 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Emotion Recognition through Multi-Granularity Cross-Modal Alignment
Dec 30, 2024Multimodal emotion recognition (MER), leveraging speech and text, has emerged as a pivotal domain within human-computer interaction, demanding sophisticated methods for effective multimodal integration. The challenge of aligning features across these modalities is significant, with most existing approaches adopting a singular alignment strategy. Such a narrow focus not only limits model performance but also fails to address the complexity and ambiguity inherent in emotional expressions. In response, this paper introduces a Multi-Granularity Cross-Modal Alignment (MGCMA) framework, distinguished by its comprehensive approach encompassing distribution-based, instance-based, and token-based alignment modules. This framework enables a multi-level perception of emotional information across modalities. Our experiments on IEMOCAP demonstrate that our proposed method outperforms current state-of-the-art techniques.
Uncertainty-Aware Mean Opinion Score Prediction
Aug 23, 2024Mean Opinion Score (MOS) prediction has made significant progress in specific domains. However, the unstable performance of MOS prediction models across diverse samples presents ongoing challenges in the practical application of these systems. In this paper, we point out that the absence of uncertainty modeling is a significant limitation hindering MOS prediction systems from applying to the real and open world. We analyze the sources of uncertainty in the MOS prediction task and propose to establish an uncertainty-aware MOS prediction system that models aleatory uncertainty and epistemic uncertainty by heteroscedastic regression and Monte Carlo dropout separately. The experimental results show that the system captures uncertainty well and is capable of performing selective prediction and out-of-domain detection. Such capabilities significantly enhance the practical utility of MOS systems in diverse real and open-world environments.
Iterative Prototype Refinement for Ambiguous Speech Emotion Recognition
Aug 01, 2024



Recognizing emotions from speech is a daunting task due to the subtlety and ambiguity of expressions. Traditional speech emotion recognition (SER) systems, which typically rely on a singular, precise emotion label, struggle with this complexity. Therefore, modeling the inherent ambiguity of emotions is an urgent problem. In this paper, we propose an iterative prototype refinement framework (IPR) for ambiguous SER. IPR comprises two interlinked components: contrastive learning and class prototypes. The former provides an efficient way to obtain high-quality representations of ambiguous samples. The latter are dynamically updated based on ambiguous labels -- the similarity of the ambiguous data to all prototypes. These refined embeddings yield precise pseudo labels, thus reinforcing representation quality. Experimental evaluations conducted on the IEMOCAP dataset validate the superior performance of IPR over state-of-the-art methods, thus proving the effectiveness of our proposed method.
Enhancing Emotion Recognition in Incomplete Data: A Novel Cross-Modal Alignment, Reconstruction, and Refinement Framework
Jul 12, 2024


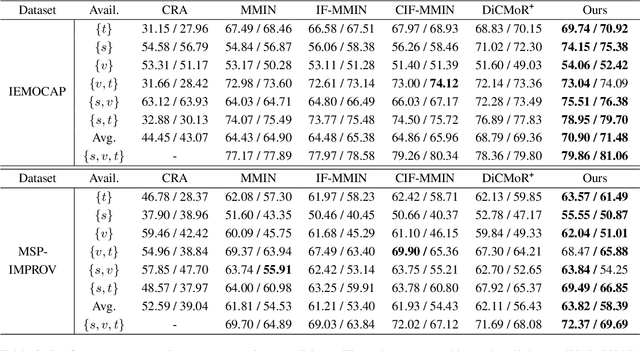
Multimodal emotion recognition systems rely heavily on the full availability of modalities, suffering significant performance declines when modal data is incomplete. To tackle this issue, we present the Cross-Modal Alignment, Reconstruction, and Refinement (CM-ARR) framework, an innovative approach that sequentially engages in cross-modal alignment, reconstruction, and refinement phases to handle missing modalities and enhance emotion recognition. This framework utilizes unsupervised distribution-based contrastive learning to align heterogeneous modal distributions, reducing discrepancies and modeling semantic uncertainty effectively. The reconstruction phase applies normalizing flow models to transform these aligned distributions and recover missing modalities. The refinement phase employs supervised point-based contrastive learning to disrupt semantic correlations and accentuate emotional traits, thereby enriching the affective content of the reconstructed representations. Extensive experiments on the IEMOCAP and MSP-IMPROV datasets confirm the superior performance of CM-ARR under conditions of both missing and complete modalities. Notably, averaged across six scenarios of missing modalities, CM-ARR achieves absolute improvements of 2.11% in WAR and 2.12% in UAR on the IEMOCAP dataset, and 1.71% and 1.96% in WAR and UAR, respectively, on the MSP-IMPROV dataset.
Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Jun 06, 2024



The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
Fine-grained Disentangled Representation Learning for Multimodal Emotion Recognition
Dec 21, 2023

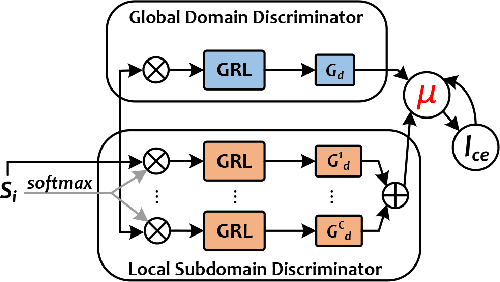

Multimodal emotion recognition (MMER) is an active research field that aims to accurately recognize human emotions by fusing multiple perceptual modalities. However, inherent heterogeneity across modalities introduces distribution gaps and information redundancy, posing significant challenges for MMER. In this paper, we propose a novel fine-grained disentangled representation learning (FDRL) framework to address these challenges. Specifically, we design modality-shared and modality-private encoders to project each modality into modality-shared and modality-private subspaces, respectively. In the shared subspace, we introduce a fine-grained alignment component to learn modality-shared representations, thus capturing modal consistency. Subsequently, we tailor a fine-grained disparity component to constrain the private subspaces, thereby learning modality-private representations and enhancing their diversity. Lastly, we introduce a fine-grained predictor component to ensure that the labels of the output representations from the encoders remain unchanged. Experimental results on the IEMOCAP dataset show that FDRL outperforms the state-of-the-art methods, achieving 78.34% and 79.44% on WAR and UAR, respectively.
Supervised Contrastive Learning with Nearest Neighbor Search for Speech Emotion Recognition
Aug 31, 2023



Speech Emotion Recognition (SER) is a challenging task due to limited data and blurred boundaries of certain emotions. In this paper, we present a comprehensive approach to improve the SER performance throughout the model lifecycle, including pre-training, fine-tuning, and inference stages. To address the data scarcity issue, we utilize a pre-trained model, wav2vec2.0. During fine-tuning, we propose a novel loss function that combines cross-entropy loss with supervised contrastive learning loss to improve the model's discriminative ability. This approach increases the inter-class distances and decreases the intra-class distances, mitigating the issue of blurred boundaries. Finally, to leverage the improved distances, we propose an interpolation method at the inference stage that combines the model prediction with the output from a k-nearest neighbors model. Our experiments on IEMOCAP demonstrate that our proposed methods outperform current state-of-the-art results.
* Accepted by lnterspeech 2023, poster