 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIBench: A Simulator-Based Benchmark and Turn-Credit RL for Emotion Management
Jun 14, 2026Emotional intelligence (EI) in Large Language Models (LLMs) is often evaluated through static understanding tasks or single-response dialogue generation. However, emotion management is interactive: a good model should not only recognize a user's emotion, but also improve the user's emotional and relational state over several turns. We introduce EIBench, a simulator-based benchmark for interactive emotion management. EIBench contains 2,222 scenarios, with 2,009 for training and 213 for held-out testing. The scenarios are organized by a 2x2 taxonomy covering Support, Defense, Repair, and Charm, which together capture different forms of support, boundary maintenance, trust repair, and rapport building. In each scenario, an LLM simulator plays the user, updates an emotion-relation state after each turn, and maps the final state to an anchor-based score. This design makes EIBench both an evaluation benchmark and a training environment: the final state gives the outcome reward, while the per-turn state updates provide dense feedback for RL. We evaluate 15 open- and closed-source LLMs. Current models perform well on support and rapport-building scenes, but struggle with boundary maintenance under user pressure. To improve the EI ability of LLMs, we propose Centered Turn-Credit GRPO (CTC-GRPO), a GRPO extension that reuses the simulator's per-turn state updates as dense turn-level feedback while preserving the final outcome reward. CTC-GRPO improves Qwen3-8B from -22.4 to +22.4 on EIBench and also improves on out-of-distribution evaluations including SAGE (+12.4) and EQBench3 (+20.9%). Our results show that simulator-tracked user states can support both evaluation and training for multi-turn emotion management.
Scaling Self-Evolving Agents via Parametric Memory
Jun 03, 2026Existing memory-augmented LLM agents store past experience exclusively in prompt space, as textual summaries or retrieved passages, while keeping model parameters frozen throughout a rollout. Such agents can \emph{look up} what they have seen but cannot \emph{learn from} it: their policy is unchanged by experience, and any information dropped from the context is permanently lost. We introduce \texttt{TMEM}, a self-evolving parametric memory framework in which the agent not only compresses history into explicit memory but also absorbs distilled supervision into fast LoRA weights $Δ_t$ via lightweight online updates, genuinely altering its future behavior within a single episode. We formalize this as an agentic decision process with fast-weight rollout dynamics: actions are sampled from $π_{θ_0+Δ_t}$, while extraction actions produce supervision that updates $Δ_t$ for subsequent decisions. This view makes the extraction policy directly optimizable by RL: training $θ_0$ improves not only task actions but also the quality of the data used for online LoRA adaptation. We further propose SVD-based initialization of the LoRA subspace to accelerate online convergence. Experiments on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench show that \texttt{TMEM} consistently outperforms summary-based and retrieval-based baselines across different model scales.
P-GenRM: Personalized Generative Reward Model with Test-time User-based Scaling
Feb 12, 2026Personalized alignment of large language models seeks to adapt responses to individual user preferences, typically via reinforcement learning. A key challenge is obtaining accurate, user-specific reward signals in open-ended scenarios. Existing personalized reward models face two persistent limitations: (1) oversimplifying diverse, scenario-specific preferences into a small, fixed set of evaluation principles, and (2) struggling with generalization to new users with limited feedback. To this end, we propose P-GenRM, the first Personalized Generative Reward Model with test-time user-based scaling. P-GenRM transforms preference signals into structured evaluation chains that derive adaptive personas and scoring rubrics across various scenarios. It further clusters users into User Prototypes and introduces a dual-granularity scaling mechanism: at the individual level, it adaptively scales and aggregates each user's scoring scheme; at the prototype level, it incorporates preferences from similar users. This design mitigates noise in inferred preferences and enhances generalization to unseen users through prototype-based transfer. Empirical results show that P-GenRM achieves state-of-the-art results on widely-used personalized reward model benchmarks, with an average improvement of 2.31%, and demonstrates strong generalization on an out-of-distribution dataset. Notably, Test-time User-based scaling provides an additional 3% boost, demonstrating stronger personalized alignment with test-time scalability.
Reward Modeling from Natural Language Human Feedback
Jan 12, 2026Reinforcement Learning with Verifiable reward (RLVR) on preference data has become the mainstream approach for training Generative Reward Models (GRMs). Typically in pairwise rewarding tasks, GRMs generate reasoning chains ending with critiques and preference labels, and RLVR then relies on the correctness of the preference labels as the training reward. However, in this paper, we demonstrate that such binary classification tasks make GRMs susceptible to guessing correct outcomes without sound critiques. Consequently, these spurious successes introduce substantial noise into the reward signal, thereby impairing the effectiveness of reinforcement learning. To address this issue, we propose Reward Modeling from Natural Language Human Feedback (RM-NLHF), which leverages natural language feedback to obtain process reward signals, thereby mitigating the problem of limited solution space inherent in binary tasks. Specifically, we compute the similarity between GRM-generated and human critiques as the training reward, which provides more accurate reward signals than outcome-only supervision. Additionally, considering that human critiques are difficult to scale up, we introduce Meta Reward Model (MetaRM) which learns to predict process reward from datasets with human critiques and then generalizes to data without human critiques. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art GRMs trained with outcome-only reward, confirming the superiority of integrating natural language over binary human feedback as supervision.
MOA: Multi-Objective Alignment for Role-Playing Agents
Dec 10, 2025Role-playing agents (RPAs) must simultaneously master many conflicting skills -- following multi-turn instructions, exhibiting domain knowledge, and adopting a consistent linguistic style. Existing work either relies on supervised fine-tuning (SFT) that over-fits surface cues and yields low diversity, or applies reinforcement learning (RL) that fails to learn multiple dimensions for comprehensive RPA optimization. We present MOA (Multi-Objective Alignment), a reinforcement-learning framework that enables multi-dimensional, fine-grained rubric optimization for general RPAs. MOA introduces a novel multi-objective optimization strategy that trains simultaneously on multiple fine-grained rubrics to boost optimization performance. Besides, to address the issues of model output diversity and quality, we have also employed thought-augmented rollout with off-policy guidance. Extensive experiments on challenging benchmarks such as PersonaGym and RoleMRC show that MOA enables an 8B model to match or even outperform strong baselines such as GPT-4o and Claude across numerous dimensions. This demonstrates the great potential of MOA in building RPAs that can simultaneously meet the demands of role knowledge, persona style, diverse scenarios, and complex multi-turn conversations.
CPO: Addressing Reward Ambiguity in Role-playing Dialogue via Comparative Policy Optimization
Aug 12, 2025Reinforcement Learning Fine-Tuning (RLFT) has achieved notable success in tasks with objectively verifiable answers (e.g., code generation, mathematical reasoning), yet struggles with open-ended subjective tasks like role-playing dialogue. Traditional reward modeling approaches, which rely on independent sample-wise scoring, face dual challenges: subjective evaluation criteria and unstable reward signals.Motivated by the insight that human evaluation inherently combines explicit criteria with implicit comparative judgments, we propose Comparative Policy Optimization (CPO). CPO redefines the reward evaluation paradigm by shifting from sample-wise scoring to comparative group-wise scoring.Building on the same principle, we introduce the CharacterArena evaluation framework, which comprises two stages:(1) Contextualized Multi-turn Role-playing Simulation, and (2) Trajectory-level Comparative Evaluation. By operationalizing subjective scoring via objective trajectory comparisons, CharacterArena minimizes contextual bias and enables more robust and fair performance evaluation. Empirical results on CharacterEval, CharacterBench, and CharacterArena confirm that CPO effectively mitigates reward ambiguity and leads to substantial improvements in dialogue quality.
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025
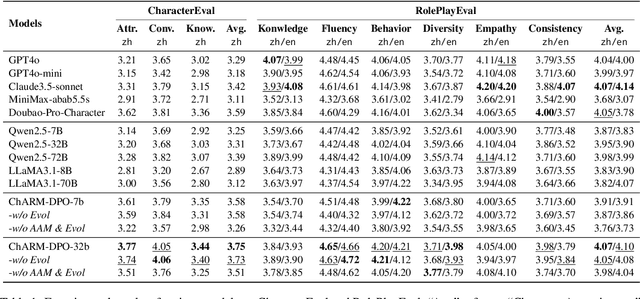
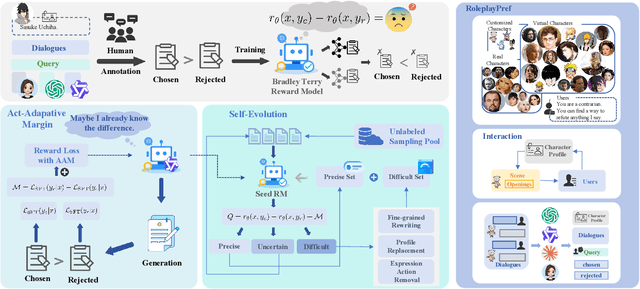
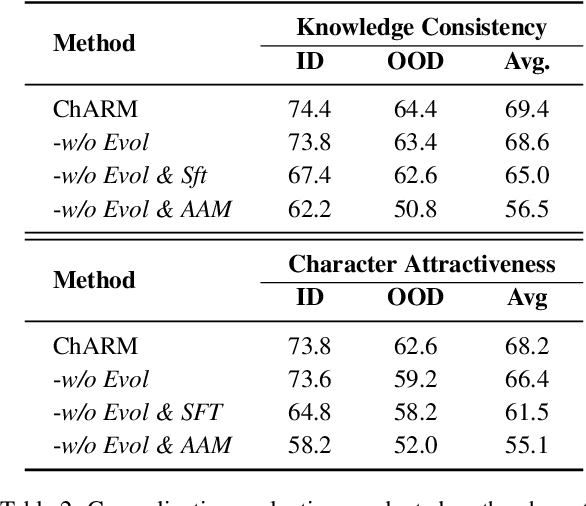
Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.
Reverse Preference Optimization for Complex Instruction Following
May 28, 2025Instruction following (IF) is a critical capability for large language models (LLMs). However, handling complex instructions with multiple constraints remains challenging. Previous methods typically select preference pairs based on the number of constraints they satisfy, introducing noise where chosen examples may fail to follow some constraints and rejected examples may excel in certain respects over the chosen ones. To address the challenge of aligning with multiple preferences, we propose a simple yet effective method called Reverse Preference Optimization (RPO). It mitigates noise in preference pairs by dynamically reversing the constraints within the instruction to ensure the chosen response is perfect, alleviating the burden of extensive sampling and filtering to collect perfect responses. Besides, reversal also enlarges the gap between chosen and rejected responses, thereby clarifying the optimization direction and making it more robust to noise. We evaluate RPO on two multi-turn IF benchmarks, Sysbench and Multi-IF, demonstrating average improvements over the DPO baseline of 4.6 and 2.5 points (on Llama-3.1 8B), respectively. Moreover, RPO scales effectively across model sizes (8B to 70B parameters), with the 70B RPO model surpassing GPT-4o.
OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
May 26, 2025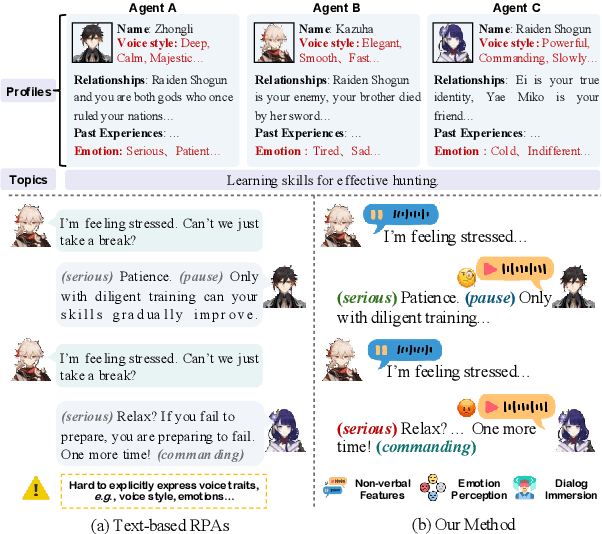



Role-Playing Agents (RPAs), benefiting from large language models, is an emerging interactive AI system that simulates roles or characters with diverse personalities. However, existing methods primarily focus on mimicking dialogues among roles in textual form, neglecting the role's voice traits (e.g., voice style and emotions) as playing a crucial effect in interaction, which tends to be more immersive experiences in realistic scenarios. Towards this goal, we propose OmniCharacter, a first seamless speech-language personality interaction model to achieve immersive RPAs with low latency. Specifically, OmniCharacter enables agents to consistently exhibit role-specific personality traits and vocal traits throughout the interaction, enabling a mixture of speech and language responses. To align the model with speech-language scenarios, we construct a dataset named OmniCharacter-10K, which involves more distinctive characters (20), richly contextualized multi-round dialogue (10K), and dynamic speech response (135K). Experimental results showcase that our method yields better responses in terms of both content and style compared to existing RPAs and mainstream speech-language models, with a response latency as low as 289ms. Code and dataset are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/OmniCharacter.