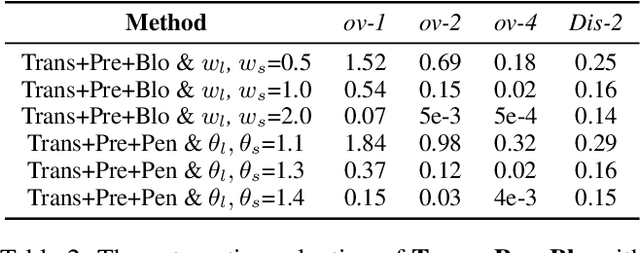
The wave of pre-training language models has been continuously improving the quality of the machine-generated conversations, however, some of the generated responses still suffer from excessive repetition, sometimes repeating words from utterance, sometimes repeating words within self-generated responses, or both. Inappropriate repetition of words can significantly degrade the quality of the generated texts. Penalized sampling is one popular solution, reducing the sampling probability of existing words during inference, however, it is highly vulnerable to the inappropriate setting of the static weight. Setting it too high can yield strange and unrealistic sentences while setting it too low makes the task of suppressing repetition trivial. To remedy the shortcomings of the above methods, we design a context-aware classifier to explicitly decide when to allow repetition and when to employ penalized sampling. Such a classifier can be easily integrated with existing decoding methods, reducing repetitions where appropriate while preserving the diversity of the text. Experimental results demonstrate that our method can generate higher quality and more authentic dialogues.
Easy and Efficient Transformer : Scalable Inference Solution For large NLP mode
Apr 26, 2021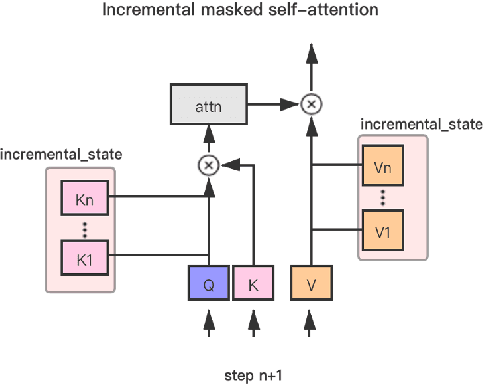
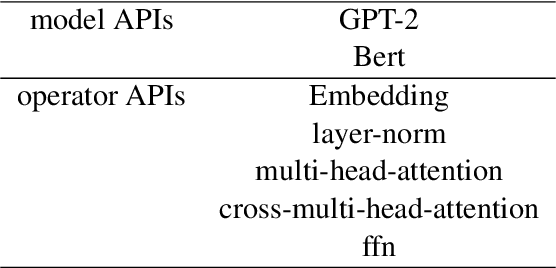
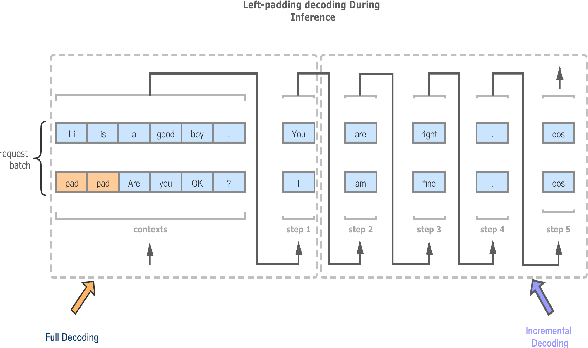

The ultra-large-scale pre-training model can effectively improve the effect of a variety of tasks, and it also brings a heavy computational burden to inference. This paper introduces a series of ultra-large-scale pre-training model optimization methods that combine algorithm characteristics and GPU processor hardware characteristics, and on this basis, propose an inference engine -- Easy and Efficient Transformer (EET), Which has a significant performance improvement over the existing schemes. We firstly introduce a pre-padding decoding mechanism that improves token parallelism for generation tasks. Then we design high optimized kernels to remove sequence masks and achieve cost-free calculation for padding tokens, as well as support long sequence and long embedding sizes. Thirdly a user-friendly inference system with an easy service pipeline was introduced which greatly reduces the difficulty of engineering deployment with high throughput. Compared to Faster Transformer's implementation for GPT-2 on A100, EET achieves a 1.5-15x state-of-art speedup varying with context length.EET is available https://github.com/NetEase-FuXi/EET.
Dialogue Distillation: Open-domain Dialogue Augmentation Using Unpaired Data
Sep 20, 2020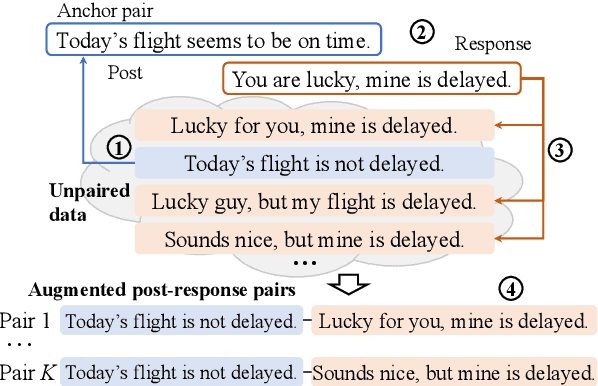
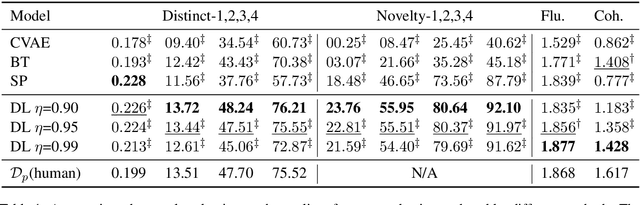


Recent advances in open-domain dialogue systems rely on the success of neural models that are trained on large-scale data. However, collecting large-scale dialogue data is usually time-consuming and labor-intensive. To address this data dilemma, we propose a novel data augmentation method for training open-domain dialogue models by utilizing unpaired data. Specifically, a data-level distillation process is first proposed to construct augmented dialogues where both post and response are retrieved from the unpaired data. A ranking module is employed to filter out low-quality dialogues. Further, a model-level distillation process is employed to distill a teacher model trained on high-quality paired data to augmented dialogue pairs, thereby preventing dialogue models from being affected by the noise in the augmented data. Automatic and manual evaluation indicates that our method can produce high-quality dialogue pairs with diverse contents, and the proposed data-level and model-level dialogue distillation can improve the performance of competitive baselines.