 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
Beyond Output Critique: Self-Correction via Task Distillation
Jan 31, 2026Large language models (LLMs) have shown promising self-correction abilities, where iterative refinement improves the quality of generated responses. However, most existing approaches operate at the level of output critique, patching surface errors while often failing to correct deeper reasoning flaws. We propose SELF-THOUGHT, a framework that introduces an intermediate step of task abstraction before solution refinement. Given an input and an initial response, the model first distills the task into a structured template that captures key variables, constraints, and problem structure. This abstraction then guides solution instantiation, grounding subsequent responses in a clearer understanding of the task and reducing error propagation. Crucially, we show that these abstractions can be transferred across models: templates generated by larger models can serve as structured guides for smaller LLMs, which typically struggle with intrinsic self-correction. By reusing distilled task structures, smaller models achieve more reliable refinements without heavy fine-tuning or reliance on external verifiers. Experiments across diverse reasoning tasks demonstrate that SELF-THOUGHT improves accuracy, robustness, and generalization for both large and small models, offering a scalable path toward more reliable self-correcting language systems.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
Learning Human-Humanoid Coordination for Collaborative Object Carrying
Oct 16, 2025Human-humanoid collaboration shows significant promise for applications in healthcare, domestic assistance, and manufacturing. While compliant robot-human collaboration has been extensively developed for robotic arms, enabling compliant human-humanoid collaboration remains largely unexplored due to humanoids' complex whole-body dynamics. In this paper, we propose a proprioception-only reinforcement learning approach, COLA, that combines leader and follower behaviors within a single policy. The model is trained in a closed-loop environment with dynamic object interactions to predict object motion patterns and human intentions implicitly, enabling compliant collaboration to maintain load balance through coordinated trajectory planning. We evaluate our approach through comprehensive simulator and real-world experiments on collaborative carrying tasks, demonstrating the effectiveness, generalization, and robustness of our model across various terrains and objects. Simulation experiments demonstrate that our model reduces human effort by 24.7%. compared to baseline approaches while maintaining object stability. Real-world experiments validate robust collaborative carrying across different object types (boxes, desks, stretchers, etc.) and movement patterns (straight-line, turning, slope climbing). Human user studies with 23 participants confirm an average improvement of 27.4% compared to baseline models. Our method enables compliant human-humanoid collaborative carrying without requiring external sensors or complex interaction models, offering a practical solution for real-world deployment.
Skeleton-based sign language recognition using a dual-stream spatio-temporal dynamic graph convolutional network
Sep 10, 2025Isolated Sign Language Recognition (ISLR) is challenged by gestures that are morphologically similar yet semantically distinct, a problem rooted in the complex interplay between hand shape and motion trajectory. Existing methods, often relying on a single reference frame, struggle to resolve this geometric ambiguity. This paper introduces Dual-SignLanguageNet (DSLNet), a dual-reference, dual-stream architecture that decouples and models gesture morphology and trajectory in separate, complementary coordinate systems. Our approach utilizes a wrist-centric frame for view-invariant shape analysis and a facial-centric frame for context-aware trajectory modeling. These streams are processed by specialized networks-a topology-aware graph convolution for shape and a Finsler geometry-based encoder for trajectory-and are integrated via a geometry-driven optimal transport fusion mechanism. DSLNet sets a new state-of-the-art, achieving 93.70%, 89.97% and 99.79% accuracy on the challenging WLASL-100, WLASL-300 and LSA64 datasets, respectively, with significantly fewer parameters than competing models.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation
Feb 26, 2025Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
MaxMI: A Maximal Mutual Information Criterion for Manipulation Concept Discovery
Jul 21, 2024
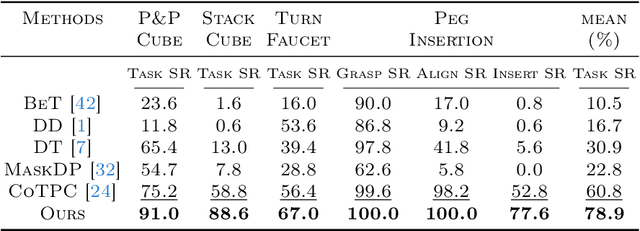
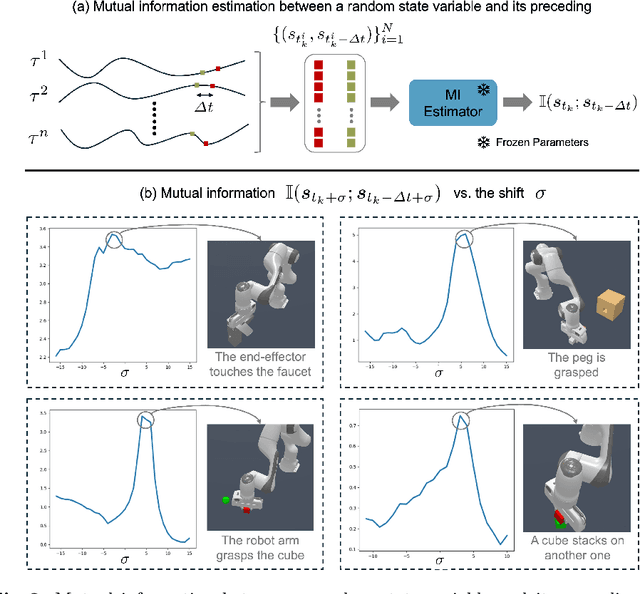
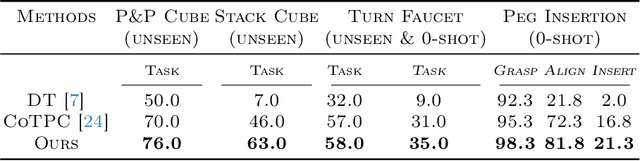
We aim to discover manipulation concepts embedded in the unannotated demonstrations, which are recognized as key physical states. The discovered concepts can facilitate training manipulation policies and promote generalization. Current methods relying on multimodal foundation models for deriving key states usually lack accuracy and semantic consistency due to limited multimodal robot data. In contrast, we introduce an information-theoretic criterion to characterize the regularities that signify a set of physical states. We also develop a framework that trains a concept discovery network using this criterion, thus bypassing the dependence on human semantics and alleviating costly human labeling. The proposed criterion is based on the observation that key states, which deserve to be conceptualized, often admit more physical constraints than non-key states. This phenomenon can be formalized as maximizing the mutual information between the putative key state and its preceding state, i.e., Maximal Mutual Information (MaxMI). By employing MaxMI, the trained key state localization network can accurately identify states of sufficient physical significance, exhibiting reasonable semantic compatibility with human perception. Furthermore, the proposed framework produces key states that lead to concept-guided manipulation policies with higher success rates and better generalization in various robotic tasks compared to the baselines, verifying the effectiveness of the proposed criterion.
InterIntent: Investigating Social Intelligence of LLMs via Intention Understanding in an Interactive Game Context
Jun 18, 2024Large language models (LLMs) have demonstrated the potential to mimic human social intelligence. However, most studies focus on simplistic and static self-report or performance-based tests, which limits the depth and validity of the analysis. In this paper, we developed a novel framework, InterIntent, to assess LLMs' social intelligence by mapping their ability to understand and manage intentions in a game setting. We focus on four dimensions of social intelligence: situational awareness, self-regulation, self-awareness, and theory of mind. Each dimension is linked to a specific game task: intention selection, intention following, intention summarization, and intention guessing. Our findings indicate that while LLMs exhibit high proficiency in selecting intentions, achieving an accuracy of 88\%, their ability to infer the intentions of others is significantly weaker, trailing human performance by 20\%. Additionally, game performance correlates with intention understanding, highlighting the importance of the four components towards success in this game. These findings underline the crucial role of intention understanding in evaluating LLMs' social intelligence and highlight the potential of using social deduction games as a complex testbed to enhance LLM evaluation. InterIntent contributes a structured approach to bridging the evaluation gap in social intelligence within multiplayer games.