 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Mind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
Sep 18, 2025Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to high variance and training instability. Existing approaches mitigate this issue using KL penalties or clipping, which passively constrain updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap by keeping correct solutions as on-policy data and rewriting incorrect ones with guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy before optimization, reducing importance sampling variance and stabilizing off-policy fine-tuning. Experiments on five mathematical reasoning benchmarks demonstrate consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. The data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Feb 26, 2025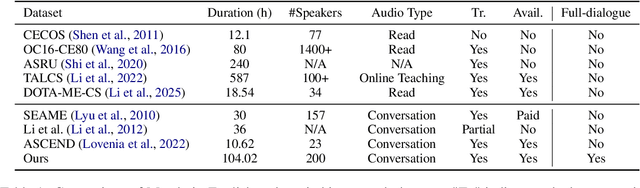



Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Feb 18, 2025
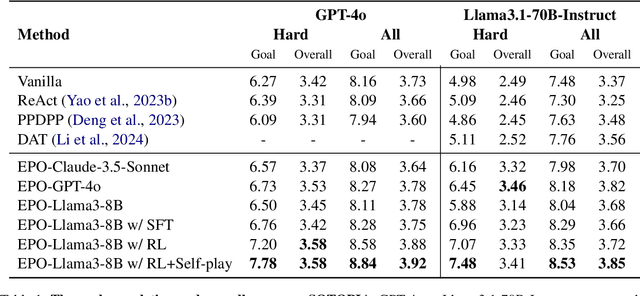
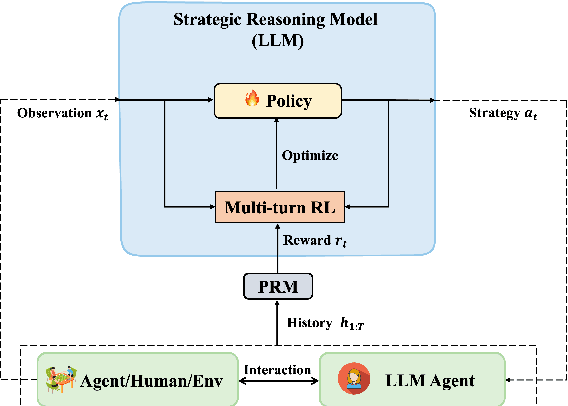
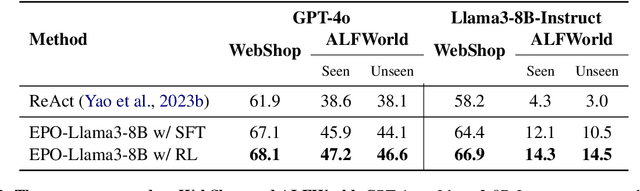
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO's ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Jan 03, 2025



Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goal-oriented social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across a variety of agent tasks. Existing DPO-based approaches for multi-turn interactions are divided into turn-level and session-level methods. The turn-level method is overly fine-grained, focusing exclusively on individual turns, while session-level methods are too coarse-grained, often introducing training noise. To address these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which focuses on specific key segments within interactions to optimize multi-turn agent behavior while minimizing training noise. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO's potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
ChildMandarin: A Comprehensive Mandarin Speech Dataset for Young Children Aged 3-5
Sep 27, 2024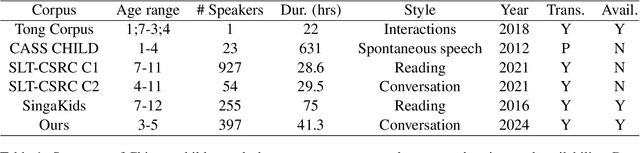

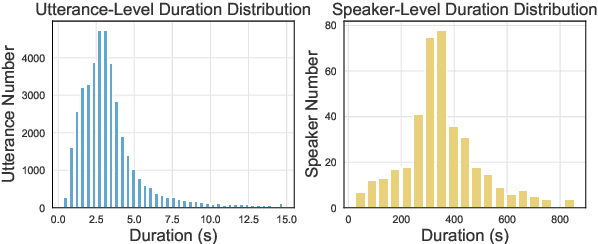
Automatic speech recognition (ASR) systems have advanced significantly with models like Whisper, Conformer, and self-supervised frameworks such as Wav2vec 2.0 and HuBERT. However, developing robust ASR models for young children's speech remains challenging due to differences in pronunciation, tone, and pace compared to adult speech. In this paper, we introduce a new Mandarin speech dataset focused on children aged 3 to 5, addressing the scarcity of resources in this area. The dataset comprises 41.25 hours of speech with carefully crafted manual transcriptions, collected from 397 speakers across various provinces in China, with balanced gender representation. We provide a comprehensive analysis of speaker demographics, speech duration distribution and geographic coverage. Additionally, we evaluate ASR performance on models trained from scratch, such as Conformer, as well as fine-tuned pre-trained models like HuBERT and Whisper, where fine-tuning demonstrates significant performance improvements. Furthermore, we assess speaker verification (SV) on our dataset, showing that, despite the challenges posed by the unique vocal characteristics of young children, the dataset effectively supports both ASR and SV tasks. This dataset is a valuable contribution to Mandarin child speech research and holds potential for applications in educational technology and child-computer interaction. It will be open-source and freely available for all academic purposes.
M2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Sep 18, 2024



State-of-the-art models like OpenAI's Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.
Enhancing Dysarthric Speech Recognition for Unseen Speakers via Prototype-Based Adaptation
Jul 26, 2024



Dysarthric speech recognition (DSR) presents a formidable challenge due to inherent inter-speaker variability, leading to severe performance degradation when applying DSR models to new dysarthric speakers. Traditional speaker adaptation methodologies typically involve fine-tuning models for each speaker, but this strategy is cost-prohibitive and inconvenient for disabled users, requiring substantial data collection. To address this issue, we introduce a prototype-based approach that markedly improves DSR performance for unseen dysarthric speakers without additional fine-tuning. Our method employs a feature extractor trained with HuBERT to produce per-word prototypes that encapsulate the characteristics of previously unseen speakers. These prototypes serve as the basis for classification. Additionally, we incorporate supervised contrastive learning to refine feature extraction. By enhancing representation quality, we further improve DSR performance, enabling effective personalized DSR. We release our code at https://github.com/NKU-HLT/PB-DSR.
* accepted by Interspeech 2024
Enhancing Emotion Recognition in Incomplete Data: A Novel Cross-Modal Alignment, Reconstruction, and Refinement Framework
Jul 12, 2024


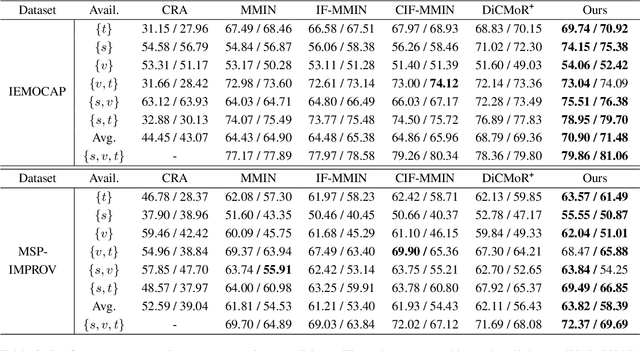
Multimodal emotion recognition systems rely heavily on the full availability of modalities, suffering significant performance declines when modal data is incomplete. To tackle this issue, we present the Cross-Modal Alignment, Reconstruction, and Refinement (CM-ARR) framework, an innovative approach that sequentially engages in cross-modal alignment, reconstruction, and refinement phases to handle missing modalities and enhance emotion recognition. This framework utilizes unsupervised distribution-based contrastive learning to align heterogeneous modal distributions, reducing discrepancies and modeling semantic uncertainty effectively. The reconstruction phase applies normalizing flow models to transform these aligned distributions and recover missing modalities. The refinement phase employs supervised point-based contrastive learning to disrupt semantic correlations and accentuate emotional traits, thereby enriching the affective content of the reconstructed representations. Extensive experiments on the IEMOCAP and MSP-IMPROV datasets confirm the superior performance of CM-ARR under conditions of both missing and complete modalities. Notably, averaged across six scenarios of missing modalities, CM-ARR achieves absolute improvements of 2.11% in WAR and 2.12% in UAR on the IEMOCAP dataset, and 1.71% and 1.96% in WAR and UAR, respectively, on the MSP-IMPROV dataset.
Self-Prompt Tuning: Enable Autonomous Role-Playing in LLMs
Jul 12, 2024



Recent advancements in LLMs have showcased their remarkable role-playing capabilities, able to accurately simulate the dialogue styles and cognitive processes of various roles based on different instructions and contexts. Studies indicate that assigning LLMs the roles of experts, a strategy known as role-play prompting, can enhance their performance in the corresponding domains. However, the prompt needs to be manually designed for the given problem, requiring certain expertise and iterative modifications. To this end, we propose self-prompt tuning, making LLMs themselves generate role-play prompts through fine-tuning. Leveraging the LIMA dataset as our foundational corpus, we employ GPT-4 to annotate role-play prompts for each data points, resulting in the creation of the LIMA-Role dataset. We then fine-tune LLMs like Llama-2-7B and Mistral-7B on LIMA-Role. Consequently, the self-prompt tuned LLMs can automatically generate expert role prompts for any given question. We extensively evaluate self-prompt tuned LLMs on widely used NLP benchmarks and open-ended question test. Our empirical results illustrate that self-prompt tuned LLMs outperform standard instruction tuned baselines across most datasets. This highlights the great potential of utilizing fine-tuning to enable LLMs to self-prompt, thereby automating complex prompting strategies. We release the dataset, models, and code at this \href{https://anonymous.4open.science/r/Self-Prompt-Tuning-739E/}{url}.