 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Sep 18, 2024



State-of-the-art models like OpenAI's Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.
Enhancing Emotion Recognition in Incomplete Data: A Novel Cross-Modal Alignment, Reconstruction, and Refinement Framework
Jul 12, 2024


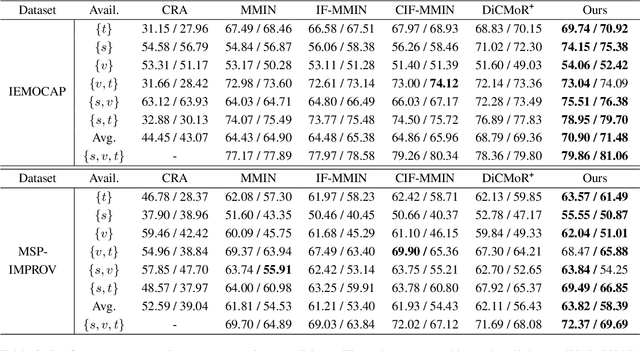
Multimodal emotion recognition systems rely heavily on the full availability of modalities, suffering significant performance declines when modal data is incomplete. To tackle this issue, we present the Cross-Modal Alignment, Reconstruction, and Refinement (CM-ARR) framework, an innovative approach that sequentially engages in cross-modal alignment, reconstruction, and refinement phases to handle missing modalities and enhance emotion recognition. This framework utilizes unsupervised distribution-based contrastive learning to align heterogeneous modal distributions, reducing discrepancies and modeling semantic uncertainty effectively. The reconstruction phase applies normalizing flow models to transform these aligned distributions and recover missing modalities. The refinement phase employs supervised point-based contrastive learning to disrupt semantic correlations and accentuate emotional traits, thereby enriching the affective content of the reconstructed representations. Extensive experiments on the IEMOCAP and MSP-IMPROV datasets confirm the superior performance of CM-ARR under conditions of both missing and complete modalities. Notably, averaged across six scenarios of missing modalities, CM-ARR achieves absolute improvements of 2.11% in WAR and 2.12% in UAR on the IEMOCAP dataset, and 1.71% and 1.96% in WAR and UAR, respectively, on the MSP-IMPROV dataset.
Fine-grained Disentangled Representation Learning for Multimodal Emotion Recognition
Dec 21, 2023

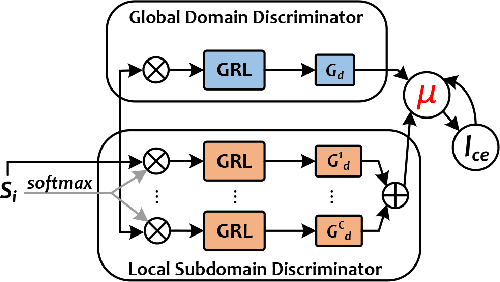

Multimodal emotion recognition (MMER) is an active research field that aims to accurately recognize human emotions by fusing multiple perceptual modalities. However, inherent heterogeneity across modalities introduces distribution gaps and information redundancy, posing significant challenges for MMER. In this paper, we propose a novel fine-grained disentangled representation learning (FDRL) framework to address these challenges. Specifically, we design modality-shared and modality-private encoders to project each modality into modality-shared and modality-private subspaces, respectively. In the shared subspace, we introduce a fine-grained alignment component to learn modality-shared representations, thus capturing modal consistency. Subsequently, we tailor a fine-grained disparity component to constrain the private subspaces, thereby learning modality-private representations and enhancing their diversity. Lastly, we introduce a fine-grained predictor component to ensure that the labels of the output representations from the encoders remain unchanged. Experimental results on the IEMOCAP dataset show that FDRL outperforms the state-of-the-art methods, achieving 78.34% and 79.44% on WAR and UAR, respectively.
kNN-CTC: Enhancing ASR via Retrieval of CTC Pseudo Labels
Dec 21, 2023The success of retrieval-augmented language models in various natural language processing (NLP) tasks has been constrained in automatic speech recognition (ASR) applications due to challenges in constructing fine-grained audio-text datastores. This paper presents kNN-CTC, a novel approach that overcomes these challenges by leveraging Connectionist Temporal Classification (CTC) pseudo labels to establish frame-level audio-text key-value pairs, circumventing the need for precise ground truth alignments. We further introduce a skip-blank strategy, which strategically ignores CTC blank frames, to reduce datastore size. kNN-CTC incorporates a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems, achieving significant improvements in performance. By incorporating a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems and leveraging a fine-grained, pruned datastore, kNN-CTC consistently achieves substantial improvements in performance under various experimental settings. Our code is available at https://github.com/NKU-HLT/KNN-CTC.