 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPPA: A Partially Synthetic Conversational Dataset
Aug 11, 2023



With the emergence of increasingly powerful large language models, there is a burgeoning interest in leveraging these models for casual conversation and role-play applications. However, existing conversational and role-playing datasets often fail to capture the diverse and nuanced interactions typically exhibited by real-world role-play participants. To address this limitation and contribute to the rapidly growing field, we introduce a partially-synthetic dataset named PIPPA (Personal Interaction Pairs between People and AI). PIPPA is a result of a community-driven crowdsourcing effort involving a group of role-play enthusiasts. The dataset comprises over 1 million utterances that are distributed across 26,000 conversation sessions and provides a rich resource for researchers and AI developers to explore and refine conversational AI systems in the context of role-play scenarios.
Domain Incremental Lifelong Learning in an Open World
May 11, 2023Lifelong learning (LL) is an important ability for NLP models to learn new tasks continuously. Architecture-based approaches are reported to be effective implementations for LL models. However, it is non-trivial to extend previous approaches to domain incremental LL scenarios since they either require access to task identities in the testing phase or cannot handle samples from unseen tasks. In this paper, we propose \textbf{Diana}: a \underline{d}ynam\underline{i}c \underline{a}rchitecture-based lifelo\underline{n}g le\underline{a}rning model that tries to learn a sequence of tasks with a prompt-enhanced language model. Four types of hierarchically organized prompts are used in Diana to capture knowledge from different granularities. Specifically, we dedicate task-level prompts to capture task-specific knowledge to retain high LL performances and maintain instance-level prompts to learn knowledge shared across input samples to improve the model's generalization performance. Moreover, we dedicate separate prompts to explicitly model unseen tasks and introduce a set of prompt key vectors to facilitate knowledge sharing between tasks. Extensive experiments demonstrate that Diana outperforms state-of-the-art LL models, especially in handling unseen tasks. We release the code and data at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/diana}.
Long-Tailed Question Answering in an Open World
May 11, 2023Real-world data often have an open long-tailed distribution, and building a unified QA model supporting various tasks is vital for practical QA applications. However, it is non-trivial to extend previous QA approaches since they either require access to seen tasks of adequate samples or do not explicitly model samples from unseen tasks. In this paper, we define Open Long-Tailed QA (OLTQA) as learning from long-tailed distributed data and optimizing performance over seen and unseen QA tasks. We propose an OLTQA model that encourages knowledge sharing between head, tail and unseen tasks, and explicitly mines knowledge from a large pre-trained language model (LM). Specifically, we organize our model through a pool of fine-grained components and dynamically combine these components for an input to facilitate knowledge sharing. A retrieve-then-rerank frame is further introduced to select in-context examples, which guild the LM to generate text that express knowledge for QA tasks. Moreover, a two-stage training approach is introduced to pre-train the framework by knowledge distillation (KD) from the LM and then jointly train the frame and a QA model through an adaptive mutual KD method. On a large-scale OLTQA dataset we curate from 43 existing QA datasets, our model consistently outperforms the state-of-the-art. We release the code and data at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/oltqa}.
A Survey on Out-of-Distribution Detection in NLP
May 05, 2023Out-of-distribution (OOD) detection is essential for the reliable and safe deployment of machine learning systems in the real world. Great progress has been made over the past years. This paper presents the first review of recent advances in OOD detection with a particular focus on natural language processing approaches. First, we provide a formal definition of OOD detection and discuss several related fields. We then categorize recent algorithms into three classes according to the data they used: (1) OOD data available, (2) OOD data unavailable + in-distribution (ID) label available, and (3) OOD data unavailable + ID label unavailable. Third, we introduce datasets, applications, and metrics. Finally, we summarize existing work and present potential future research topics.
Out-of-Domain Intent Detection Considering Multi-turn Dialogue Contexts
May 05, 2023



Out-of-Domain (OOD) intent detection is vital for practical dialogue systems, and it usually requires considering multi-turn dialogue contexts. However, most previous OOD intent detection approaches are limited to single dialogue turns. In this paper, we introduce a context-aware OOD intent detection (Caro) framework to model multi-turn contexts in OOD intent detection tasks. Specifically, we follow the information bottleneck principle to extract robust representations from multi-turn dialogue contexts. Two different views are constructed for each input sample and the superfluous information not related to intent detection is removed using a multi-view information bottleneck loss. Moreover, we also explore utilizing unlabeled data in Caro. A two-stage training process is introduced to mine OOD samples from these unlabeled data, and these OOD samples are used to train the resulting model with a bootstrapping approach. Comprehensive experiments demonstrate that Caro establishes state-of-the-art performances on multi-turn OOD detection tasks by improving the F1-OOD score of over $29\%$ compared to the previous best method.
Empathetic Response Generation via Emotion Cause Transition Graph
Feb 23, 2023



Empathetic dialogue is a human-like behavior that requires the perception of both affective factors (e.g., emotion status) and cognitive factors (e.g., cause of the emotion). Besides concerning emotion status in early work, the latest approaches study emotion causes in empathetic dialogue. These approaches focus on understanding and duplicating emotion causes in the context to show empathy for the speaker. However, instead of only repeating the contextual causes, the real empathic response often demonstrate a logical and emotion-centered transition from the causes in the context to those in the responses. In this work, we propose an emotion cause transition graph to explicitly model the natural transition of emotion causes between two adjacent turns in empathetic dialogue. With this graph, the concept words of the emotion causes in the next turn can be predicted and used by a specifically designed concept-aware decoder to generate the empathic response. Automatic and human experimental results on the benchmark dataset demonstrate that our method produces more empathetic, coherent, informative, and specific responses than existing models.
Semi-Supervised Lifelong Language Learning
Nov 23, 2022



Lifelong learning aims to accumulate knowledge and alleviate catastrophic forgetting when learning tasks sequentially. However, existing lifelong language learning methods only focus on the supervised learning setting. Unlabeled data, which can be easily accessed in real-world scenarios, are underexplored. In this paper, we explore a novel setting, semi-supervised lifelong language learning (SSLL), where a model learns sequentially arriving language tasks with both labeled and unlabeled data. We propose an unlabeled data enhanced lifelong learner to explore SSLL. Specially, we dedicate task-specific modules to alleviate catastrophic forgetting and design two modules to exploit unlabeled data: (1) a virtual supervision enhanced task solver is constructed on a teacher-student framework to mine the underlying knowledge from unlabeled data; and (2) a backward augmented learner is built to encourage knowledge transfer from newly arrived unlabeled data to previous tasks. Experimental results on various language tasks demonstrate our model's effectiveness and superiority over competitive baselines under the new setting SSLL.
Estimating Soft Labels for Out-of-Domain Intent Detection
Nov 10, 2022Out-of-Domain (OOD) intent detection is important for practical dialog systems. To alleviate the issue of lacking OOD training samples, some works propose synthesizing pseudo OOD samples and directly assigning one-hot OOD labels to these pseudo samples. However, these one-hot labels introduce noises to the training process because some hard pseudo OOD samples may coincide with In-Domain (IND) intents. In this paper, we propose an adaptive soft pseudo labeling (ASoul) method that can estimate soft labels for pseudo OOD samples when training OOD detectors. Semantic connections between pseudo OOD samples and IND intents are captured using an embedding graph. A co-training framework is further introduced to produce resulting soft labels following the smoothness assumption, i.e., close samples are likely to have similar labels. Extensive experiments on three benchmark datasets show that ASoul consistently improves the OOD detection performance and outperforms various competitive baselines.
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
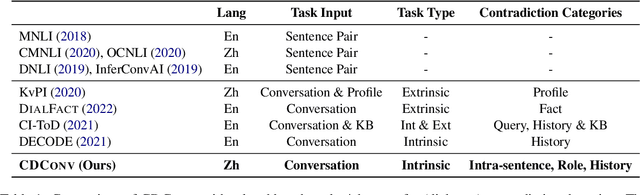

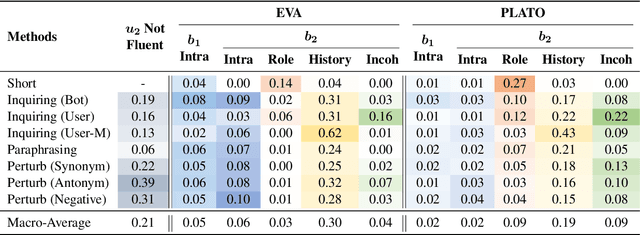
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
Prompt Conditioned VAE: Enhancing Generative Replay for Lifelong Learning in Task-Oriented Dialogue
Oct 14, 2022



Lifelong learning (LL) is vital for advanced task-oriented dialogue (ToD) systems. To address the catastrophic forgetting issue of LL, generative replay methods are widely employed to consolidate past knowledge with generated pseudo samples. However, most existing generative replay methods use only a single task-specific token to control their models. This scheme is usually not strong enough to constrain the generative model due to insufficient information involved. In this paper, we propose a novel method, prompt conditioned VAE for lifelong learning (PCLL), to enhance generative replay by incorporating tasks' statistics. PCLL captures task-specific distributions with a conditional variational autoencoder, conditioned on natural language prompts to guide the pseudo-sample generation. Moreover, it leverages a distillation process to further consolidate past knowledge by alleviating the noise in pseudo samples. Experiments on natural language understanding tasks of ToD systems demonstrate that PCLL significantly outperforms competitive baselines in building LL models.