 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJD-BP: A Joint-Decision Generative Framework for Auto-Bidding and Pricing
Apr 07, 2026Auto-bidding services optimize real-time bidding strategies for advertisers under key performance indicator (KPI) constraints such as target return on investment and budget. However, uncertainties such as model prediction errors and feedback latency can cause bidding strategies to deviate from ex-post optimality, leading to inefficient allocation. To address this issue, we propose JD-BP, a Joint generative Decision framework for Bidding and Pricing. Unlike prior methods, JD-BP jointly outputs a bid value and a pricing correction term that acts additively with the payment rule such as GSP. To mitigate adverse effects of historical constraint violations, we design a memory-less Return-to-Go that encourages future value maximizing of bidding actions while the cumulated bias is handled by the pricing correction. Moreover, a trajectory augmentation algorithm is proposed to generate joint bidding-pricing trajectories from a (possibly arbitrary) base bidding policy, enabling efficient plug-and-play deployment of our algorithm from existing RL/generative bidding models. Finally, we employ an Energy-Based Direct Preference Optimization method in conjunction with a cross-attention module to enhance the joint learning performance of bidding and pricing correction. Offline experiments on the AuctionNet dataset demonstrate that JD-BP achieves state-of-the-art performance. Online A/B tests at JD.com confirm its practical effectiveness, showing a 4.70% increase in ad revenue and a 6.48% improvement in target cost.
$Δ$VLA: Prior-Guided Vision-Language-Action Models via World Knowledge Variation
Mar 09, 2026Recent vision-language-action (VLA) models have significantly advanced robotic manipulation by unifying perception, reasoning, and control. To achieve such integration, recent studies adopt a predictive paradigm that models future visual states or world knowledge to guide action generation. However, these models emphasize forecasting outcomes rather than reasoning about the underlying process of change, which is essential for determining how to act. To address this, we propose $Δ$VLA, a prior-guided framework that models world-knowledge variations relative to an explicit current-world knowledge prior for action generation, rather than regressing absolute future world states. Specifically, 1) to construct the current world knowledge prior, we propose the Prior-Guided WorldKnowledge Extractor (PWKE). It extracts manipulable regions, spatial relations, and semantic cues from the visual input, guided by auxiliary heads and prior pseudo labels, thus reducing redundancy. 2) Building upon this, to represent how world knowledge evolves under actions, we introduce the Latent World Variation Quantization (LWVQ). It learns a discrete latent space via a VQ-VAE objective to encode world knowledge variations, shifting prediction from full modalities to compact latent. 3)Moreover, to mitigate interference during variation modeling, we design the Conditional Variation Attention (CV-Atten), whichpromotes disentangled learning and preserves the independence of knowledge representations. Extensive experiments on both simulated benchmarks and real-world robotic tasks demonstrate $Δ$VLA achieves state-of-the-art performance while improving efficiency. Code and real-world execution videos are available at https://github.com/JiuTian-VL/DeltaVLA.
A data-driven approach to inferring travel trajectory during peak hours in urban rail transit systems
Dec 10, 2025Refined trajectory inference of urban rail transit is of great significance to the operation organization. In this paper, we develop a fully data-driven approach to inferring individual travel trajectories in urban rail transit systems. It utilizes data from the Automatic Fare Collection (AFC) and Automatic Vehicle Location (AVL) systems to infer key trajectory elements, such as selected train, access/egress time, and transfer time. The approach includes establishing train alternative sets based on spatio-temporal constraints, data-driven adaptive trajectory inference, and trave l trajectory construction. To realize data-driven adaptive trajectory inference, a data-driven parameter estimation method based on KL divergence combined with EM algorithm (KLEM) was proposed. This method eliminates the reliance on external or survey data for parameter fitting, enhancing the robustness and applicability of the model. Furthermore, to overcome the limitations of using synthetic data to validate the result, this paper employs real individual travel trajectory data for verification. The results show that the approach developed in this paper can achieve high-precision passenger trajectory inference, with an accuracy rate of over 90% in urban rail transit travel trajectory inference during peak hours.
CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
Aug 28, 2025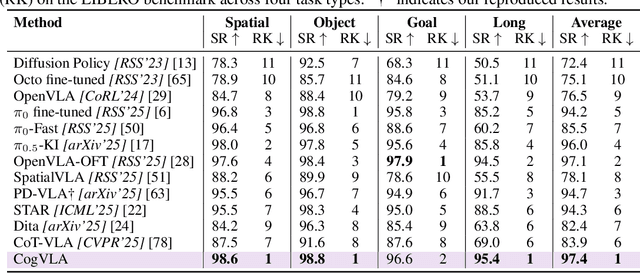
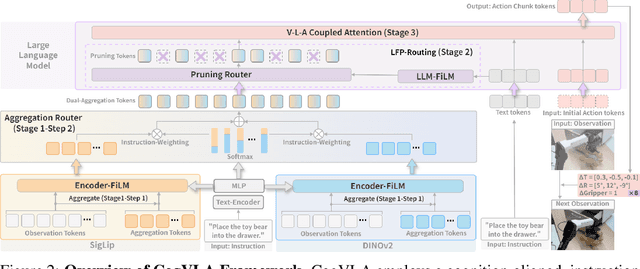
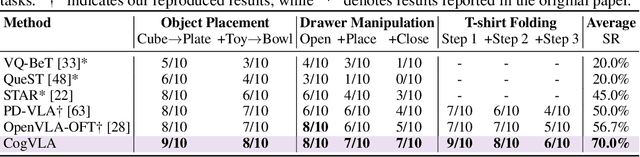
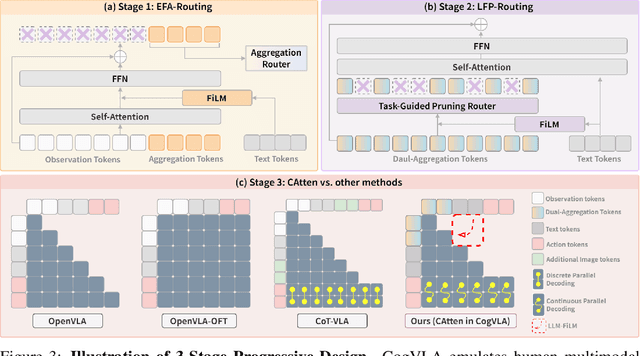
Recent Vision-Language-Action (VLA) models built on pre-trained Vision-Language Models (VLMs) require extensive post-training, resulting in high computational overhead that limits scalability and deployment.We propose CogVLA, a Cognition-Aligned Vision-Language-Action framework that leverages instruction-driven routing and sparsification to improve both efficiency and performance. CogVLA draws inspiration from human multimodal coordination and introduces a 3-stage progressive architecture. 1) Encoder-FiLM based Aggregation Routing (EFA-Routing) injects instruction information into the vision encoder to selectively aggregate and compress dual-stream visual tokens, forming a instruction-aware latent representation. 2) Building upon this compact visual encoding, LLM-FiLM based Pruning Routing (LFP-Routing) introduces action intent into the language model by pruning instruction-irrelevant visually grounded tokens, thereby achieving token-level sparsity. 3) To ensure that compressed perception inputs can still support accurate and coherent action generation, we introduce V-L-A Coupled Attention (CAtten), which combines causal vision-language attention with bidirectional action parallel decoding. Extensive experiments on the LIBERO benchmark and real-world robotic tasks demonstrate that CogVLA achieves state-of-the-art performance with success rates of 97.4% and 70.0%, respectively, while reducing training costs by 2.5-fold and decreasing inference latency by 2.8-fold compared to OpenVLA. CogVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/CogVLA.
From Sufficiency to Reflection: Reinforcement-Guided Thinking Quality in Retrieval-Augmented Reasoning for LLMs
Jul 30, 2025Reinforcement learning-based retrieval-augmented generation (RAG) methods enhance the reasoning abilities of large language models (LLMs). However, most rely only on final-answer rewards, overlooking intermediate reasoning quality. This paper analyzes existing RAG reasoning models and identifies three main failure patterns: (1) information insufficiency, meaning the model fails to retrieve adequate support; (2) faulty reasoning, where logical or content-level flaws appear despite sufficient information; and (3) answer-reasoning inconsistency, where a valid reasoning chain leads to a mismatched final answer. We propose TIRESRAG-R1, a novel framework using a think-retrieve-reflect process and a multi-dimensional reward system to improve reasoning and stability. TIRESRAG-R1 introduces: (1) a sufficiency reward to encourage thorough retrieval; (2) a reasoning quality reward to assess the rationality and accuracy of the reasoning chain; and (3) a reflection reward to detect and revise errors. It also employs a difficulty-aware reweighting strategy and training sample filtering to boost performance on complex tasks. Experiments on four multi-hop QA datasets show that TIRESRAG-R1 outperforms prior RAG methods and generalizes well to single-hop tasks. The code and data are available at: https://github.com/probe2/TIRESRAG-R1.
FAMSeg: Fetal Femur and Cranial Ultrasound Segmentation Using Feature-Aware Attention and Mamba Enhancement
Jun 09, 2025Accurate ultrasound image segmentation is a prerequisite for precise biometrics and accurate assessment. Relying on manual delineation introduces significant errors and is time-consuming. However, existing segmentation models are designed based on objects in natural scenes, making them difficult to adapt to ultrasound objects with high noise and high similarity. This is particularly evident in small object segmentation, where a pronounced jagged effect occurs. Therefore, this paper proposes a fetal femur and cranial ultrasound image segmentation model based on feature perception and Mamba enhancement to address these challenges. Specifically, a longitudinal and transverse independent viewpoint scanning convolution block and a feature perception module were designed to enhance the ability to capture local detail information and improve the fusion of contextual information. Combined with the Mamba-optimized residual structure, this design suppresses the interference of raw noise and enhances local multi-dimensional scanning. The system builds global information and local feature dependencies, and is trained with a combination of different optimizers to achieve the optimal solution. After extensive experimental validation, the FAMSeg network achieved the fastest loss reduction and the best segmentation performance across images of varying sizes and orientations.
FPDANet: A Multi-Section Classification Model for Intelligent Screening of Fetal Ultrasound
Jun 06, 2025ResNet has been widely used in image classification tasks due to its ability to model the residual dependence of constant mappings for linear computation. However, the ResNet method adopts a unidirectional transfer of features and lacks an effective method to correlate contextual information, which is not effective in classifying fetal ultrasound images in the classification task, and fetal ultrasound images have problems such as low contrast, high similarity, and high noise. Therefore, we propose a bilateral multi-scale information fusion network-based FPDANet to address the above challenges. Specifically, we design the positional attention mechanism (DAN) module, which utilizes the similarity of features to establish the dependency of different spatial positional features and enhance the feature representation. In addition, we design a bilateral multi-scale (FPAN) information fusion module to capture contextual and global feature dependencies at different feature scales, thereby further improving the model representation. FPDANet classification results obtained 91.05\% and 100\% in Top-1 and Top-5 metrics, respectively, and the experimental results proved the effectiveness and robustness of FPDANet.
N2C2: Nearest Neighbor Enhanced Confidence Calibration for Cross-Lingual In-Context Learning
Mar 12, 2025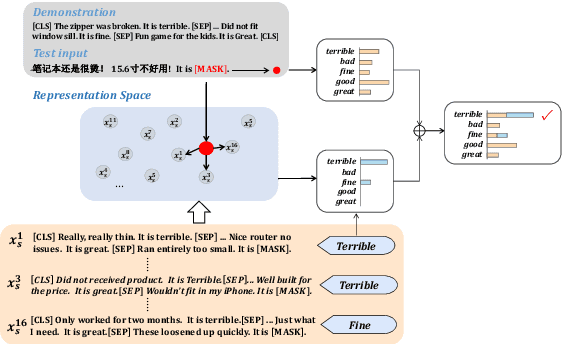
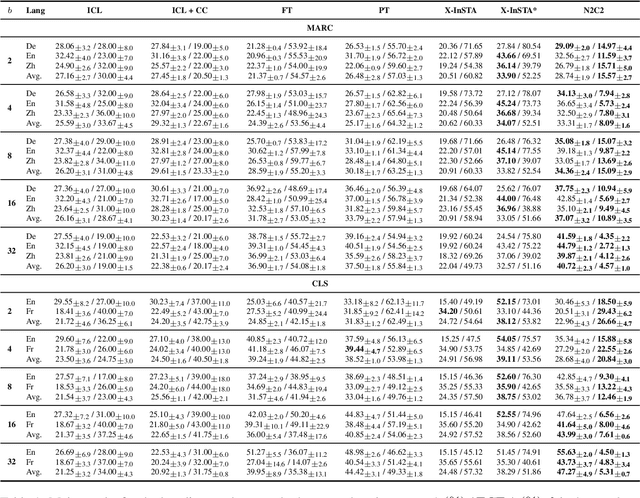
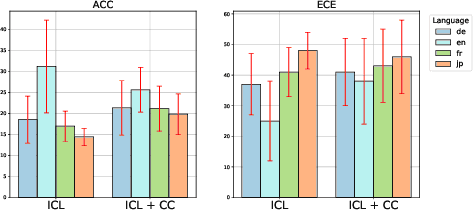
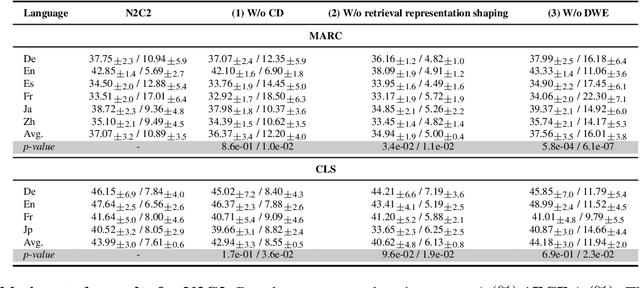
Recent advancements of in-context learning (ICL) show language models can significantly improve their performance when demonstrations are provided. However, little attention has been paid to model calibration and prediction confidence of ICL in cross-lingual scenarios. To bridge this gap, we conduct a thorough analysis of ICL for cross-lingual sentiment classification. Our findings suggest that ICL performs poorly in cross-lingual scenarios, exhibiting low accuracy and presenting high calibration errors. In response, we propose a novel approach, N2C2, which employs a -nearest neighbors augmented classifier for prediction confidence calibration. N2C2 narrows the prediction gap by leveraging a datastore of cached few-shot instances. Specifically, N2C2 integrates the predictions from the datastore and incorporates confidence-aware distribution, semantically consistent retrieval representation, and adaptive neighbor combination modules to effectively utilize the limited number of supporting instances. Evaluation on two multilingual sentiment classification datasets demonstrates that N2C2 outperforms traditional ICL. It surpasses fine tuning, prompt tuning and recent state-of-the-art methods in terms of accuracy and calibration errors.
MetaXCR: Reinforcement-Based Meta-Transfer Learning for Cross-Lingual Commonsense Reasoning
Mar 09, 2025
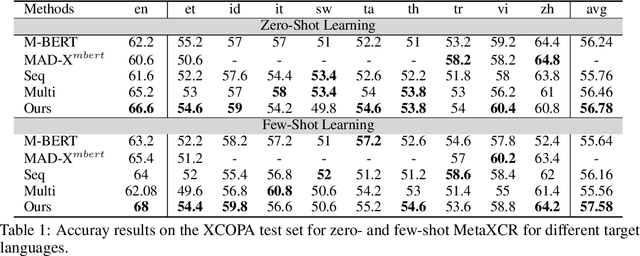

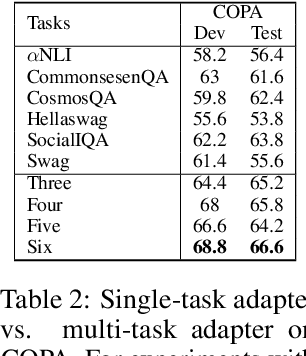
Commonsense reasoning (CR) has been studied in many pieces of domain and has achieved great progress with the aid of large datasets. Unfortunately, most existing CR datasets are built in English, so most previous work focus on English. Furthermore, as the annotation of commonsense reasoning is costly, it is impossible to build a large dataset for every novel task. Therefore, there are growing appeals for Cross-lingual Low-Resource Commonsense Reasoning, which aims to leverage diverse existed English datasets to help the model adapt to new cross-lingual target datasets with limited labeled data. In this paper, we propose a multi-source adapter for cross-lingual low-resource Commonsense Reasoning (MetaXCR). In this framework, we first extend meta learning by incorporating multiple training datasets to learn a generalized task adapters across different tasks. Then, we further introduce a reinforcement-based sampling strategy to help the model sample the source task that is the most helpful to the target task. Finally, we introduce two types of cross-lingual meta-adaption methods to enhance the performance of models on target languages. Extensive experiments demonstrate MetaXCR is superior over state-of-the-arts, while being trained with fewer parameters than other work.
Evaluating Discourse Cohesion in Pre-trained Language Models
Mar 08, 2025
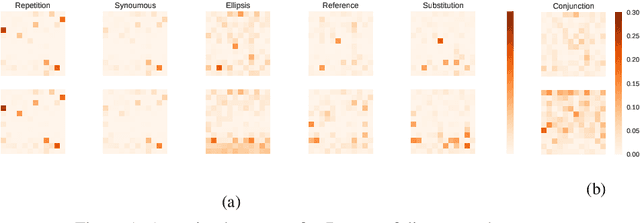
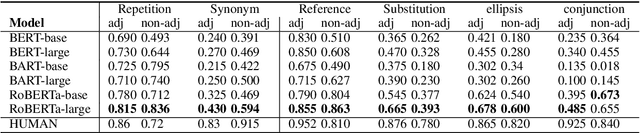

Large pre-trained neural models have achieved remarkable success in natural language process (NLP), inspiring a growing body of research analyzing their ability from different aspects. In this paper, we propose a test suite to evaluate the cohesive ability of pre-trained language models. The test suite contains multiple cohesion phenomena between adjacent and non-adjacent sentences. We try to compare different pre-trained language models on these phenomena and analyze the experimental results,hoping more attention can be given to discourse cohesion in the future.