 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
Jan 30, 2026Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.
Mind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
Sep 18, 2025Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to high variance and training instability. Existing approaches mitigate this issue using KL penalties or clipping, which passively constrain updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap by keeping correct solutions as on-policy data and rewriting incorrect ones with guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy before optimization, reducing importance sampling variance and stabilizing off-policy fine-tuning. Experiments on five mathematical reasoning benchmarks demonstrate consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. The data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
RA-CLAP: Relation-Augmented Emotional Speaking Style Contrastive Language-Audio Pretraining For Speech Retrieval
May 26, 2025The Contrastive Language-Audio Pretraining (CLAP) model has demonstrated excellent performance in general audio description-related tasks, such as audio retrieval. However, in the emerging field of emotional speaking style description (ESSD), cross-modal contrastive pretraining remains largely unexplored. In this paper, we propose a novel speech retrieval task called emotional speaking style retrieval (ESSR), and ESS-CLAP, an emotional speaking style CLAP model tailored for learning relationship between speech and natural language descriptions. In addition, we further propose relation-augmented CLAP (RA-CLAP) to address the limitation of traditional methods that assume a strict binary relationship between caption and audio. The model leverages self-distillation to learn the potential local matching relationships between speech and descriptions, thereby enhancing generalization ability. The experimental results validate the effectiveness of RA-CLAP, providing valuable reference in ESSD.
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Feb 26, 2025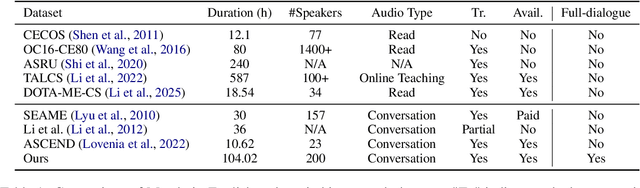



Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.
MusicEval: A Generative Music Corpus with Expert Ratings for Automatic Text-to-Music Evaluation
Jan 18, 2025



The technology for generating music from textual descriptions has seen rapid advancements. However, evaluating text-to-music (TTM) systems remains a significant challenge, primarily due to the difficulty of balancing performance and cost with existing objective and subjective evaluation methods. In this paper, we propose an automatic assessment task for TTM models to align with human perception. To address the TTM evaluation challenges posed by the professional requirements of music evaluation and the complexity of the relationship between text and music, we collect MusicEval, the first generative music assessment dataset. This dataset contains 2,748 music clips generated by 31 advanced and widely used models in response to 384 text prompts, along with 13,740 ratings from 14 music experts. Furthermore, we design a CLAP-based assessment model built on this dataset, and our experimental results validate the feasibility of the proposed task, providing a valuable reference for future development in TTM evaluation. The dataset is available at https://www.aishelltech.com/AISHELL_7A.
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Jan 03, 2025



Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goal-oriented social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across a variety of agent tasks. Existing DPO-based approaches for multi-turn interactions are divided into turn-level and session-level methods. The turn-level method is overly fine-grained, focusing exclusively on individual turns, while session-level methods are too coarse-grained, often introducing training noise. To address these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which focuses on specific key segments within interactions to optimize multi-turn agent behavior while minimizing training noise. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO's potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
Enhancing Multimodal Emotion Recognition through Multi-Granularity Cross-Modal Alignment
Dec 30, 2024Multimodal emotion recognition (MER), leveraging speech and text, has emerged as a pivotal domain within human-computer interaction, demanding sophisticated methods for effective multimodal integration. The challenge of aligning features across these modalities is significant, with most existing approaches adopting a singular alignment strategy. Such a narrow focus not only limits model performance but also fails to address the complexity and ambiguity inherent in emotional expressions. In response, this paper introduces a Multi-Granularity Cross-Modal Alignment (MGCMA) framework, distinguished by its comprehensive approach encompassing distribution-based, instance-based, and token-based alignment modules. This framework enables a multi-level perception of emotional information across modalities. Our experiments on IEMOCAP demonstrate that our proposed method outperforms current state-of-the-art techniques.
ChildMandarin: A Comprehensive Mandarin Speech Dataset for Young Children Aged 3-5
Sep 27, 2024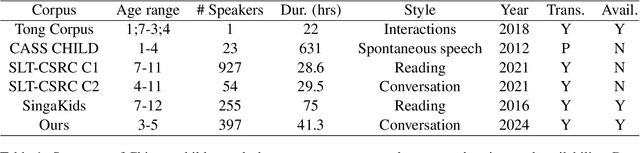

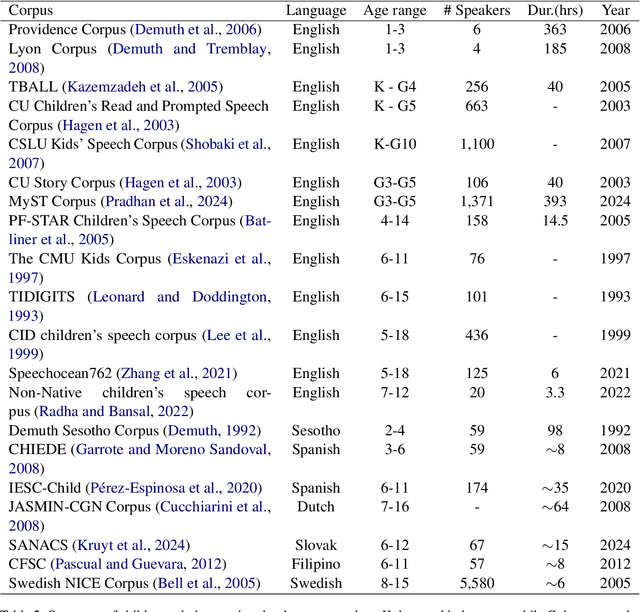
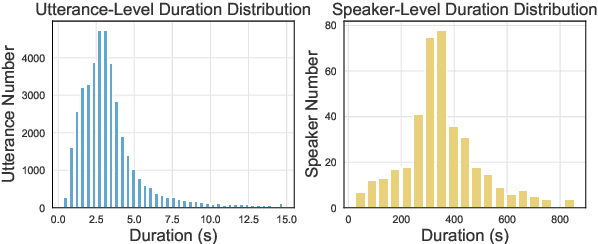
Automatic speech recognition (ASR) systems have advanced significantly with models like Whisper, Conformer, and self-supervised frameworks such as Wav2vec 2.0 and HuBERT. However, developing robust ASR models for young children's speech remains challenging due to differences in pronunciation, tone, and pace compared to adult speech. In this paper, we introduce a new Mandarin speech dataset focused on children aged 3 to 5, addressing the scarcity of resources in this area. The dataset comprises 41.25 hours of speech with carefully crafted manual transcriptions, collected from 397 speakers across various provinces in China, with balanced gender representation. We provide a comprehensive analysis of speaker demographics, speech duration distribution and geographic coverage. Additionally, we evaluate ASR performance on models trained from scratch, such as Conformer, as well as fine-tuned pre-trained models like HuBERT and Whisper, where fine-tuning demonstrates significant performance improvements. Furthermore, we assess speaker verification (SV) on our dataset, showing that, despite the challenges posed by the unique vocal characteristics of young children, the dataset effectively supports both ASR and SV tasks. This dataset is a valuable contribution to Mandarin child speech research and holds potential for applications in educational technology and child-computer interaction. It will be open-source and freely available for all academic purposes.
M2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Sep 18, 2024



State-of-the-art models like OpenAI's Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.