 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning
Apr 09, 2026Post-training has become central to turning pretrained large language models (LLMs) into aligned and deployable systems. Recent progress spans supervised fine-tuning (SFT), preference optimization, reinforcement learning (RL), process supervision, verifier-guided methods, distillation, and multi-stage pipelines. Yet these methods are often discussed in fragmented ways, organized by labels or objective families rather than by the behavioral bottlenecks they address. This survey argues that LLM post-training is best understood as structured intervention on model behavior. We organize the field first by trajectory provenance, which defines two primary learning regimes: off-policy learning on externally supplied trajectories, and on-policy learning on learner-generated rollouts. We then interpret methods through two recurring roles -- effective support expansion, which makes useful behaviors more reachable, and policy reshaping, which improves behavior within already reachable regions -- together with a complementary systems-level role, behavioral consolidation, which preserves, transfers, and amortizes behavior across stages and model transitions. This perspective yields a unified reading of major paradigms. SFT may serve either support expansion or policy reshaping, whereas preference-based methods are usually off-policy reshaping. On-policy RL often improves behavior on learner-generated states, though under stronger guidance it can also make hard-to-reach reasoning paths reachable. Distillation is often best understood as consolidation rather than only compression, and hybrid pipelines emerge as coordinated multi-stage compositions. Overall, the framework helps diagnose post-training bottlenecks and reason about stage composition, suggesting that progress in LLM post-training increasingly depends on coordinated system design rather than any single dominant objective.
DIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
Jan 30, 2026Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.
Reflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
A data-driven approach to inferring travel trajectory during peak hours in urban rail transit systems
Dec 10, 2025Refined trajectory inference of urban rail transit is of great significance to the operation organization. In this paper, we develop a fully data-driven approach to inferring individual travel trajectories in urban rail transit systems. It utilizes data from the Automatic Fare Collection (AFC) and Automatic Vehicle Location (AVL) systems to infer key trajectory elements, such as selected train, access/egress time, and transfer time. The approach includes establishing train alternative sets based on spatio-temporal constraints, data-driven adaptive trajectory inference, and trave l trajectory construction. To realize data-driven adaptive trajectory inference, a data-driven parameter estimation method based on KL divergence combined with EM algorithm (KLEM) was proposed. This method eliminates the reliance on external or survey data for parameter fitting, enhancing the robustness and applicability of the model. Furthermore, to overcome the limitations of using synthetic data to validate the result, this paper employs real individual travel trajectory data for verification. The results show that the approach developed in this paper can achieve high-precision passenger trajectory inference, with an accuracy rate of over 90% in urban rail transit travel trajectory inference during peak hours.
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025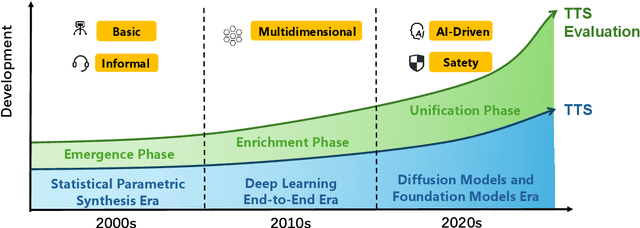


Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.
Mind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
Sep 18, 2025Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to high variance and training instability. Existing approaches mitigate this issue using KL penalties or clipping, which passively constrain updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap by keeping correct solutions as on-policy data and rewriting incorrect ones with guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy before optimization, reducing importance sampling variance and stabilizing off-policy fine-tuning. Experiments on five mathematical reasoning benchmarks demonstrate consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. The data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
RA-CLAP: Relation-Augmented Emotional Speaking Style Contrastive Language-Audio Pretraining For Speech Retrieval
May 26, 2025The Contrastive Language-Audio Pretraining (CLAP) model has demonstrated excellent performance in general audio description-related tasks, such as audio retrieval. However, in the emerging field of emotional speaking style description (ESSD), cross-modal contrastive pretraining remains largely unexplored. In this paper, we propose a novel speech retrieval task called emotional speaking style retrieval (ESSR), and ESS-CLAP, an emotional speaking style CLAP model tailored for learning relationship between speech and natural language descriptions. In addition, we further propose relation-augmented CLAP (RA-CLAP) to address the limitation of traditional methods that assume a strict binary relationship between caption and audio. The model leverages self-distillation to learn the potential local matching relationships between speech and descriptions, thereby enhancing generalization ability. The experimental results validate the effectiveness of RA-CLAP, providing valuable reference in ESSD.
Chinese-LiPS: A Chinese audio-visual speech recognition dataset with Lip-reading and Presentation Slides
Apr 21, 2025Incorporating visual modalities to assist Automatic Speech Recognition (ASR) tasks has led to significant improvements. However, existing Audio-Visual Speech Recognition (AVSR) datasets and methods typically rely solely on lip-reading information or speaking contextual video, neglecting the potential of combining these different valuable visual cues within the speaking context. In this paper, we release a multimodal Chinese AVSR dataset, Chinese-LiPS, comprising 100 hours of speech, video, and corresponding manual transcription, with the visual modality encompassing both lip-reading information and the presentation slides used by the speaker. Based on Chinese-LiPS, we develop a simple yet effective pipeline, LiPS-AVSR, which leverages both lip-reading and presentation slide information as visual modalities for AVSR tasks. Experiments show that lip-reading and presentation slide information improve ASR performance by approximately 8\% and 25\%, respectively, with a combined performance improvement of about 35\%. The dataset is available at https://kiri0824.github.io/Chinese-LiPS/
SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors
Mar 20, 2025While voice technologies increasingly serve aging populations, current systems exhibit significant performance gaps due to inadequate training data capturing elderly-specific vocal characteristics like presbyphonia and dialectal variations. The limited data available on super-aged individuals in existing elderly speech datasets, coupled with overly simple recording styles and annotation dimensions, exacerbates this issue. To address the critical scarcity of speech data from individuals aged 75 and above, we introduce SeniorTalk, a carefully annotated Chinese spoken dialogue dataset. This dataset contains 55.53 hours of speech from 101 natural conversations involving 202 participants, ensuring a strategic balance across gender, region, and age. Through detailed annotation across multiple dimensions, it can support a wide range of speech tasks. We perform extensive experiments on speaker verification, speaker diarization, speech recognition, and speech editing tasks, offering crucial insights for the development of speech technologies targeting this age group.