 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniOVCD: Streamlining Open-Vocabulary Change Detection with SAM 3
Jan 20, 2026Change Detection (CD) is a fundamental task in remote sensing. It monitors the evolution of land cover over time. Based on this, Open-Vocabulary Change Detection (OVCD) introduces a new requirement. It aims to reduce the reliance on predefined categories. Existing training-free OVCD methods mostly use CLIP to identify categories. These methods also need extra models like DINO to extract features. However, combining different models often causes problems in matching features and makes the system unstable. Recently, the Segment Anything Model 3 (SAM 3) is introduced. It integrates segmentation and identification capabilities within one promptable model, which offers new possibilities for the OVCD task. In this paper, we propose OmniOVCD, a standalone framework designed for OVCD. By leveraging the decoupled output heads of SAM 3, we propose a Synergistic Fusion to Instance Decoupling (SFID) strategy. SFID first fuses the semantic, instance, and presence outputs of SAM 3 to construct land-cover masks, and then decomposes them into individual instance masks for change comparison. This design preserves high accuracy in category recognition and maintains instance-level consistency across images. As a result, the model can generate accurate change masks. Experiments on four public benchmarks (LEVIR-CD, WHU-CD, S2Looking, and SECOND) demonstrate SOTA performance, achieving IoU scores of 67.2, 66.5, 24.5, and 27.1 (class-average), respectively, surpassing all previous methods.
Mind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
Sep 18, 2025Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to high variance and training instability. Existing approaches mitigate this issue using KL penalties or clipping, which passively constrain updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap by keeping correct solutions as on-policy data and rewriting incorrect ones with guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy before optimization, reducing importance sampling variance and stabilizing off-policy fine-tuning. Experiments on five mathematical reasoning benchmarks demonstrate consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. The data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.
Cross-Modal Knowledge Distillation for Speech Large Language Models
Sep 18, 2025In this work, we present the first systematic evaluation of catastrophic forgetting and modality inequivalence in speech large language models, showing that introducing speech capabilities can degrade knowledge and reasoning even when inputs remain textual, and performance further decreases with spoken queries. To address these challenges, we propose a cross-modal knowledge distillation framework that leverages both text-to-text and speech-to-text channels to transfer knowledge from a text-based teacher model to a speech LLM. Extensive experiments on dialogue and audio understanding tasks validate the effectiveness of our approach in preserving textual knowledge, improving cross-modal alignment, and enhancing reasoning in speech-based interactions.
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Jan 03, 2025



Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goal-oriented social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across a variety of agent tasks. Existing DPO-based approaches for multi-turn interactions are divided into turn-level and session-level methods. The turn-level method is overly fine-grained, focusing exclusively on individual turns, while session-level methods are too coarse-grained, often introducing training noise. To address these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which focuses on specific key segments within interactions to optimize multi-turn agent behavior while minimizing training noise. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO's potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
Self-Prompt Tuning: Enable Autonomous Role-Playing in LLMs
Jul 12, 2024



Recent advancements in LLMs have showcased their remarkable role-playing capabilities, able to accurately simulate the dialogue styles and cognitive processes of various roles based on different instructions and contexts. Studies indicate that assigning LLMs the roles of experts, a strategy known as role-play prompting, can enhance their performance in the corresponding domains. However, the prompt needs to be manually designed for the given problem, requiring certain expertise and iterative modifications. To this end, we propose self-prompt tuning, making LLMs themselves generate role-play prompts through fine-tuning. Leveraging the LIMA dataset as our foundational corpus, we employ GPT-4 to annotate role-play prompts for each data points, resulting in the creation of the LIMA-Role dataset. We then fine-tune LLMs like Llama-2-7B and Mistral-7B on LIMA-Role. Consequently, the self-prompt tuned LLMs can automatically generate expert role prompts for any given question. We extensively evaluate self-prompt tuned LLMs on widely used NLP benchmarks and open-ended question test. Our empirical results illustrate that self-prompt tuned LLMs outperform standard instruction tuned baselines across most datasets. This highlights the great potential of utilizing fine-tuning to enable LLMs to self-prompt, thereby automating complex prompting strategies. We release the dataset, models, and code at this \href{https://anonymous.4open.science/r/Self-Prompt-Tuning-739E/}{url}.
Better Zero-Shot Reasoning with Role-Play Prompting
Aug 15, 2023



Modern large language models (LLMs), such as ChatGPT, exhibit a remarkable capacity for role-playing, enabling them to embody not only human characters but also non-human entities like a Linux terminal. This versatility allows them to simulate complex human-like interactions and behaviors within various contexts, as well as to emulate specific objects or systems. While these capabilities have enhanced user engagement and introduced novel modes of interaction, the influence of role-playing on LLMs' reasoning abilities remains underexplored. In this study, we introduce a strategically designed role-play prompting methodology and assess its performance under the zero-shot setting across twelve diverse reasoning benchmarks, encompassing arithmetic, commonsense reasoning, symbolic reasoning, and more. Leveraging models such as ChatGPT and Llama 2, our empirical results illustrate that role-play prompting consistently surpasses the standard zero-shot approach across most datasets. Notably, accuracy on AQuA rises from 53.5% to 63.8%, and on Last Letter from 23.8% to 84.2%. Beyond enhancing contextual understanding, we posit that role-play prompting serves as an implicit Chain-of-Thought (CoT) trigger, thereby improving the quality of reasoning. By comparing our approach with the Zero-Shot-CoT technique, which prompts the model to "think step by step", we further demonstrate that role-play prompting can generate a more effective CoT. This highlights its potential to augment the reasoning capabilities of LLMs.
PromptRank: Unsupervised Keyphrase Extraction Using Prompt
May 15, 2023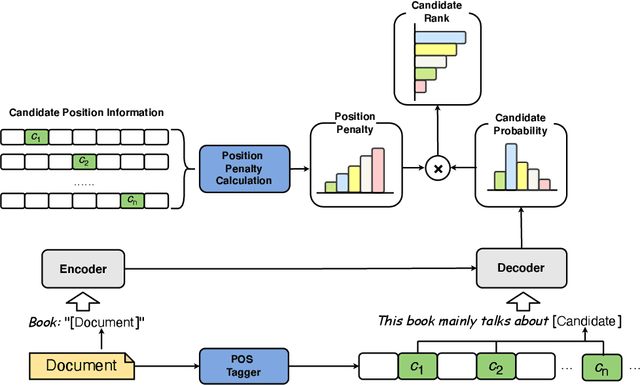



The keyphrase extraction task refers to the automatic selection of phrases from a given document to summarize its core content. State-of-the-art (SOTA) performance has recently been achieved by embedding-based algorithms, which rank candidates according to how similar their embeddings are to document embeddings. However, such solutions either struggle with the document and candidate length discrepancies or fail to fully utilize the pre-trained language model (PLM) without further fine-tuning. To this end, in this paper, we propose a simple yet effective unsupervised approach, PromptRank, based on the PLM with an encoder-decoder architecture. Specifically, PromptRank feeds the document into the encoder and calculates the probability of generating the candidate with a designed prompt by the decoder. We extensively evaluate the proposed PromptRank on six widely used benchmarks. PromptRank outperforms the SOTA approach MDERank, improving the F1 score relatively by 34.18%, 24.87%, and 17.57% for 5, 10, and 15 returned results, respectively. This demonstrates the great potential of using prompt for unsupervised keyphrase extraction. We release our code at https://github.com/HLT-NLP/PromptRank.
CyFormer: Accurate State-of-Health Prediction of Lithium-Ion Batteries via Cyclic Attention
Apr 17, 2023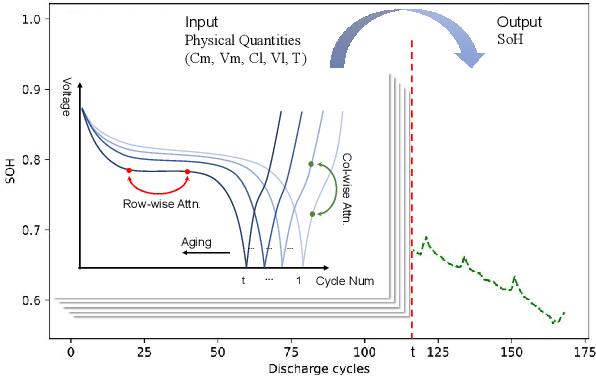
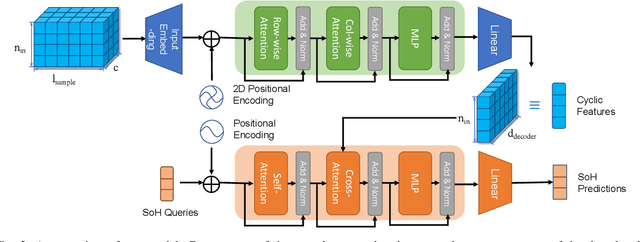
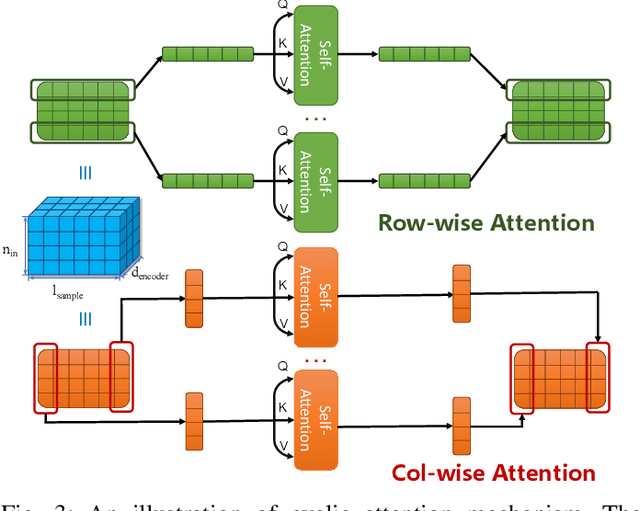
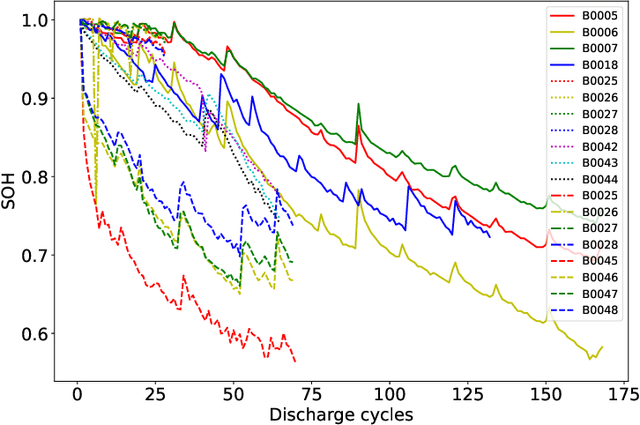
Predicting the State-of-Health (SoH) of lithium-ion batteries is a fundamental task of battery management systems on electric vehicles. It aims at estimating future SoH based on historical aging data. Most existing deep learning methods rely on filter-based feature extractors (e.g., CNN or Kalman filters) and recurrent time sequence models. Though efficient, they generally ignore cyclic features and the domain gap between training and testing batteries. To address this problem, we present CyFormer, a transformer-based cyclic time sequence model for SoH prediction. Instead of the conventional CNN-RNN structure, we adopt an encoder-decoder architecture. In the encoder, row-wise and column-wise attention blocks effectively capture intra-cycle and inter-cycle connections and extract cyclic features. In the decoder, the SoH queries cross-attend to these features to form the final predictions. We further utilize a transfer learning strategy to narrow the domain gap between the training and testing set. To be specific, we use fine-tuning to shift the model to a target working condition. Finally, we made our model more efficient by pruning. The experiment shows that our method attains an MAE of 0.75\% with only 10\% data for fine-tuning on a testing battery, surpassing prior methods by a large margin. Effective and robust, our method provides a potential solution for all cyclic time sequence prediction tasks.